prometheus的alertmanager使用
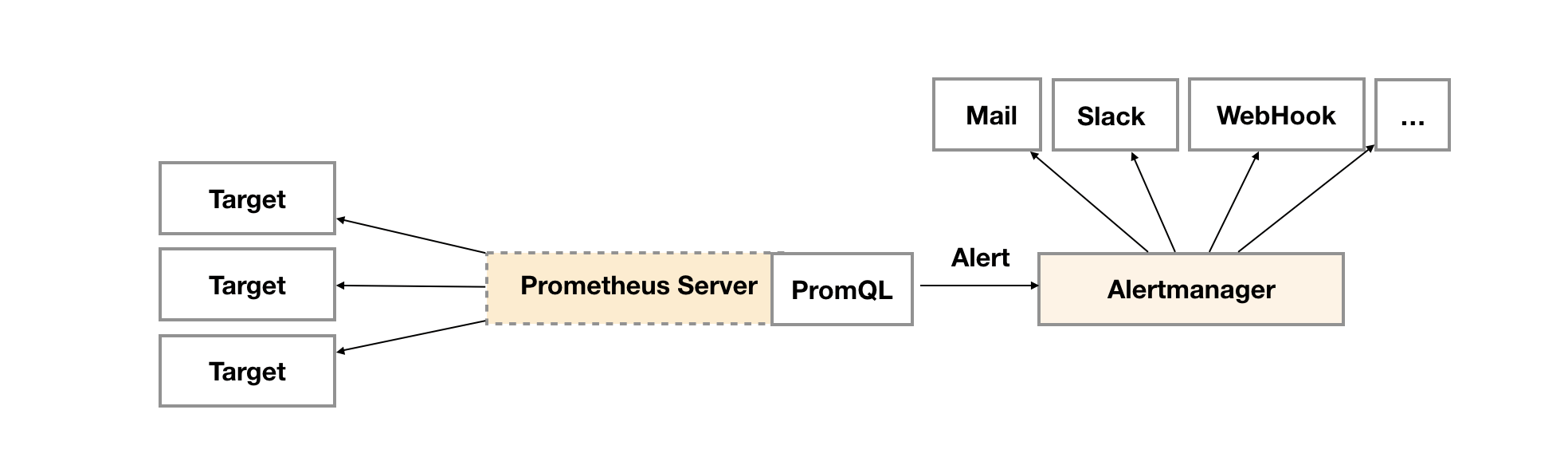
告警能力在Prometheus的架构中被划分成两个独立的部分通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。
1. 数据看板
教程: https://prometheus.io/docs/guides/node-exporter/
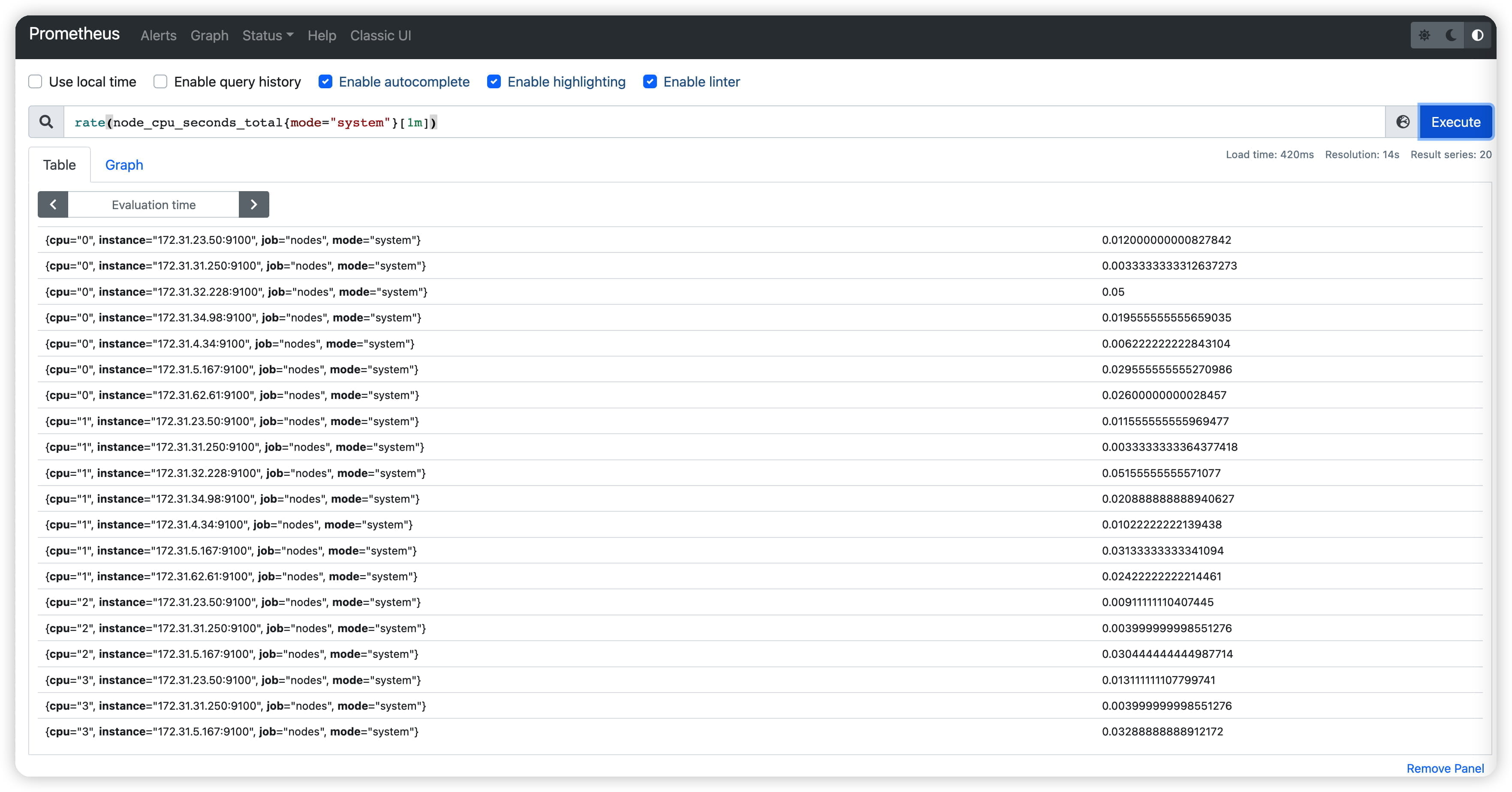
1.1 查看 metrics
查看target的metrics数据,如果是局域网,可以curl观看。
1 | curl http://172.31.32.228:9100/metrics |
1.2 登录prometheus面板查询
Click on the links below to see some example metrics:
| Metric | Meaning |
|---|---|
| rate(node_cpu_seconds_total{mode=”system”}[1m]) | The average amount of CPU time spent in system mode, per second, over the last minute (in seconds) |
node_filesystem_avail_bytes | The filesystem space available to non-root users (in bytes) |
rate(node_network_receive_bytes_total[1m]) | The average network traffic received, per second, over |
1.3 常用查询
- 硬盘百分比
1 | (node_filesystem_size_bytes{fstype=~"ext.?|xfs"}-node_filesystem_free_bytes{fstype=~"ext.?|xfs"}) *100/(node_filesystem_avail_bytes {fstype=~"ext.?|xfs"}+(node_filesystem_size_bytes{fstype=~"ext.?|xfs"}-node_filesystem_free_bytes{fstype=~"ext.?|xfs"})) |
2. Alertmanager
Alertmanager和Prometheus Server一样均采用Golang实现,并且没有第三方依赖。
2.1 下载安装
https://prometheus.io/download/#alertmanager
1 | sudo wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz |
Alertmanager解压后会包含一个默认的alertmanager.yml配置文件,Alertmanager的配置主要包含两个部分:路由(route)以及接收器(receivers)。
所有的告警信息都会从配置中的顶级路由(route)进入路由树,根据路由规则将告警信息发送给相应的接收器。Alermanager会将数据保存到本地中,默认的存储路径为data/。
2.2 服务并启动
1 | sudo vi /usr/lib/systemd/system/alertmanager.service |
1 | [Unit] |
1 | sudo systemctl daemon-reload |
- 访问
Alertmanager启动后可以通过9093端口访问。
1 | curl http://127.0.0.1:9093 |
2.3 关联Prometheus
编辑Prometheus配置文件prometheus.yml,并添加以下内容
1 | alerting: |
重启Prometheus服务,成功后,可以从http://192.168.40.98:9090/config 查看alerting配置是否生效。
2.3 Prometheus告警规则
一条告警规则主要由以下几部分组成:
alert:告警规则的名称。
expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
为了能够让Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule_files指定一组告警规则文件的访问路径。
1 | rule_files: |
创建告警
sudo vi node-export-alert.rules
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61groups:
- name: NodeExportAlert
rules:
- alert: DiskUsageAlert
expr: max((node_filesystem_size_bytes{fstype=~"ext.?|xfs"}-node_filesystem_free_bytes{fstype=~"ext.?|xfs"}) *100/(node_filesystem_avail_bytes {fstype=~"ext.?|xfs"}+(node_filesystem_size_bytes{fstype=~"ext.?|xfs"}-node_filesystem_free_bytes{fstype=~"ext.?|xfs"})))by(instance) > 70
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} disk usgae high"
description: "Disk usage high, above 70% (current value: {{ $value }})"
- alert: CpuAlert
expr: (1 - avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) * 100 > 70
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} disk usgae high"
description: "CPU usage high, above 70% (current value: {{ $value }})"
- alert: MemoryUsageAlert
expr: (1 - (node_memory_MemAvailable_bytes{} / (node_memory_MemTotal_bytes{})))* 100 > 70
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} disk usgae high"
description: "Memory usage high, above 70% (current value: {{ $value }})"
- alert: DiskIOAlert
expr: rate(node_disk_io_time_seconds_total{job='nodes'}[1m]) * 100 > 50
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} disk io high"
description: "Disk io high, current value: {{ $value }})"
- alert: DiskWriteAlert
expr: rate(node_disk_written_bytes_total{job='nodes'}[1m])/8/1024/1024 > 10
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} Disk write high"
description: "Disk write high, current value: {{ $value }}) M/s"
- alert: FileFdAlert
expr: (node_filefd_allocated{job='nodes'}/node_filefd_maximum{job='nodes'}) *100 > 50
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} file fd high"
description: "File fd high, current value: {{ $value }})"1
sudo systemctl restart prometheus
重启Prometheus后访问Prometheus UI http://127.0.0.1:9090/rules可以查看当前以加载的规则文件。
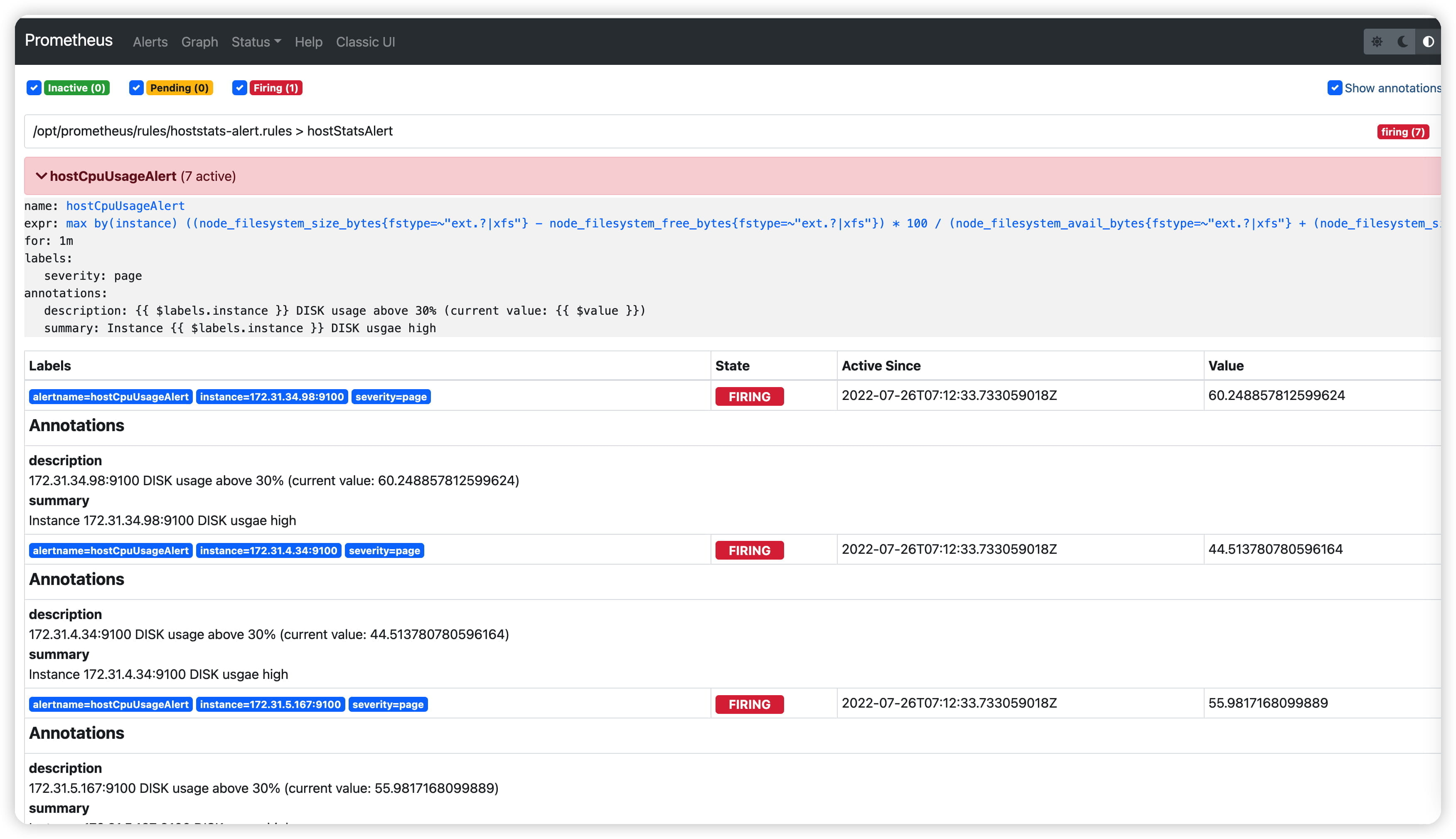
查看Alertmanager UI此时可以看到Alertmanager接收到的告警信息。
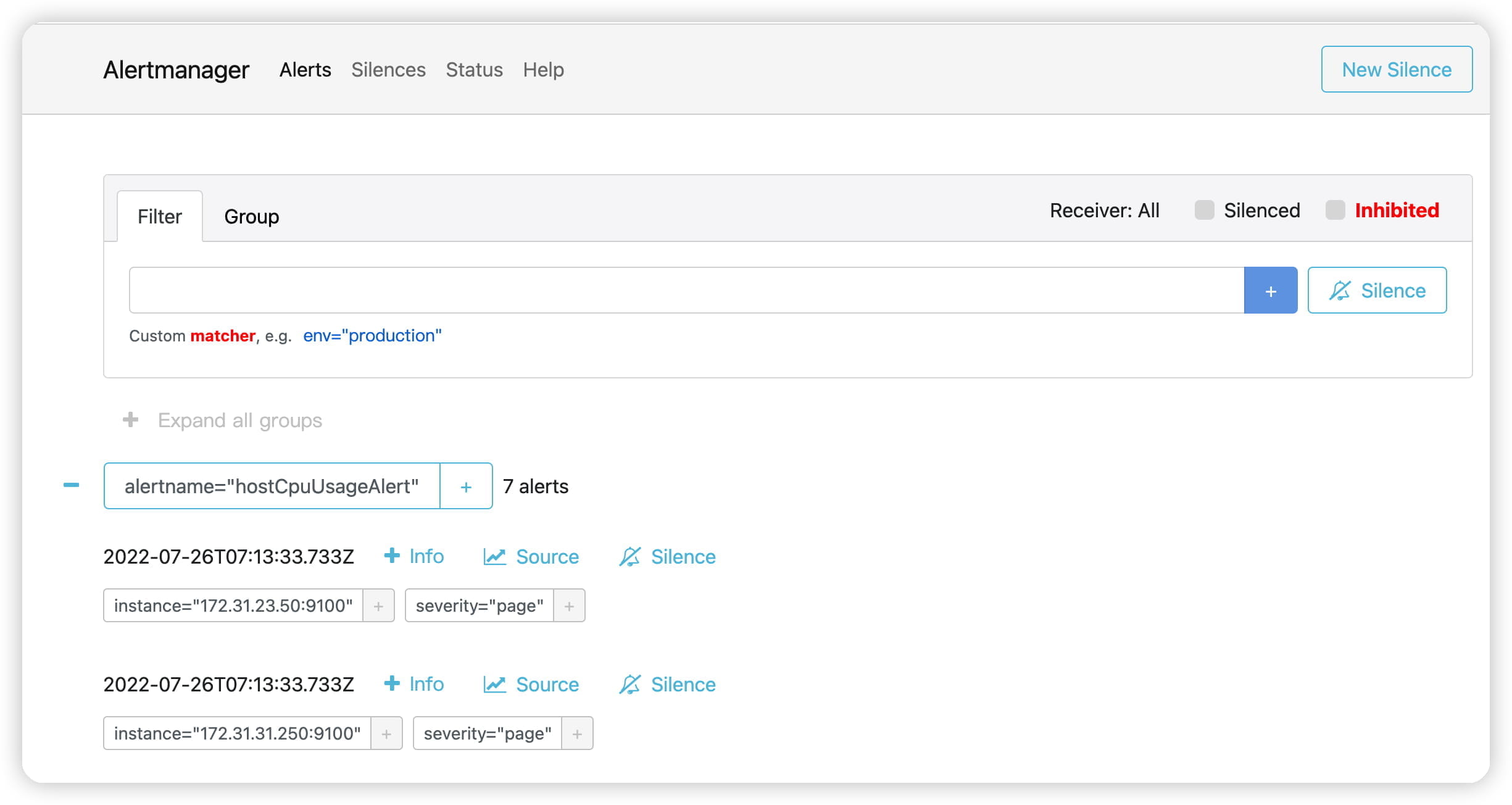
3. Alertmanager配置
Alertmanager主要负责对Prometheus产生的告警进行统一处理,因此在Alertmanager配置中一般会包含以下几个主要部分:
- 全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
- 模板(templates):用于定义告警通知时的模板,如HTML模板,邮件模板等;
- 告警路由(route):根据标签匹配,确定当前告警应该如何处理;
- 接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用;
- 抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生。
在全局配置中需要注意的是resolve_timeout,该参数定义了当Alertmanager持续多长时间未接收到告警后标记告警状态为resolved(已解决)。该参数的定义可能会影响到告警恢复通知的接收时间,读者可根据自己的实际场景进行定义,其默认值为5分钟。
3.1 webhook配置
1 | cd /opt/alertmanager |
- 配置
1 | route: |
- 重启
1 | sudo systemctl restart prometheus |
3.2 webhook代码
1 | package main |
3.3 启动服务
sudo vi /usr/lib/systemd/system/alerthook.service
1 | [Unit] |
- 操作
1 | sudo systemctl daemon-reload |