Go微服务实战08-分布式缓存和分布式事务
1. 分布式缓存
1.1 中间件选型
- Redis 和 Memcache 最大的区别其实是 redis 单线程(新版本双线程),memcache 多线程,所以 QPS 可能两者差异不大,但是吞吐会有很大的差别,比如大数据 value 返回的时候,redis qps 会抖动下降的的很厉害,因为单线程工作,其他查询进不来(新版本有不少的改善)。
- 纯 kv 可以走 memcache,比如我们的关系链服务中用了 hashs 存储双向关系,但是我们也会使用 memcache 档一层来避免hgetall 导致的吞吐下降问题。 我们系统中多次使用 memcache + redis 双缓存设计。
1.2 缓存代理
twemproxy
单进程单线程模型 和 redis 类似,在处理一些大 key 的时候可能出现 io 瓶颈
- 参考nginx代码 改成了master worker
- 24core的吞吐量可以达到
二次开发成本难度高 c语言写的,难以于公司运维平台进行深度集成
不支持自动伸缩,不支持 autorebalance 增删节点需要重启才能生效;
运维不友好,没有控制面板
codis: 只支持 redis 协议,且需要使用 patch版本的 redis
mcrouter: 只支持 memcache 协议,C 开发,与运维集成开发难度高
目前建议直接用:redis-cluster。
1.3 缓存选型-hash
普通求余,改动很大。
一致性hash,一个大圆环。
Redis-cluster,分为16384个槽。一个节点负责一些槽的大范围。每个节点都知道哪个节点负责范围内的数据槽。
增加节点的时候,每个节点分享出去一些自己的槽位。
1.4 缓存模式-数据一致性
常规解决方案
1.同步操作DB;
2.同步操作Cache;
3.利用Job消费消息,重新补偿一次缓存操作
- 异步的队列 订阅binlog重新做回放
1.5 缓存模式-多级缓存
微服务拆分细粒度原子业务下的整合服务(聚合服务),用于提供粗粒度的接口,以及二级缓存加速,减少扇出的 rpc 网络请求,减少延迟。
最重要是保证多级缓存的一致性:
- 清理的优先级是有要求的,先优先清理下游再上游;
- 下游的缓存expire要大于上游,里面穿透回源;
- 天下大势分久必合,适当的微服务合并也是不错的做法,再使用 DDD 思路以及我们介绍的目录结构组织方式,区分不同的 Usecase。
1.6 缓存模式 - 热点缓存
- 从 RemoteCache 提升为LocalCache
- 主动监控防御预热,比如直播房间页高在线情况下直接外挂服务主动防御;
- 基础库框架支持热点发现,自动短时的 short-live cache;
1.7 缓存模式 - 穿透缓存
cache miss 后查询DB和将数据再次写入缓存这两个步骤是需要一定时间的,这段时间内的后续请求也会出现 cache miss,然后走同样的逻辑。
这就是缓存击穿:某个热点数据缓存失效后,同一时间的大量请求直接被打到的了DB,会给DB造成极大压力,甚至直接打崩DB。
singlefly
对关键字进行一致性 hash,使其某一个维度的 key 一定命中某个节点,然后在节点内使用互斥锁,保证归并回源,但是对于批量查询无解;
分布式锁(不建议)
设置一个 lock key,有且只有一个人成功,并且返回,交由这个人来执行回源操作,其他候选者轮训 cache 这个 lock key,如果不存在去读数据缓存,hit 就返回,miss 继续抢锁;
队列(建议)
先singlefly查db,交给消息队列回填缓存数据。
如果 cache miss,交由队列聚合一个key,来 load 数据回写缓存,对于 miss 当前请求可以使用 singlefly 保证回源,如评论架构实现。
lease(只让一个人去查)
- 通过加入 lease 机制,可以很好避免这两个问题,lease 是 64-bit 的 token,与客户端请求的 key 绑定,对于过时设置,在写入时验证 lease,可以解决这个问题;
- 对于 thundering herd,每个key 10s 分配一次,当 client 在没有获取到 lease 时,可以稍微等一下再访问 cache,这时往往cache 中已有数据。(基础库支持 & 修改 cache 源码);
1.8 缓存小技巧
- 易读性的前提下,key 设置尽可能小,减少资源的占用,redis value 可以用 int 就不要用string,对于小于 N 的 value,redis 内部有 shared_object 缓存。
- 拆分 key。主要是用在 redis 使用 hashes 情况下。同一个 hashes key 会落到同一个 redis 节点,hashes 过大的情况下会导致内存及请求分布的不均匀。考虑对 hash 进行拆分为小的hash,使得节点内存均匀及避免单节点请求热点。
- 空缓存设置。对于部分数据,可能数据库始终为空,这时应该设置空缓存,避免每次请求都缓存 miss 直接打到 DB。
- 空缓存保护策略。
- 读失败后的写缓存策略(降级后一般读失败不触发回写缓存)。
- 序列化使用 protobuf,尽可能减少 size。
1.9 redis 小技巧
- 增量更新一致性:EXPIRE(先续期)、ZADD/HSET 等,保证索引结构体务必存在的情况下去操作新增数据;
- BITSET: 存储每日登陆用户,单个标记位置(boolean),为了避免单个 - BITSET 过大或者热点,需要使用 region sharding,比如按照mid求余 %和/ 10000,商为 KEY、余数作为offset;
- List:抽奖的奖池、顶弹幕,用于类似 Stack PUSH/POP操作;
- Sortedset: 翻页、排序、有序的集合,杜绝 zrange 或者 zrevrange 返回的集合过大;
- Hashs: 过小的时候会使用压缩列表、过大的情况容易导致 rehash 内存浪费,也杜绝返回hgetall
- String: SET 的 EX/NX 等 KV 扩展指令,SETNX 可以用于分布式锁、SETEX 聚合了SET + EXPIRE;
- Sets: 类似 Hashs,无 Value,去重等;
- 尽可能的 PIPELINE 指令,但是避免集合过大;
- 避免超大 Value;
2. 分布式事务
我们需要保证,跨多个服务的步骤数据一致性:1.微服务pay的支付宝表扣除1万,2.微服务balance的余额宝表增加1万。
2.1 提前保证
1. Best Effort 最大努力交付
做过支付宝交易接口的同学都知道,我们一般会在支付宝的回调页面和接口里,解密参数,然后调用系统中更新交易状态相关的服务,将订单更新为付款成功。
同时,只有当我们回调页面中输出了success字样或者标识业务处理成功相应状态码时,支付宝才会停止回调请求。否则,支付宝会每间隔一段时间后再向客户方发起回调情求,直到输出成功标识为止。
尽最大努力交付,主要用于在这样一种场景: 不同的服务平台之间的事务性保证。
重试和回调要考虑幂等的问题。
2. 幂等处理
一般是消费的服务,要处理幂等性。
- 消费队列的时候,可以通过状态判断,需要全局唯一ID表。
- 版本号。
2.2 事务消息方案
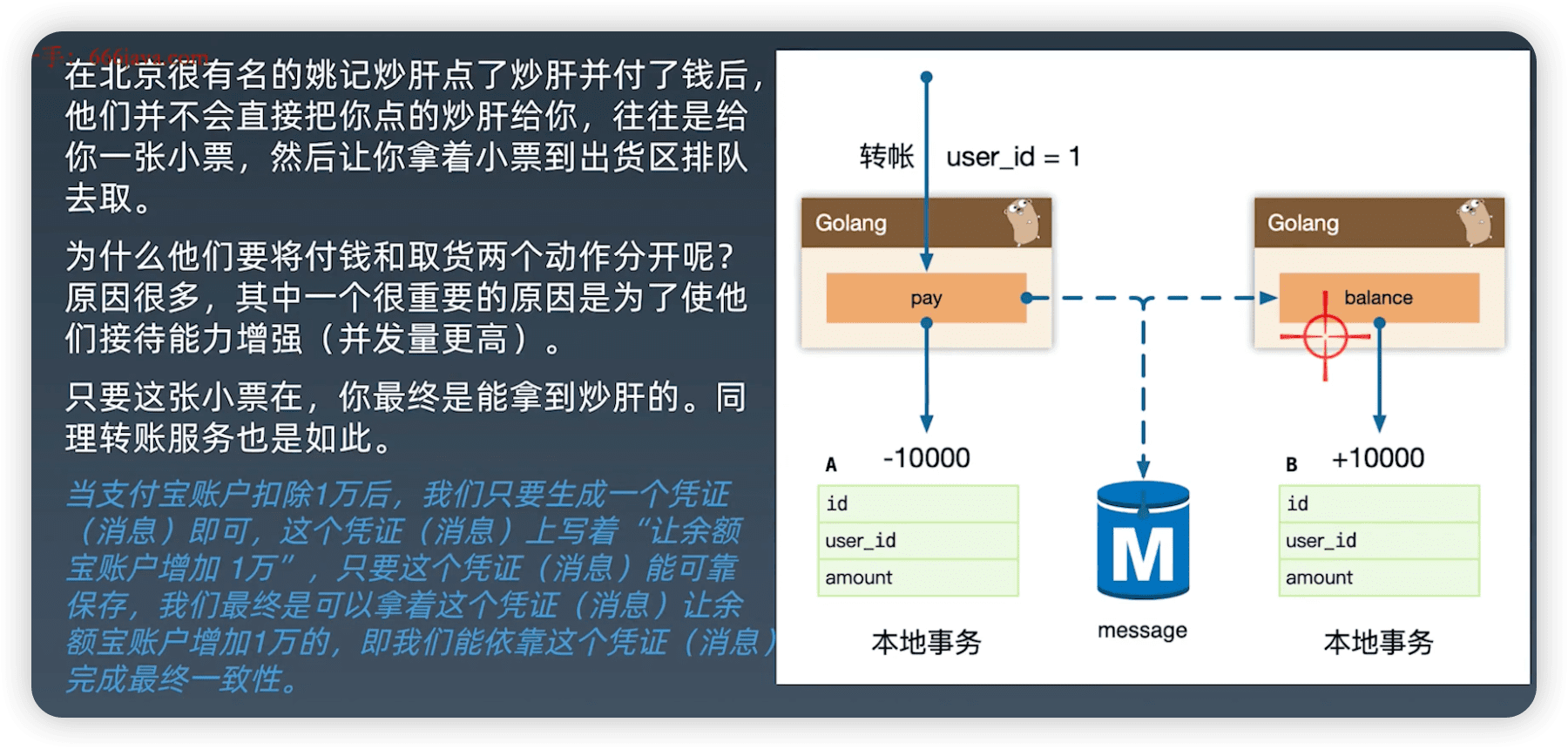
付钱后得到一个凭证,保证凭证的可靠性保存。怎么保证可靠性保证?
- Transactional outbox
- Polling publisher
- Transaction log tailing
- 2PC Message Queue
1. Transactional outbox 本地事务消息表
新建一个msg表,开启本地事务,保证msg一定写成功。
Transactional outbox,支付宝在完成扣款的同时,同时记录消息数据,这个消息数据与业务数据保存在同一数据库实例里(消息记录表表名为msg)
上述事务能保证只要支付宝账户里被扣了钱,消息一定能保存下来。当上述事务提交成功后, 我们想办法将此消息通知余额宝,余额宝处理成功后发送回复成功消息,支付宝收到回复后删除该条消息数据。
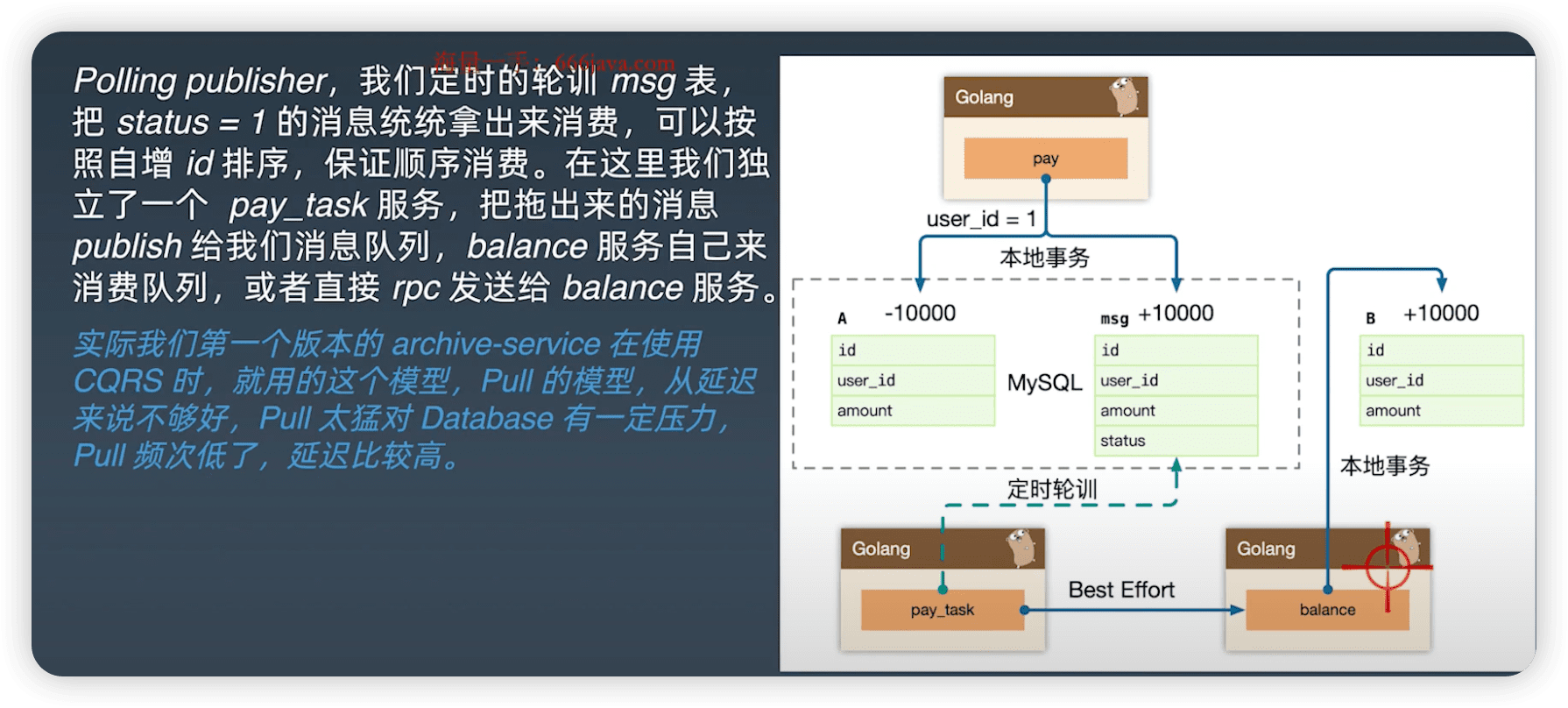
2. Polling publisher
Polling publisher,我们定时的轮训 msg 表。
把status=1的消息统统拿出来消费,可以按照自增id排序,保证顺序消费。
在这里我们独立了一个pay_task服务,把拖出来的消息 publish给我们消息队列,balance服务自己来消费队列,或者直接rpc发送给balance服务。
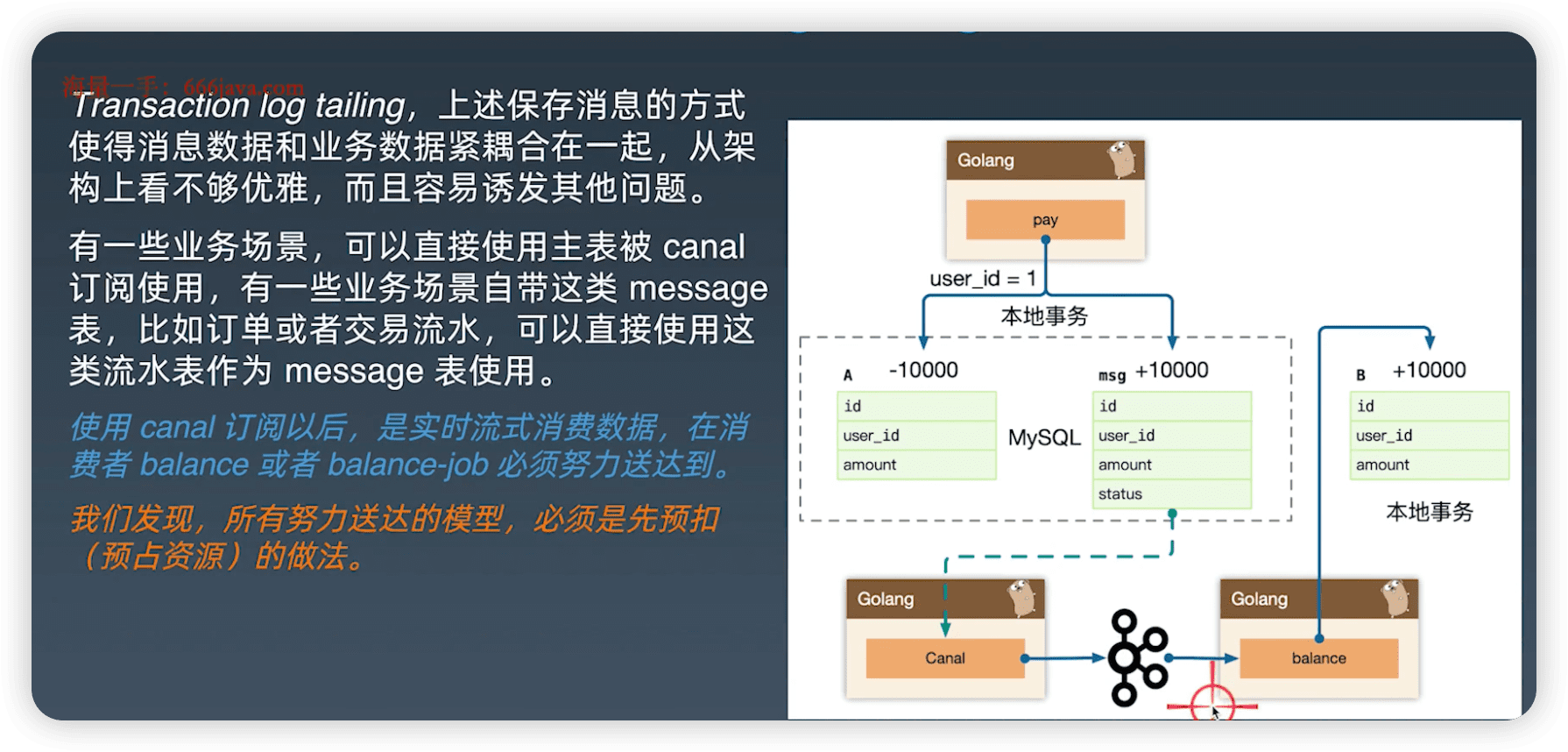
3. Transaction log tailing
- 订阅数据库的bin_log。
- 我们发现,所有努力送达的模型,必须是先预扣 (预占资源)的做法(应该先扣钱,不能先给东西)。
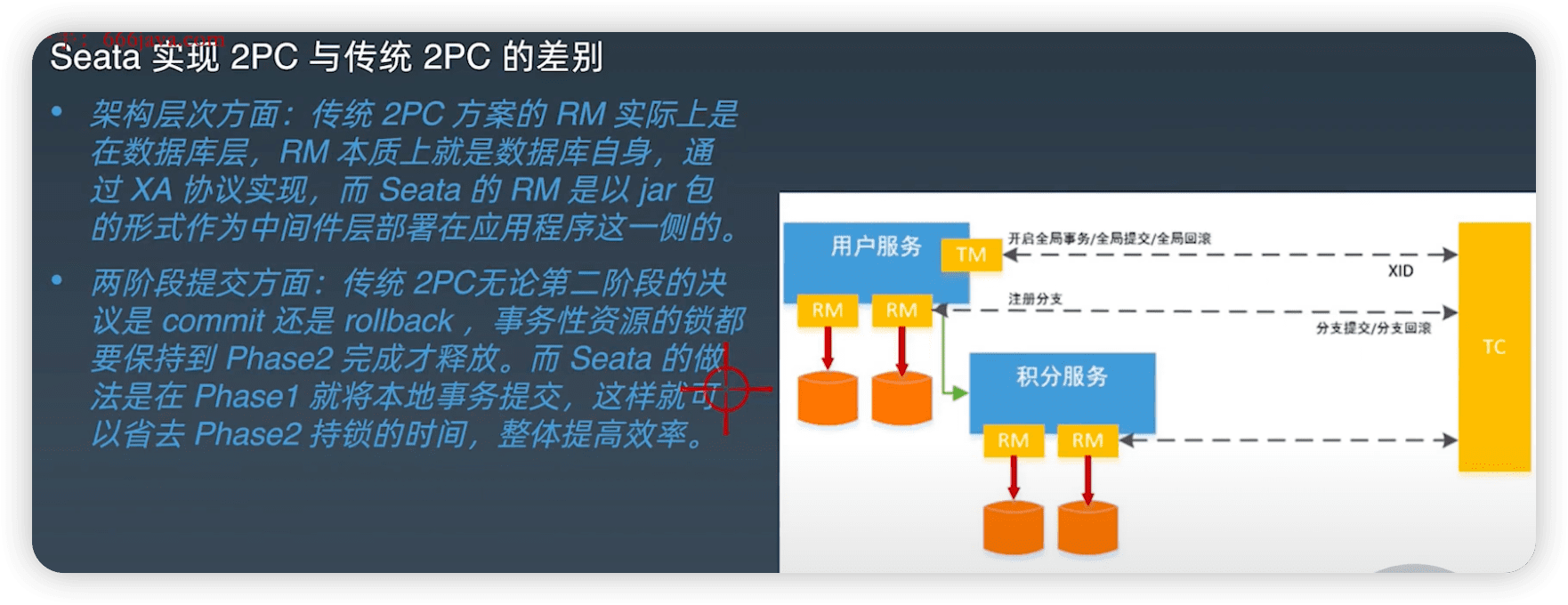
2.3 2PC和Seata 2PC
2.3 TCC 和 Saga
TCC要求每个分支事务实现三个操作预处理Try、确认Confirm、 撤销Cancel。”针对每个操作都要注册一个与其对应的确认(Try)和补偿(Cancel)”。
Saga是采用事件编排方案,会用补偿操作来撤销之前的操作,并让系统恢复到更一致些的状态。
可以参考:https://www.liuvv.com/p/bb1dd10.html