http2的变化和原理
1. http2介绍
HTTP/2 出来的目的是为了改善 HTTP 的性能。协议升级有一个很重要的地方,就是要兼容老版本的协议,否则新协议推广起来就相当困难,所幸 HTTP/2 做到了兼容 HTTP/1.1 。那么,HTTP/2 是怎么做的呢?
第一点,HTTP/2 没有在 URI 里引入新的协议名,仍然用「http://」表示明文协议,用「https://」表示加密协议,于是只需要浏览器和服务器在背后自动升级协议,这样可以让用户意识不到协议的升级,很好的实现了协议的平滑升级。
第二点,只在应用层做了改变,还是基于 TCP 协议传输,应用层方面为了保持功能上的兼容,HTTP/2 把 HTTP 分解成了「语义」和「语法」两个部分,「语义」层不做改动,与 HTTP/1.1 完全一致,比如请求方法、状态码、头字段等规则保留不变。
但是,HTTP/2 在「语法」层面做了很多改造,基本改变了 HTTP 报文的传输格式。
2. http2功能
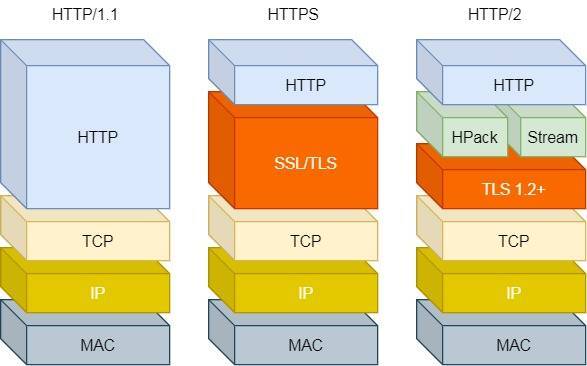
2.1 头部压缩
HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。
这就是所谓的 HPACK 算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
2.2 二进制格式
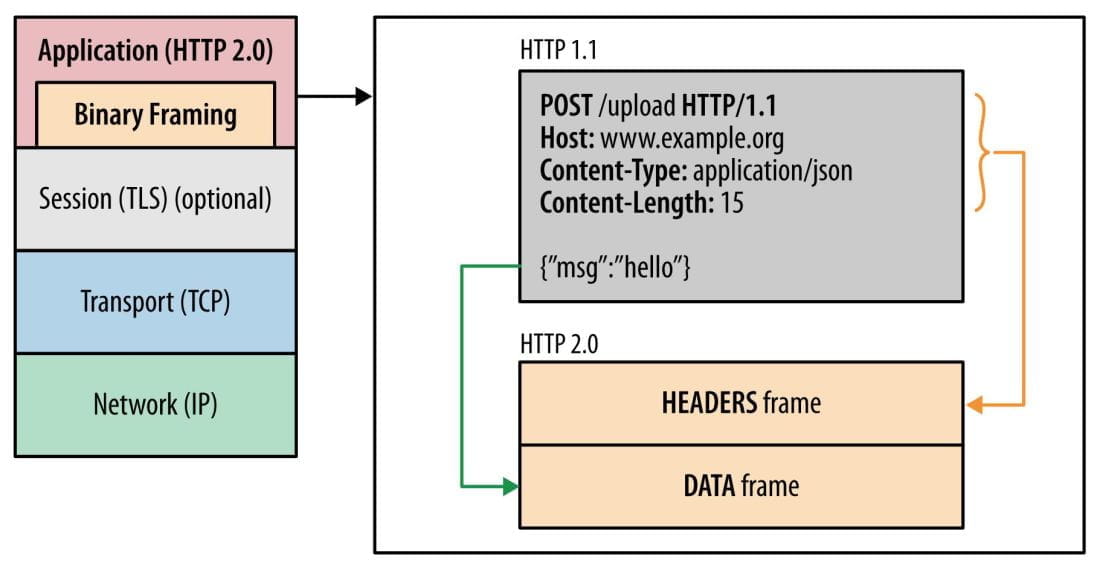
HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为”帧”(frame):头信息帧和数据帧。
- 帧头(Fream Header)很小,只有 9 个字节,帧开头的前 3 个字节表示帧数据(Fream Playload)的长度。
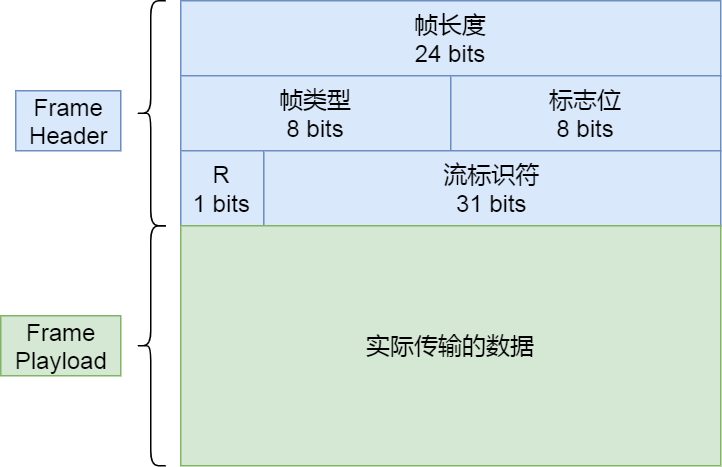
- 后面就是帧数据了,它存放的是通过 HPACK 算法压缩过的 HTTP 头部和包体。
2.3 Stream 并发传输
HTTP/1.1 的实现是基于请求-响应模型的,如果响应迟迟不来,那么后续的请求是无法发送的,也造成了Http 队头阻塞的问题。而 HTTP/2 通过 Stream 这个设计,多个 Stream 复用一条 TCP 连接。
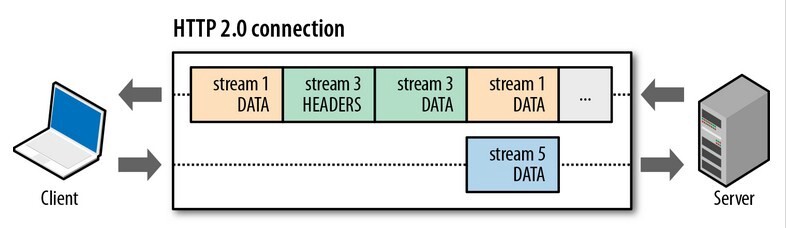
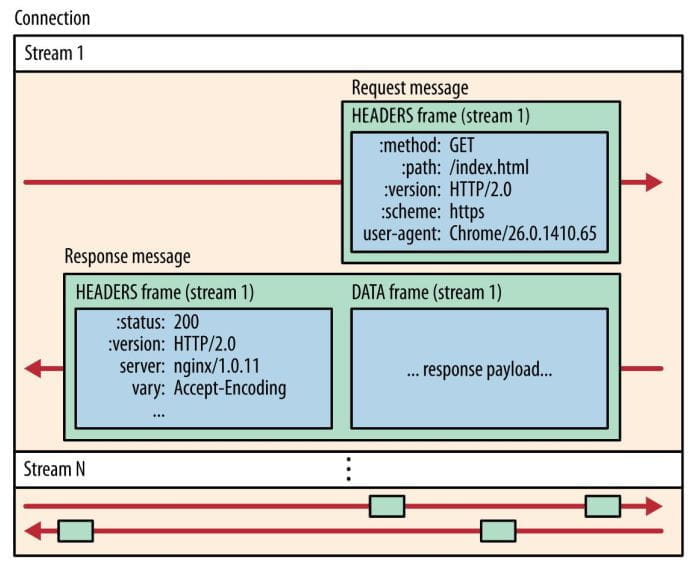
- 一个 TCP 连接包含一个或者多个 Stream,Stream 是 HTTP/2 并发的关键技术;
- 客户端建立的 Stream 必须是奇数号,而服务器建立的 Stream 必须是偶数号。当 Stream ID 耗尽时,需要发一个控制帧
GOAWAY,用来关闭 TCP 连接。 - Stream 里可以包含 1 个或多个 Message,Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成;
- Message 里包含一条或者多个 Frame,Frame 是 HTTP/2 最小单位,以二进制压缩格式存放 HTTP/1 中的内容(头部和包体);
- 不同 Stream 的帧是可以乱序发送的,因此可以并发不同的 Stream 。
- 同一 Stream 内部的帧必须是严格有序的。
- 在 Nginx 中,可以通过
http2_max_concurrent_streams配置来设置 Stream 的上限,默认是 128 个。
2.4 服务器推送
比如,客户端通过 HTTP/1.1 请求从服务器那获取到了 HTML 文件,而 HTML 可能还需要依赖 CSS 来渲染页面,这时客户端还要再发起获取 CSS 文件的请求,需要两次消息往返,如下图左边部分:
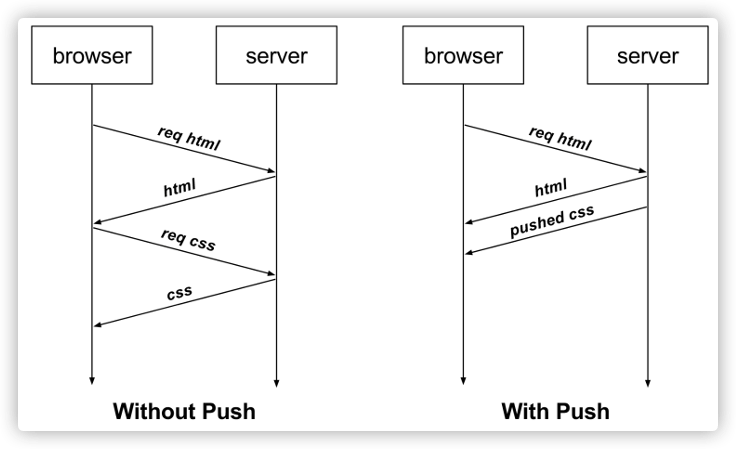
如上图右边部分,在 HTTP/2 中,客户端在访问 HTML 时,服务器可以直接主动推送 CSS 文件,减少了消息传递的次数。
在 Nginx 中,如果你希望客户端访问 /test.html 时,服务器直接推送 /test.css,那么可以这么配置:
1 | location /test.html { |
Server Push不同于Websocket,Server Push一般是指服务器主动向客户端推送数据,这是一种单向的主动推送,而WebSocket是双向的,这两种技术不是竞争关系。
现代的网站的静态资源大多都是CDN架构的,静态资源都在第三方服务器,Server Push作用并不大。
3. 长连接区别
3.1 websocket
WebSocket是全双工的,可以双向通信,主要应用在实时通信的场景中,服务器可以实时推送数据给客户端。
3.2 SSE 技术
SSE ( Server-sent Events )是 WebSocket 的一种轻量代替方案,使用 HTTP 协议。严格地说,HTTP 协议是没有办法做服务器推送的,但是当服务器向客户端声明接下来要发送流信息时,客户端就会保持连接打开,SSE 使用的就是这种原理。
SSE 是单向通道,只能服务器向客户端发送消息,如果客户端需要向服务器发送消息,则需要一个新的 HTTP 请求。 这对比 WebSocket 的双工通道来说,会有更大的开销。
3.3 http2
HTTP/2 虽然也支持 Server Push,但是服务器只能主动将资源推送到客户端缓存!那不是应用程序可以感知的,主要是让浏览器(用户代理)提前缓存静态资源。
HTTP/2不是类似于Websocket或者SSE这样的推送技术的替代品。
4. 复用 tcp 连接
4.1 http1 baseline
所谓长连接,即在 HTTP 请求建立 TCP 连接时,请求结束,TCP 连接不断开,继续保持一段时间(timeout),在这段时间内,同一客户端向服务器发送请求都会复用该 TCP 连接,并重置 timeout 时间计数器,在接下来 timeout 时间内还可以继续复用 TCP 。
timeout 时间到了之后,TCP会立即断开连接吗?
若两小时(timeout)没有收到客户的数据,服务器就发送一个探测报文段,以后则每隔 75 秒发送一次。若一连发送 10 个探测报文段后仍无客户的响应,服务器就认为客户端出了故障,接着就关闭这个连接。
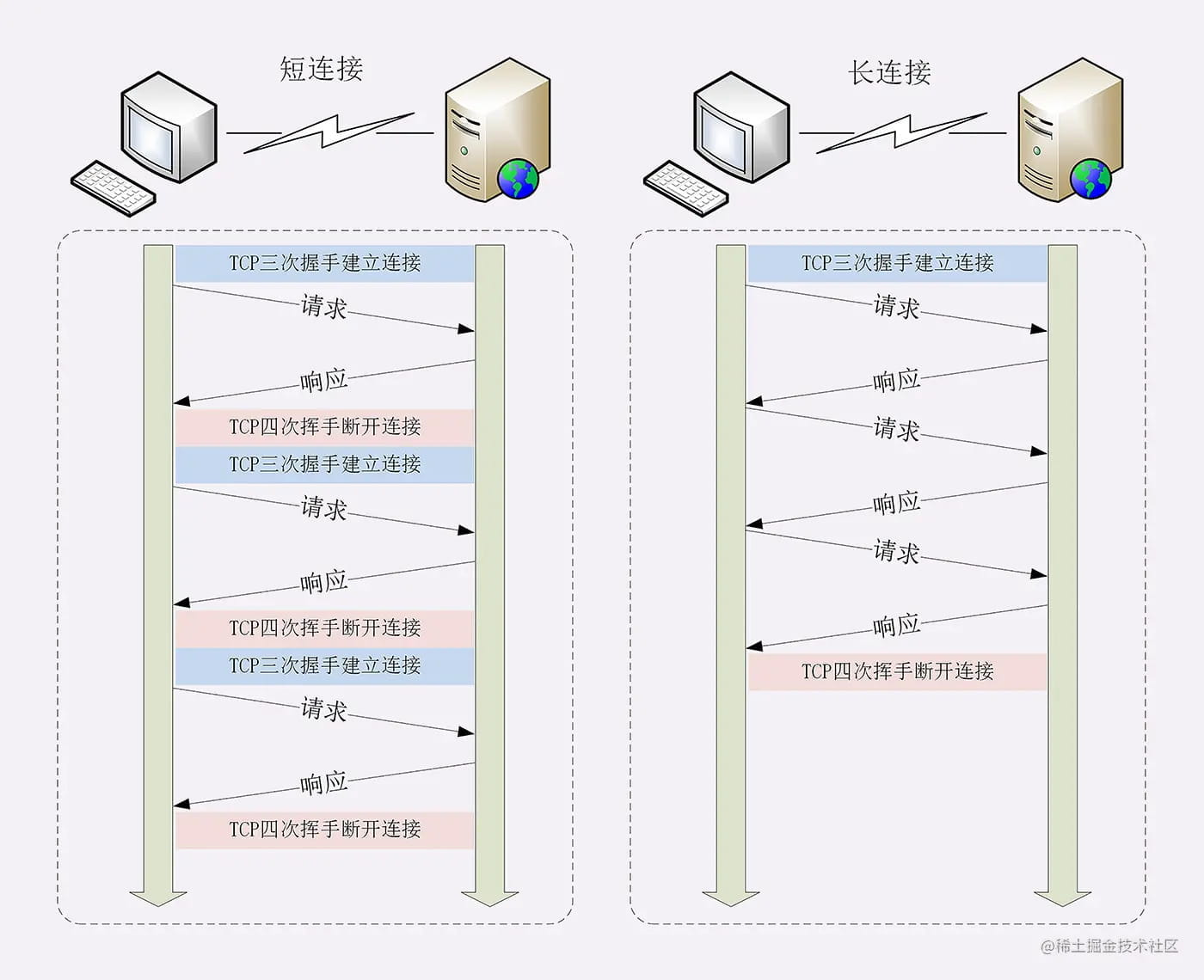
HTTP/1.x 虽然引入了 keep-alive 长连接,但它每次请求必须等待上一次响应之后才能发起。
所以,在 HTTP/1.1 中提出了管道机制(默认不开启),下一次的请求不需要等待上一个响应来之后再发送,但这要求服务端必须按照请求发送的顺序返回响应,当顺序请求多个文件时,其中一个请求因为某种原因被阻塞时,在后面排队的所有请求也一并被阻塞,这就是 HTTP 队头阻塞 (Head-Of-Line Blocking)。
4.2 http2 multiplex
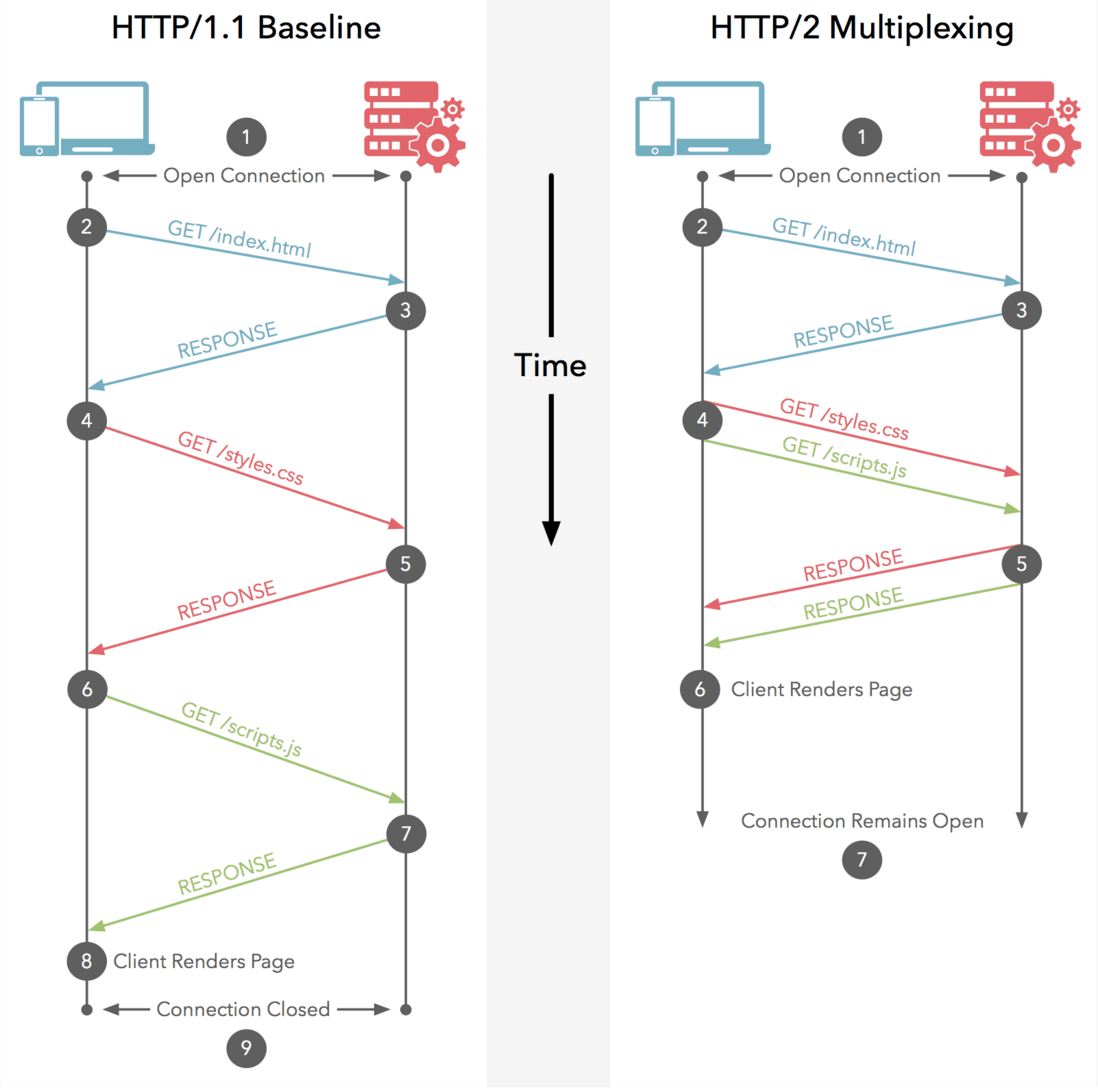
- HTTP/1.x 是基于文本的,只能整体去传;HTTP/2 是基于二进制流的,可以分解为独立的帧,交错发送
- HTTP/1.x keep-alive 必须按照请求发送的顺序返回响应;HTTP/2 多路复用不按序响应。
- HTTP/1.x keep-alive 为了解决 http 队头阻塞,将同一个页面的资源分散到不同域名下,开启了多个 TCP 连接;HTTP/2 同域名下所有通信都在单个连接上完成。
- HTTP/1.x keep-alive 单个 TCP 连接在同一时刻只能处理一个请求(两个请求的生命周期不能重叠);HTTP/2 单个 TCP 同一时刻可以发送多个请求和响应。
5. 队头阻塞问题
很多人在一些资料中会看到有论点说HTTP/2解决了队头阻塞的问题。但是这句话只对了一半。只能说HTTP/2解决了HTTP的队头阻塞问题,但是并没有解决TCP队头阻塞问题!
5.1 HTTP 队头阻塞
http1.x采用长连接(Connection:keep-alive),可以在一个TCP请求上,发送多个http请求。有非管道化和管道化,两种方式。
非管道化:完全串行执行,请求->响应->请求->响应…,后一个请求必须在前一个响应之后发送。
管道化:请求可以并行发出,但是响应必须串行返回。后一个响应必须在前一个响应之后。原因是,没有序号标明顺序,只能串行接收。
无论是非管道化还是管道化,都会造成HTTP队头阻塞(请求阻塞)。
5.2 TCP 队头阻塞
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当「前 1 个字节数据」没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
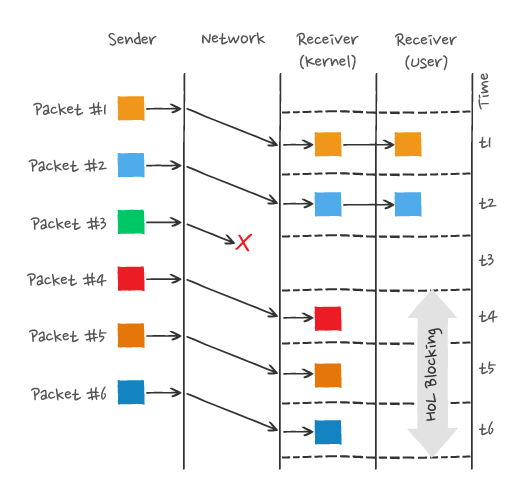
上面 packet 3 在网络中丢失了,即使 packet 4-6 被接收方收到后,由于内核中的 TCP 数据不是连续的,于是接收方的应用层就无法从内核中读取到,只有等到 packet 3 重传后,接收方的应用层才可以从内核中读取到数据,这就是 HTTP/2 的队头阻塞问题,是在 TCP 层面发生的。
5.3 总结
- HTTP/1.1的管道化持久连接也是使得同一个TCP链接可以被多个HTTP使用,但是HTTP/1.1中规定一个域名可以有6个TCP连接。
- HTTP/2使用一个域名单一TCP连接发送请求,请求包被二进制分帧,不同请求可以互相穿插,避免了 http 层面的请求队头阻塞。但是不能避免TCP层面的队头阻塞。
- 在HTTP/2中,TCP队头阻塞造成的影响会更大,因为HTTP/2的多路复用技术使得多个请求其实是基于同一个TCP连接的,那如果某一个请求造成了TCP队头阻塞,那么多个请求都会受到影响。
6. http3 初探
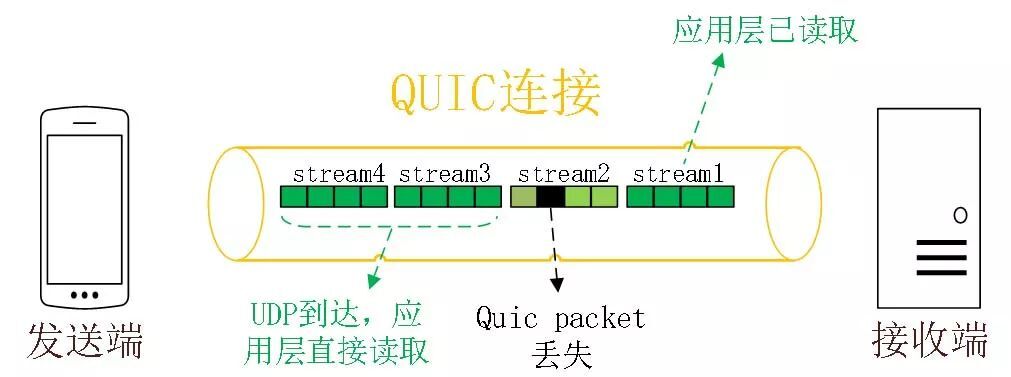
UDP 发送是不管顺序,也不管丢包的,所以不会出现像 HTTP/2 队头阻塞的问题。大家都知道 UDP 是不可靠传输的,但基于 UDP 的 QUIC 协议 可以实现类似 TCP 的可靠性传输。
QUIC 有以下 3 个特点。
6.1 无队头阻塞
QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响,因此不存在队头阻塞问题。这与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,某个流发生丢包了,只会影响该流,其他流不受影响。
6.2 更快的连接建立
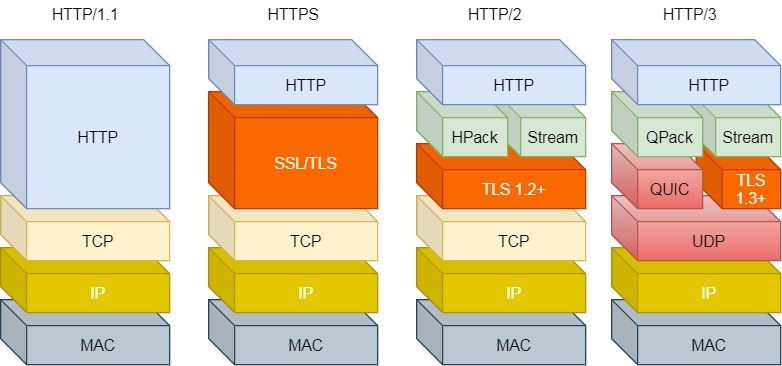
对于 HTTP/1 和 HTTP/2 协议,需要先 TCP 握手,再 TLS 握手。
HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是 QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的“记录”,再加上 QUIC 使用的是 TLS/1.3,因此仅需 1 个 RTT 就可以「同时」完成建立连接与密钥协商。
6.3 连接迁移
基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接。
那么当移动设备的网络从 4G 切换到 WIFI 时,意味着 IP 地址变化了,那么就必须要断开连接,然后重新建立连接。而建立连接的过程包含 TCP 三次握手和 TLS 四次握手的时延,以及 TCP 慢启动的减速过程,给用户的感觉就是网络突然卡顿了一下,因此连接的迁移成本是很高的。
而 QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID 来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
所以, QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议。