
k8s教程05-Deployment滚动更新程序
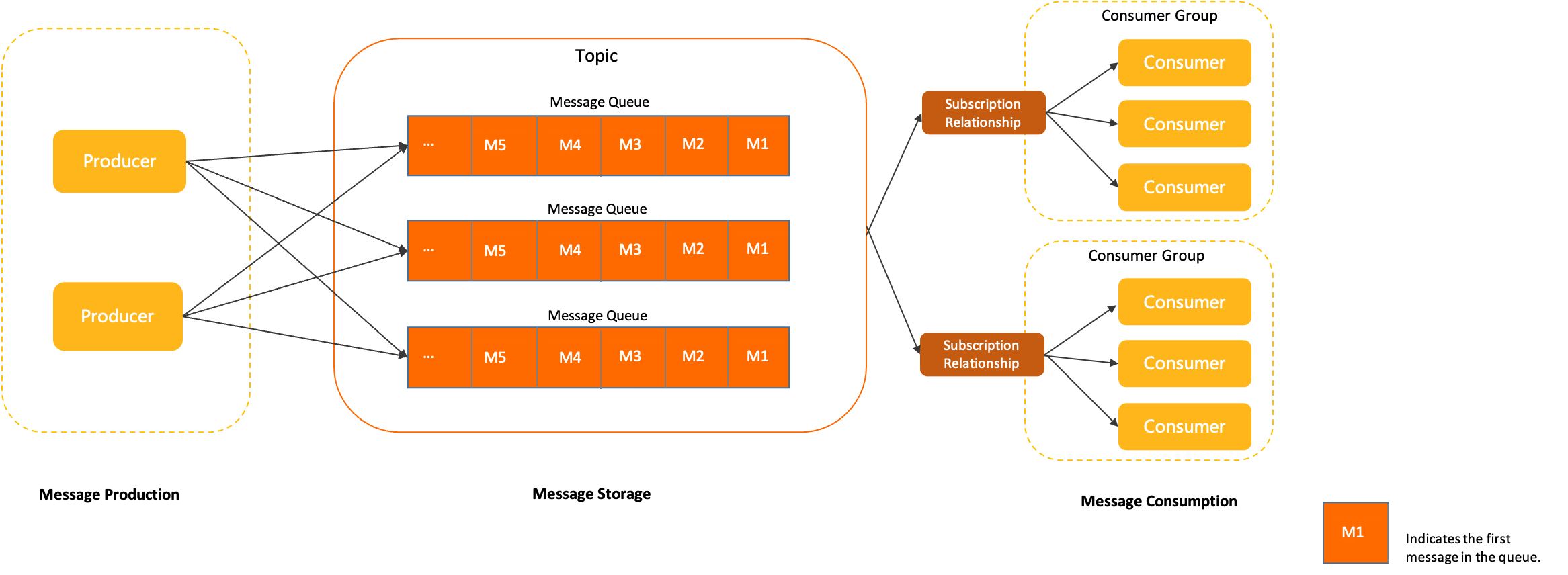
Deployment,⽀持声明式地更新应⽤程序。
- Deployment是⼀种更⾼阶资源,⽤于部署应⽤程序并以声明的⽅式升级应⽤,⽽不是通过ReplicationController或ReplicaSet进⾏部署,它们都被认为是更底层的概念。
- 当创建⼀个Deployment时,ReplicaSet资源也会随之创建 。
- 在使⽤ Deployment 时 , 实 际 的 pod 是 由Deployment 的Replicaset创建和管理的,⽽不是由Deployment直接创建和管理的。
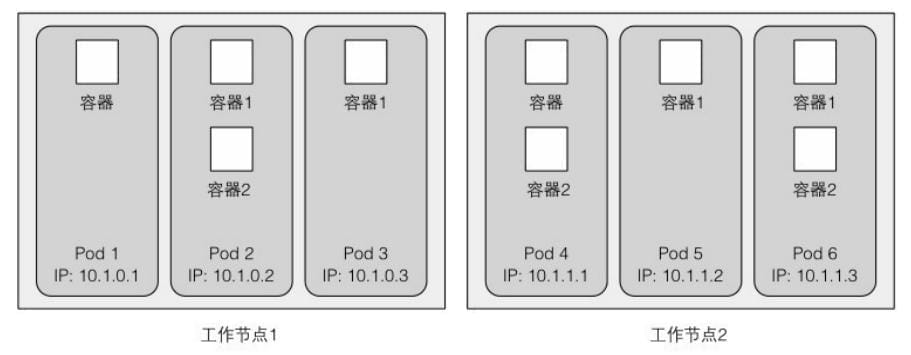
k8s教程01-架构和应用流程
Kubernetes是⼀个软件系统,它允许你在其上很容易地部署和管理容器化的应⽤,Kubernetes可以被当作集群的⼀个操作系统来看待。包括服务发现、扩容、负载均衡、⾃恢复,甚⾄领导者的选举。
k8s设计模式和容器标准
如果把 Kubernetes 比作云时代的操作系统,那容器就是操作系统中的进程。容器的本质是个特殊的进程,就是云时代的操作系统 Kubernetes 中的进程。
在一个真正的 os 内,进程并非“孤苦伶仃” 独自运行,而是以进程序,有原则的组织在一起。如 rsyslogd 程序负责 Linux 日志处理,rsyslogd 的主程序 main 以及它要用到的内核日志模块 imklog 同属于 2312 进程组。 而 Kubernetes 所做的,其实就是将“进程组”的概念映射到容器技术,并使其成为云原生操作系统“os”内的“一等公民”。
linux零拷贝技术讲解
磁盘可以说是计算机系统最慢的硬件之一,读写速度相差内存 10 倍以上,所以针对优化磁盘的技术非常的多,比如零拷贝、直接 I/O、异步 I/O 等等,这些优化的目的就是为了提高系统的吞吐量,另外操作系统内核中的磁盘高速缓存区,可以有效的减少磁盘的访问次数。