Go微服务实战06-服务高可用设计方案
1. 隔离
隔离,本质上是对系统或资源进行分割,从而实现当系统发生故障时能限定传播范围和影响范围即发生故障后只有出问题的服务不可用,保证其他服务仍然可用。
1.1 服务隔离
- 动静隔离:CDN。
- 读写隔离:例如主从,Replicaset,CQRS (查询和命令分开),分库分表等。(例如可以设计加速统计表,订阅其他微服务事件)
1.2 轻重隔离
- 核心隔离:核心业务独立部署,非核心业务共享资源。
- 快慢隔离:例如 kafka 与其他中间件的结合。
- 热点隔离:热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的TopK数据,并对其访问进行缓存。
- 用户隔离:不同的用户可能有不同的级别,例如外部用户和管理员。
1.3 物理隔离
- 线程:常见的例子就是线程池,这个在 Golang 中一般不用过多考虑,runtime 已经帮我们管理好了。
- 进程:我们现在一般使用容器化服务,跑在 k8s 上这就是一种进程级别的隔离。
- 机房:我们目前在 K8s 的基础上做一些开发,常见的一种做法就是将我们的服务的不同副本尽量的分配在不同的可用区,实际上就是云厂商的不同机房,避免机房停电或者着火之类的影响。
- 集群:非常重要的服务我们可以部署多套,在物理上进行隔离,常见的有异地部署,也可能就部署在同一个区域。
2. 超时
只要进程不挂,超时,熔断,降级才会有效。
2.1 超时控制
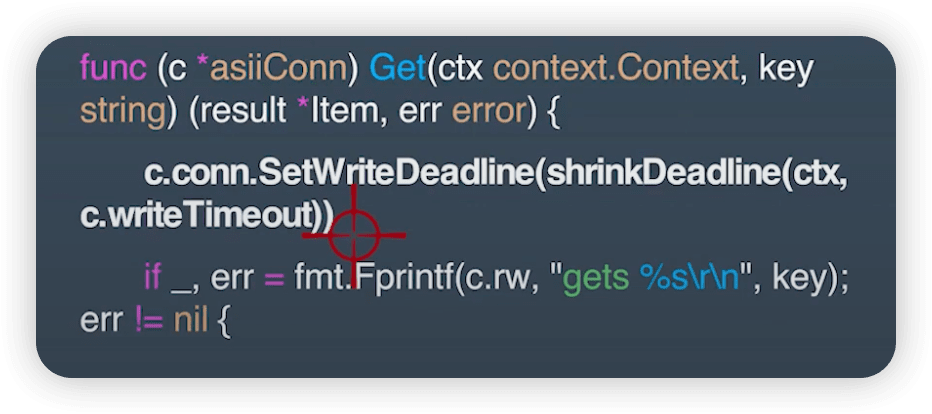
超时控制是微服务可用性的第一道关,良好的超时策略,可以尽可能让服务不堆积请求,尽快清空高延迟的请求,释放Goroutine。
超时控制,我们的组件能够快速失效(fail fast) 因为我们不希望等到断开的实例直到超时。
内网RPC(不超过100ms),用户响应(不超过 1s)
2.2 超时继承
上游已经504,下游还在继续。应该继承超时策略。
- 使用 context.WithTimeout()
- 使用 grpc 的 metadata 传递
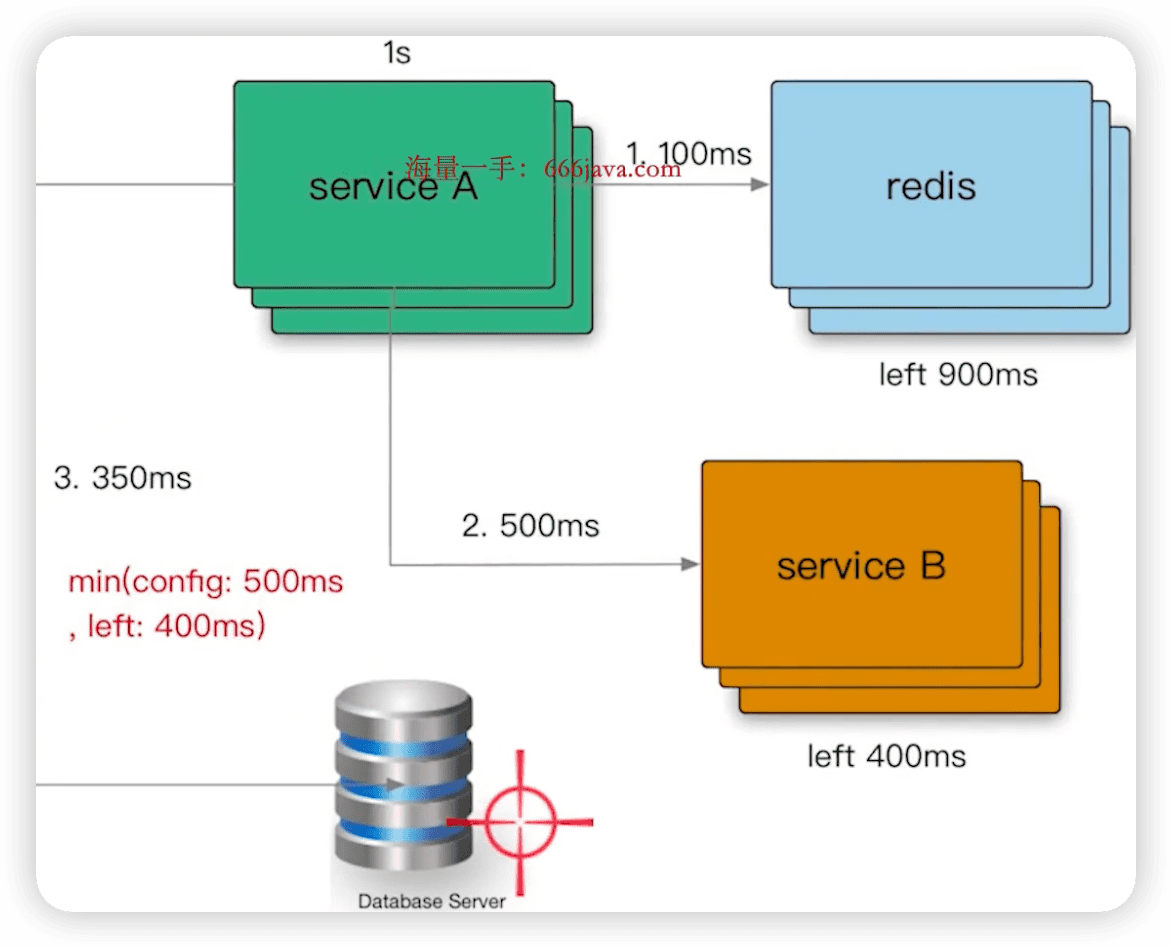
- 策略和剩余的,取出一个最小值。
3. 限流熔断
3.1 过载保护(动态流控)
计算系统临近过载时的峰值吞吐作为限流的阈值来进行流量控制,达到系统保护。
服务器临近过载时,主动抛弃一定量的负载,目标是自保。
在系统稳定的前提下,保持系统的吞吐量。
计算吞吐量常见做法:利特尔法则
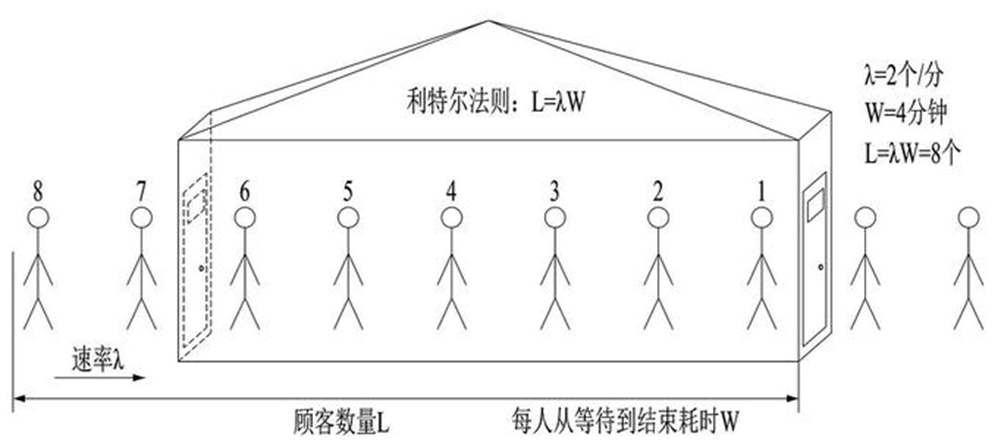
如果我们开一个小店,平均每分钟进店 2 个客人(λ),每位客人从等待到完成交易需要 4 分钟(W),那我们店里能承载的客人数量就是 2 * 4 = 8 个人。
同理,我们可以将 λ 当做 QPS, W 呢是每个请求需要花费的时间,那我们的系统的吞吐就是 L = λ * W ,所以我们可以使用利特尔法则来计算系统的吞吐量。
可以参考 BBR限流:https://github.com/go-kratos/aegis/blob/main/ratelimit/bbr/bbr.go
3.2 限流
令牌桶和漏洞算法
令牌桶和漏洞确实能够保护系统不被拖垮,但不管漏斗桶还是令牌桶,其防护思路都是设定一个指标,当超过该指标后就阻止或减少流量的继续进入,当系统负载降低到某一水平后则恢复流量的进入。
但其通常都是被动的,其实际效果取决于限流阈值设置是否合理,但往往设置合理不是一件容易的事情。
分布式限流
redis: 容易热点,对性能也有影响。
可以批量获取 quota(速率),减少访问redis的次数。
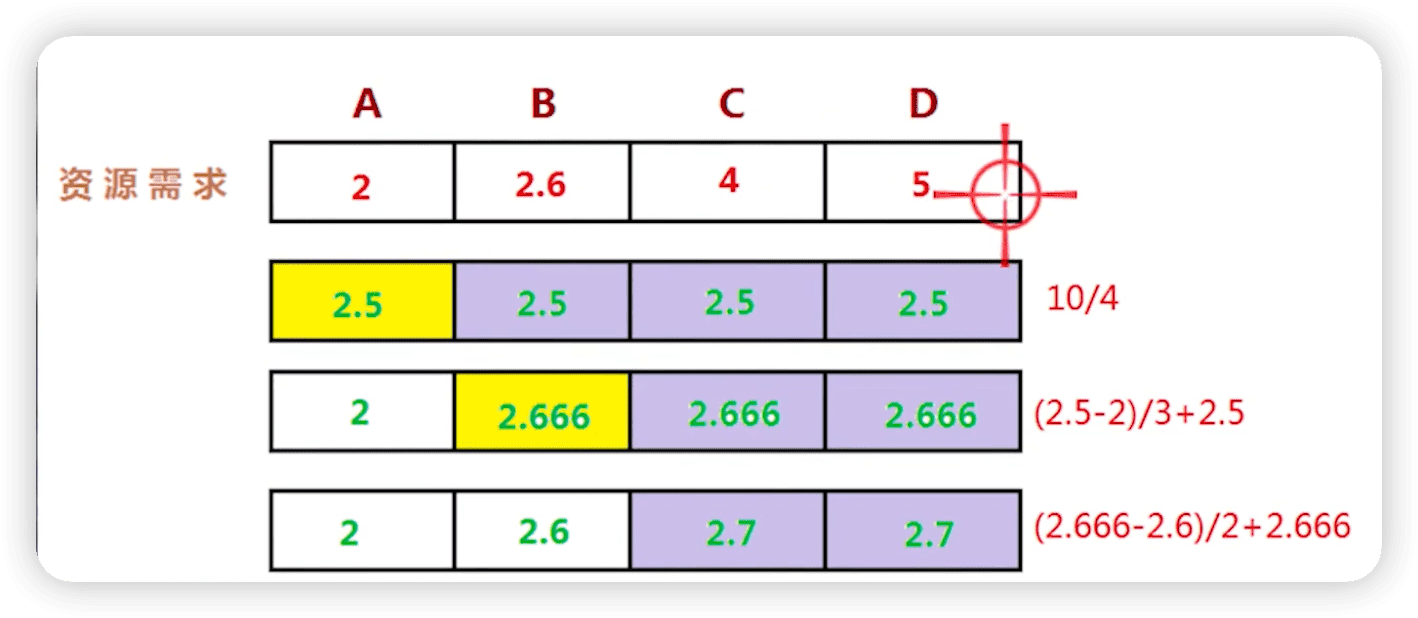
如何比较好的分配资源呢?策略:最大最小公平分享。
3.3 熔断
在服务端 client 侧做截流,也叫熔断。超时是服务端拒绝掉,熔断是client 端直接拒绝掉,防止请求下游。
断路器在分布式系统中非常有用,因为重复的故障可能会导致雪球效应,并使整个系统崩溃。
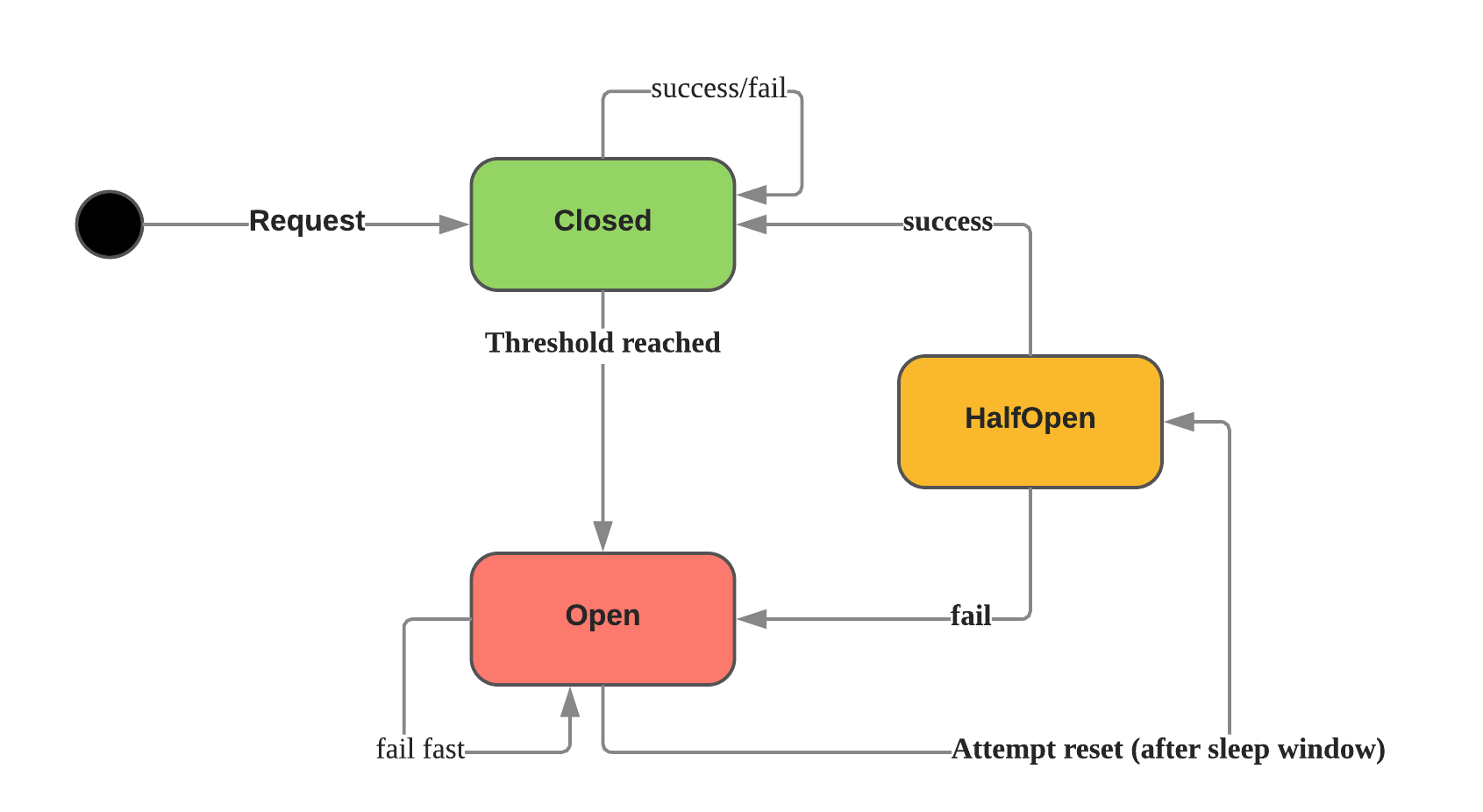
- 关闭(closed): 关闭状态下没有触发断路保护,所有的请求都正常通行
- 打开(open): 当错误阈值触发之后,就进入开启状态,这个时候所有的流量都会被节流,不运行通行
- 半打开(half-open): 处于打开状态一段时间之后,会尝试尝试放行一个流量来探测当前 server 端是否可以接收新流量,如果这个没有问题就会进入关闭状态,如果有问题又会回到打开状态
3.4 客户端流控
前端也最好做个限制,防止无限重试。客户端需要限制请求频次,retry backoff做一定的请求退让。
例如错误后,不可重复请求,或者累加时间请求。
4. 降级重试
4.1 降级
降级本质:提供有损服务,降级降的是服务自身。原则上在 bff 层做降级比较合适,底层不适合做。
- 降级的数据,一定和客户端商量好。
- 提供一些local cache,防止白屏。
- 例如页面降级,有点功能放弃。
自适应降级:
- cpu 是否过载。
- 最大并发数是否过载。
4.2 重试
- 要限制重试的次数,rpc 一般不能重试3次。
- 限制重试次数和基于重试分布的策略(重试比率:10%)。
- 只应该在失败的这层进行重试,要不然会产生级联重试风暴。例如约定503失败返回,504重试。
- 重试要考虑幂等性,写操作可能会麻烦一些。
5. 负载均衡
目标:
- 均衡的流量分发
- 可靠的识别异常节点。
- scale-out, 增加同质节点扩容。
- 减少错误,提高可用性。
p2c算法:
- 随机选取的两个节点进行打分。
- Grpc返回值把 cpu 信息带上。