Go微服务实战07-评论和历史记录系统设计
1. 评论系统
1.1 架构设计
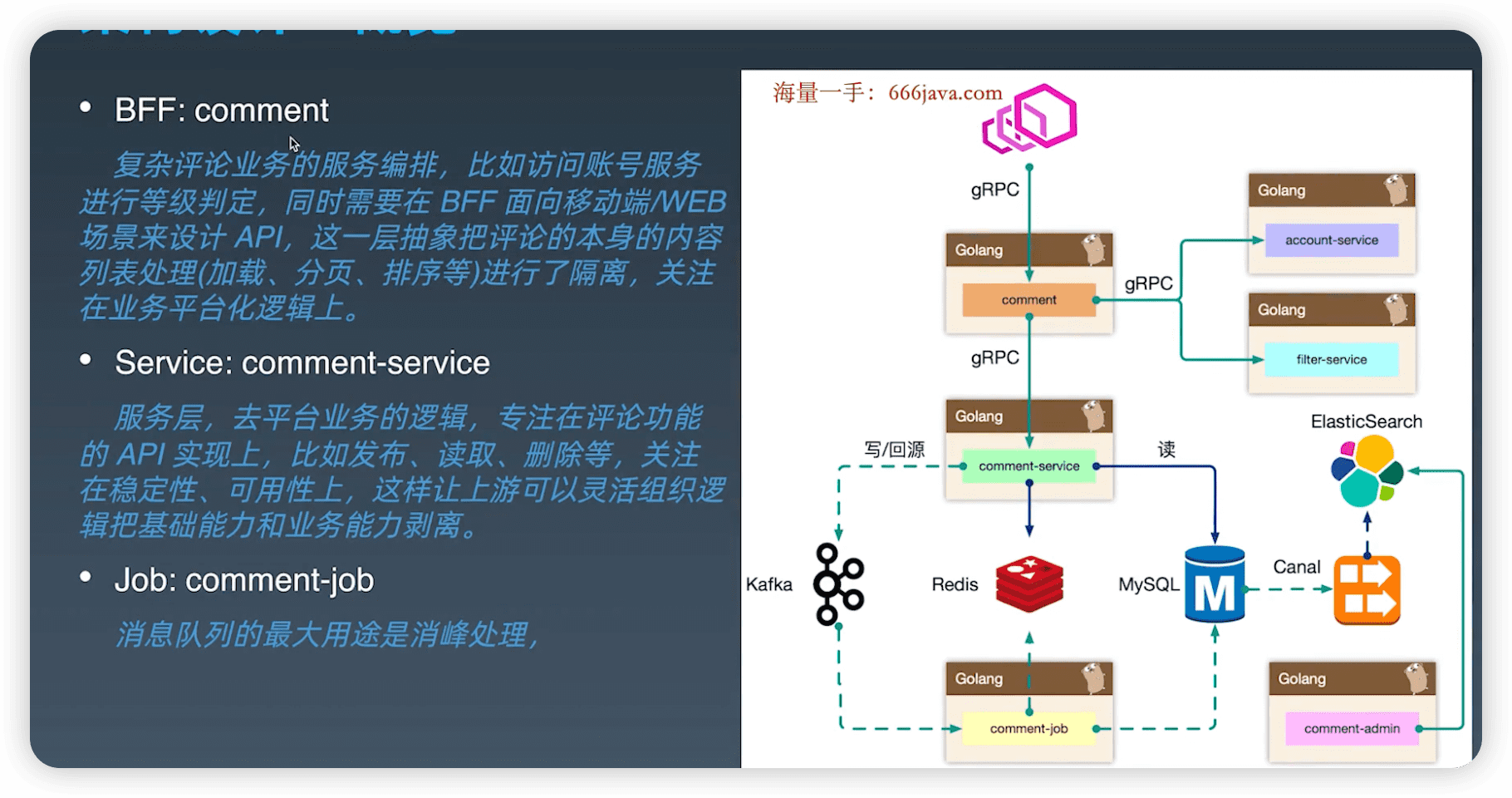
- bff层:评论业务的服务编排,策略逻辑。
- service层:只关注评论场景自己的逻辑。因为读写是稳定的,策略是多变的。
- admin 层:划分出管理平台,共享存储数据。接口安全性更高,独立出来。不会依赖原始数据库,冗余出es里。
- dependen层:依赖账号,过滤服务等。
架构设计等同于数据设计,梳理清楚数据的走向和逻辑。尽量避免环形依赖、数据双向请求等。
1.2 comment service
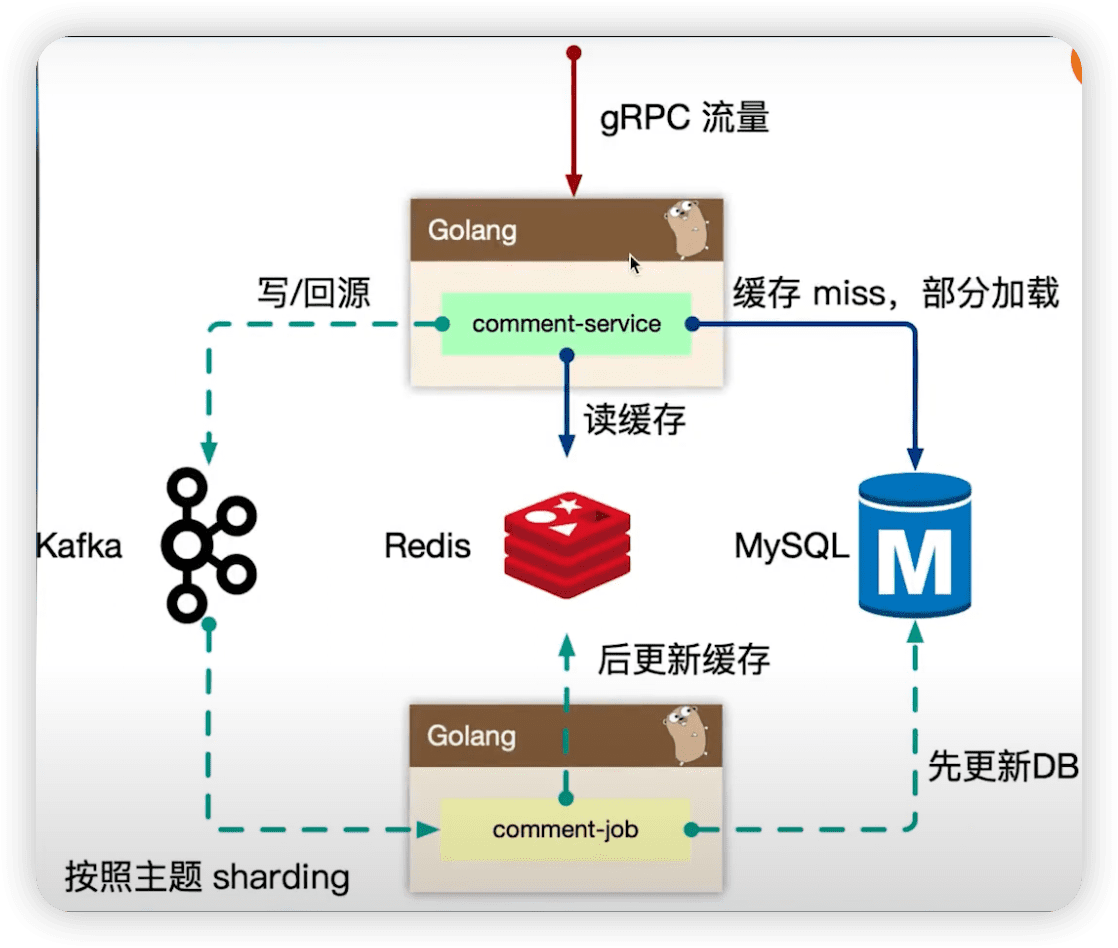
- cache miss 后,异步回源(防止进程oom)。就是写到数据库后,不写redis,发送kafka事件,再去异步写redis。
- 写操作一定会透传到存储层,瓶颈一般在存储层。把压力先给到kafka。
1.3 admin service
mysql binlog中的数据被canal中间件流式消费获取到业务的原始CRUD操作,需要回放录入到es中。
canal 中间件是模拟mysql 的 slave。
但是es中的数据最终是面向运营体系提供服务能力,需要检索的数据维度比较多,在入es 前需要做一个异构的joiner,把单表变宽预处理好 join逻辑,然后倒入到es中。
操作的时候,可能还会操作数据库。例如审核评论,删除评论。
1.4 存储设计
index表和content表分离,可以加快io,方便key value数据迁移。
如果缓存miss了,归并回源的思路。
可以使用 sync.sigleflight,同一时间只有一个人干活,其他人共享返回的数据。
kafka可能有重复cache miss信息,可以先查redis是否有了,没有再去查询mysql构建。
热点数据 localcace。
2. 历史记录系统
2.1 架构设计
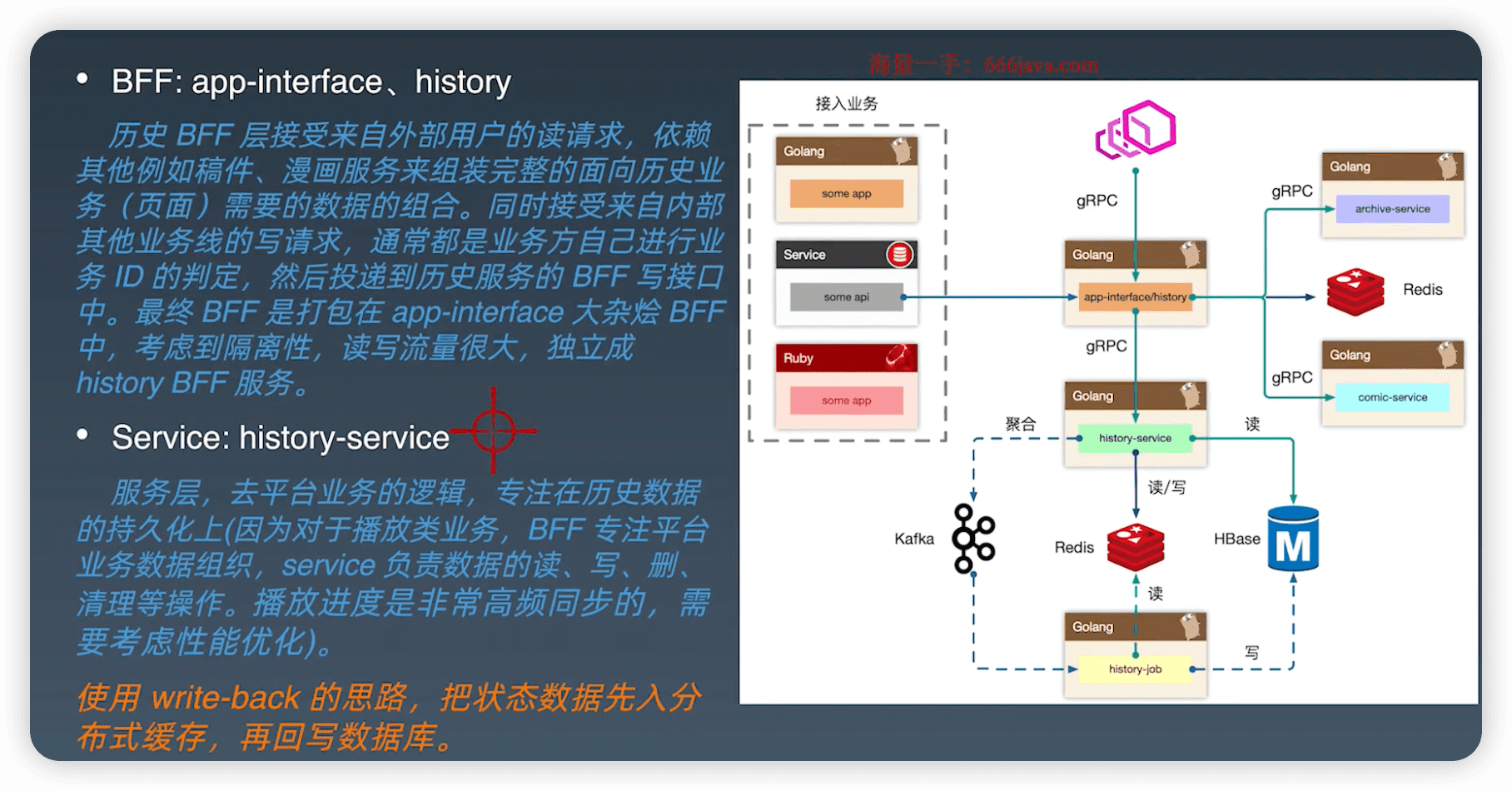
- 极高写入,write-back思路。
- 用redis临时存储,聚合打包给kafka。
- 利用消息队列的堆积能力,另外和kafka交互也聚合一下。
- 使用job消费kafka,消费redis,存到HBase。
2.1 history service
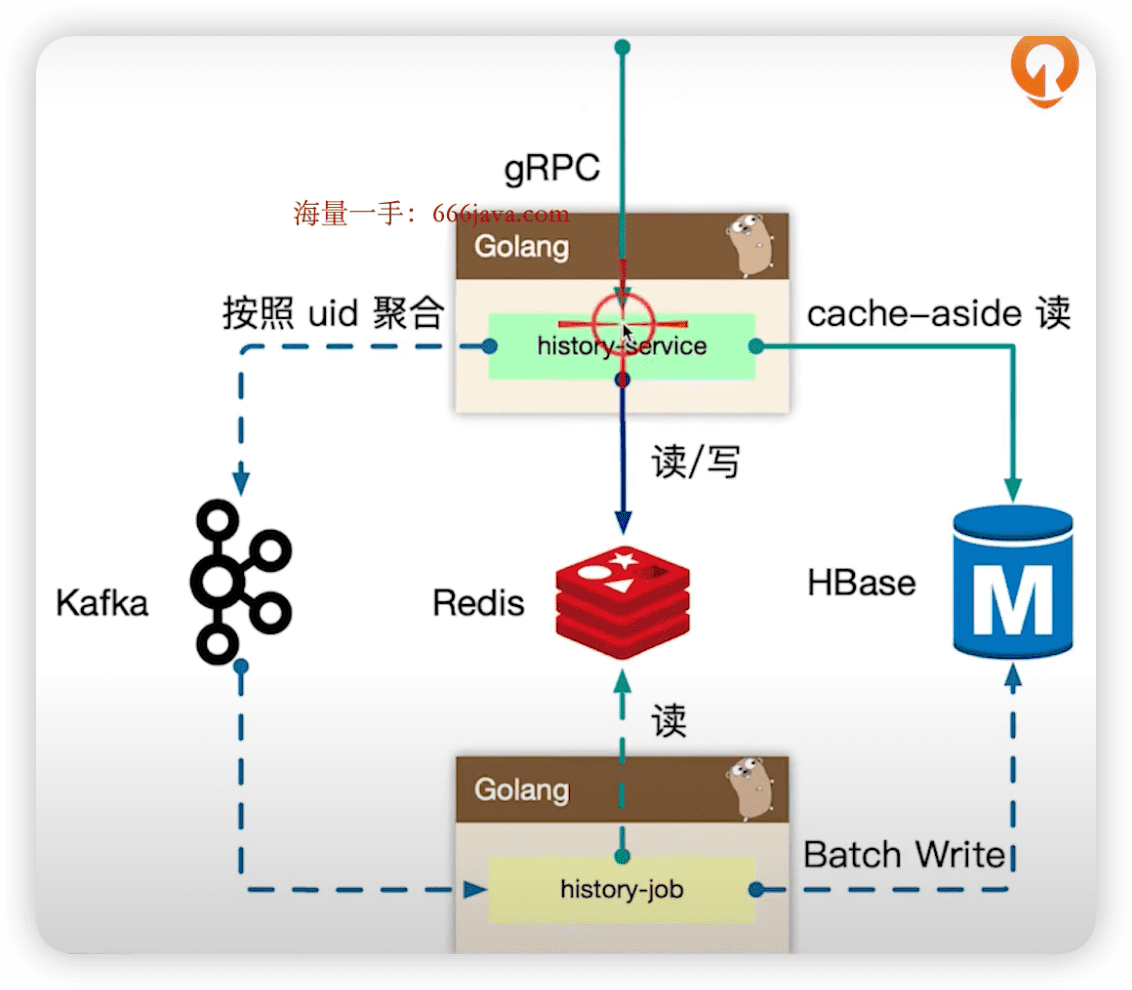
- 实时写入redis,在聚合前也提供给用户用,防止用户认为延时。会做斩断,最近的数据。
- 一堆用户打包放到同一个分区,region sharding,例如 uid % 100
2.3 存储设计
- 使用HBase,直接获取1000条,在内存中排序和翻页。
- 产生的新数据,立即写入到redis zset。
- 如果点查进度,只查redis,不查Hbase,因为命中率太低,做一定的取舍。
2.4 缓存设计
- 注意热点问题。如果全量用户都来呢,其实还是 prefix_key = hash(mid) % 1000
- 用 channel 聚合成一个大map,发送到下游 kafka 中。
- 前期激进一点1秒2秒4秒,后面每5秒上报。
2.5 聚合
- 请求聚合,bff聚合完,再请求下面的service层。
- 心跳服务对鉴权的服务的压力,内网使用 goim 服务维护长连接,一次鉴权。
3. 参考资料
- 《极客大学-Go进阶训练营》