mysql的执行过程和优化技术
1. SQL的执行过程
1.1 流程
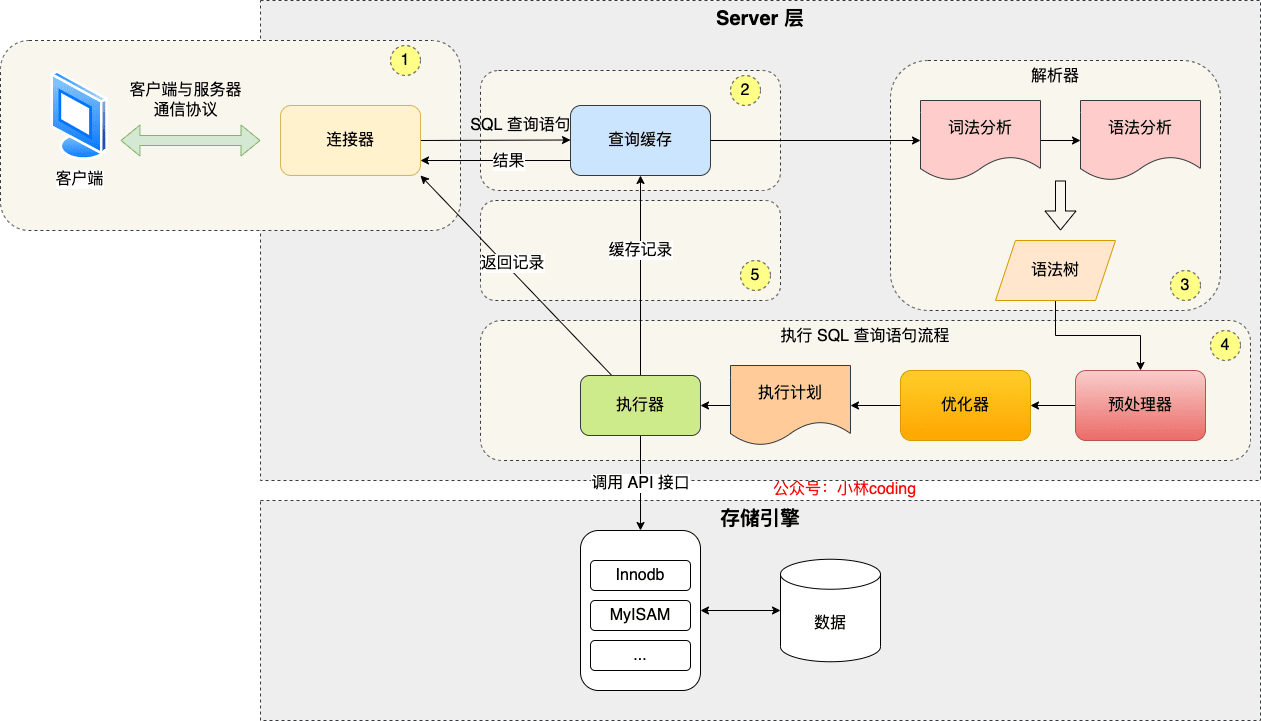
- 首先客户端发送请求到服务端,建立连接。
- 服务端先看下查询缓存是否命中,命中就直接返回,否则继续往下执行。
- 接着来到解析器,进行语法分析,一些系统关键字校验,校验语法是否合规。
- 然后优化器进行SQL优化,比如怎么选择索引之类,然后生成执行计划。
- 最后执行引擎调用存储引擎API查询数据,返回结果。
1.2 分析
Server 层负责建立连接、分析和执行 SQL。
MySQL 大多数的核心功能模块都在这实现,主要包括连接器,查询缓存、解析器、预处理器、优化器、执行器等。另外,所有的内置函数(如日期、时间、数学和加密函数等)和所有跨存储引擎的功能(如存储过程、触发器、视图等。)都在 Server 层实现。
存储引擎层负责数据的存储和提取。
1.3 索引下推
索引下推能够减少二级索引在查询时的回表操作,提高查询的效率,因为它将 Server 层部分负责的事情,交给存储引擎层去处理了。
1 | -- 联合索引 index(age, reward) |
不使用
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎根据二级索引的 B+ 树快速定位到这条记录后,获取主键值,然后进行回表操作,将完整的记录返回给 Server 层;
- Server 层在判断该记录的 reward 是否等于 100000,如果成立则将其发送给客户端;否则跳过该记录;
- 接着,继续向存储引擎索要下一条记录,存储引擎在二级索引定位到记录后,获取主键值,然后回表操作,将完整的记录返回给 Server 层;
- 如此往复,直到存储引擎把表中的所有记录读完。
使用索引下推
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎定位到二级索引后,先不执行回表操作,而是先判断一下该索引中包含的列(reward列)的条件(reward 是否等于 100000)是否成立。如果条件不成立,则直接跳过该二级索引。如果成立,则执行回表操作,将完成记录返回给 Server 层。
- Server 层在判断其他的查询条件(本次查询没有其他条件)是否成立,如果成立则将其发送给客户端;否则跳过该记录,然后向存储引擎索要下一条记录。
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,使用了索引下推后,虽然 reward 列无法使用到联合索引,但是因为它包含在联合索引(age,reward)里,所以直接在存储引擎过滤出满足 reward = 100000 的记录后,才去执行回表操作获取整个记录。相比于没有使用索引下推,节省了很多回表操作。
2. 技术优化
Index Condition Pushdown 优化可以将查询效率在原有 MySQL 5.5 版本的技术上提高 23%,而再同时启用 Mulit-Range Read 优化后,性能还能有 400% 的提升!
2.1 Index Condition Pushdown 优化(索引下推)
复合索引直接判断,减少回表。
1 | 想象一下你去图书馆找书的场景: |
- 在不使用ICP的情况下,在使用非主键索引(又叫普通索引或者二级索引)进行查询时,存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件。
- 在使用ICP的情况下,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。
- 索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数。
- 当优化器选择 Index Condition Pushdown 优化时,可在执行计划的列 Extra 看到 Using index condition 提示。
假设某张表有联合索引(zip_code,last_name,first_name),并且查询语句如下:
1 | SELECT*FROM people WHERE zipcode='95054' AND lastname LIKE'%etrunia%' AND address LIKE'%Main Street%'; |
若不支持 Index Condition Pushdown 优化,则数据库需要先通过索引取出所有 zipcode 等于 95054 的记录,然后再过滤 WHERE 之后的两个条件。
若支持 Index Condition Pushdown 优化,则在索引取出时,就会进行 WHERE 条件的过滤,然后再去获取记录。这将极大地提高查询的效率。当然,WHERE 可以过滤的条件是要该索引可以覆盖到的范围。
2.2 Multi-Range Read 优化(多范围读)
收集主键,排序后批量回表,减少磁盘的随机访问。
1 | 想象一下,你手上有一份书单,上面列了 10 本你要借的书,这些书都属于“计算机科学”这个类别。 |
MySQL5.6 版本开始支持 Multi-Range Read(MRR)优化。Multi-Range Read 优化的目的就是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,这对于 IO-bound 类型的 SQL 查询语句可带来性能极大的提升。
通常情况下,在执行查询时,MySQL会遍历整个索引树,以找到所有匹配的行。但是,对于大型数据集,这种方式可能会导致性能下降,因为它需要大量的磁盘I/O和CPU资源。
MRR通过将索引分成多个范围并在内存中缓存结果来避免这种情况。在使用MRR时,MySQL会尝试将查询范围分成多个不重叠的部分,并使用范围扫描技术来查找每个部分中的匹配行。这种方式可以有效地减少磁盘I/O和CPU消耗,从而提高查询性能。
MRR能够提升性能的核心在于,一个范围查询(也就是说,这是一个多值查询),可以得到足够多的主键id。这样通过排序以后,再去主键索引查数据,才能体现出“顺序性”的优势。
3. 头脑风暴
执行过程:建立连接,查询缓存,语法分析,sql优化,到存储引擎层获取数据。
索引下推,一般是一个复合索引,查询的时候,直接在存储器过滤。
多范围读MRR。理解为查询条件拆分,然后再进行数据查询,减少磁盘的随机访问。