golang的map实现原理
HashMap 有两种主流实现方式:开放寻址法和拉链法。Go 的 map 采用拉链法实现。
Go map 的核心结构包含:
- 一个 hmap 结构,维护 2^B 个桶
- 数据存储在桶数组中,每个桶最多存放 8 个 key/value 对
- 超出容量的数据会链接到溢出桶
基本数据结构:桶数组 + 桶内 key-value 数组 + 溢出桶链表
1. 底层实现
源码:https://github.com/golang/go/blob/master/src/runtime/map.go#L117
1 | type hmap struct { |
编译期会动态生成完整的 bmap 结构:
1 | type bmap struct { |
1.1 数据结构
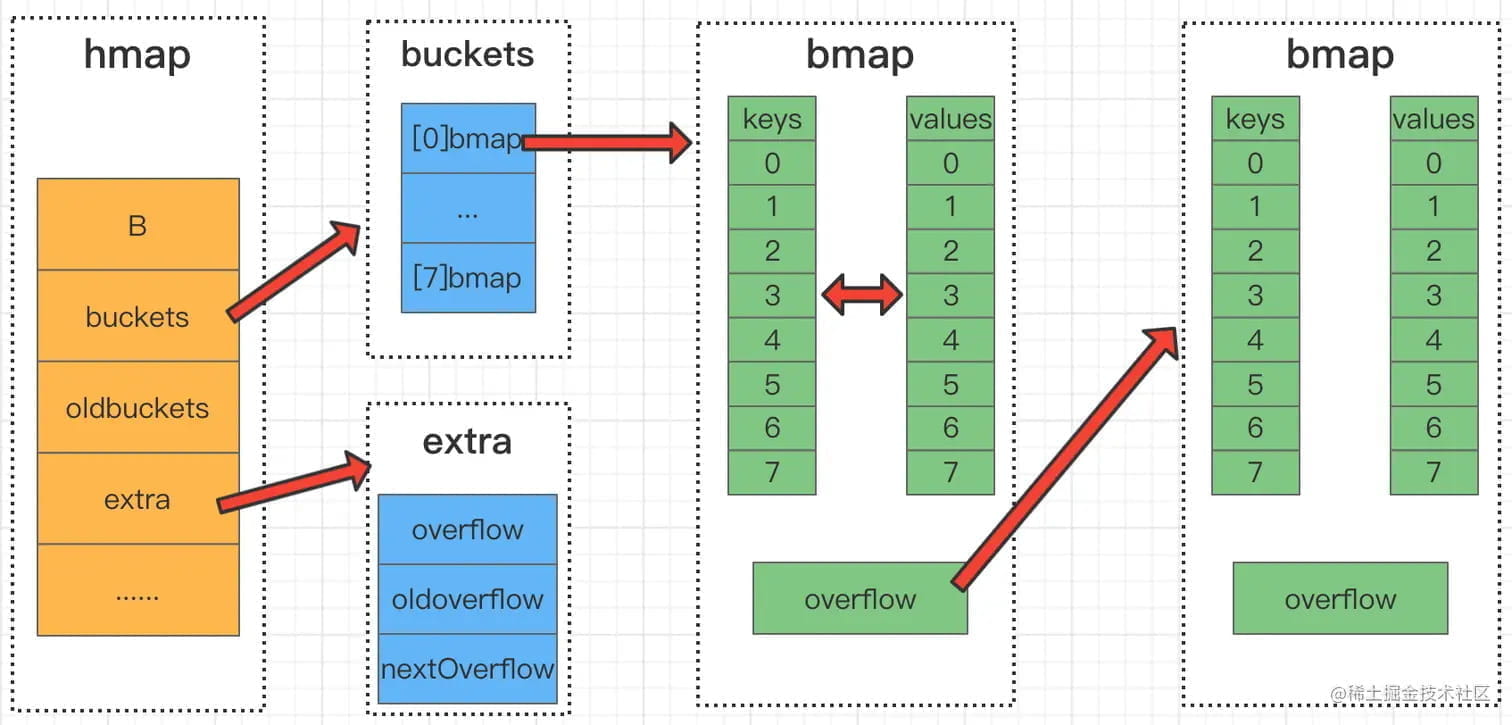
hmap 是 map 的顶层结构,维护着桶数组。每个桶是 bmap 结构,可存储 8 个键值对。当桶内 8 个位置已满且有新 key 落入此桶时,会通过 overflow 指针链接到溢出桶。
关键点:
- hmap 不存储实际数据,只维护桶数组和元信息
- 实际数据存储在 bmap 中
- 每个桶固定 8 个槽位,超出部分使用溢出桶链表
1.2 数据插入
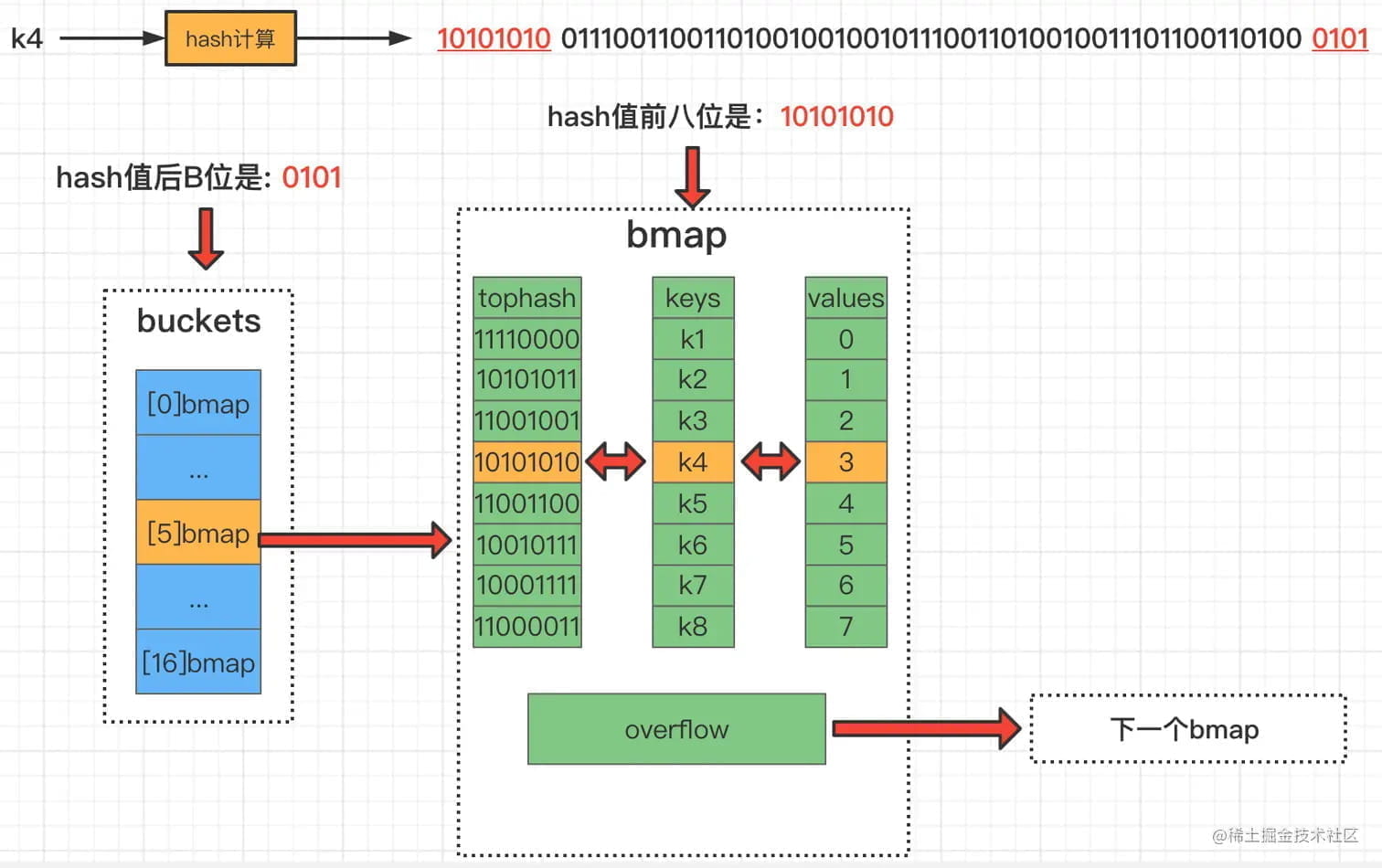
- 计算 hash 值:对 key 计算哈希值
- 定位桶:hash 值的低 B 位决定桶编号
- 定位槽位:hash 值的高 8 位(tophash)用于在桶内快速定位
- 插入:从前往后找到第一个空位插入
- 处理溢出:如果 8 个位置都满,创建溢出桶
哈希冲突处理:当两个不同的 key 落入同一个桶,从前往后遍历找到空位插入。如果桶内 8 个位置都满,链接到溢出桶继续处理。
1.3 数据查询
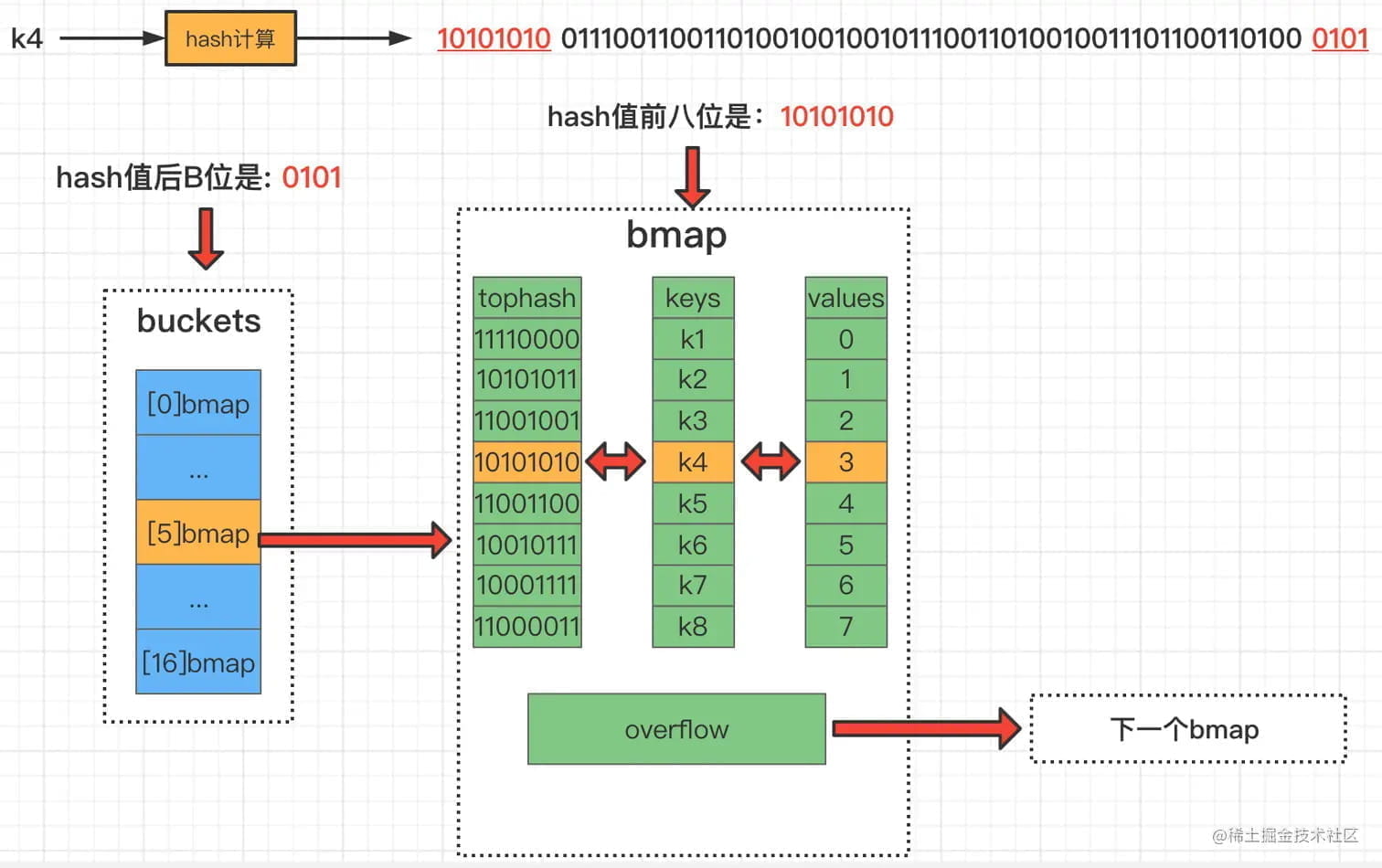
- 计算 hash 值:对 key 计算哈希值
- 定位桶:hash 值的低 B 位确定桶编号
- 快速匹配:用 hash 高 8 位(tophash)快速过滤不匹配的槽位
- 精确匹配:对比完整 hash 值确认 key
- 处理溢出:当前桶未找到,则遍历溢出桶链表
2. 扩容机制
2.1 二倍扩容
当桶数组确实容量不足时触发,扩容后元素会迁移到新桶。
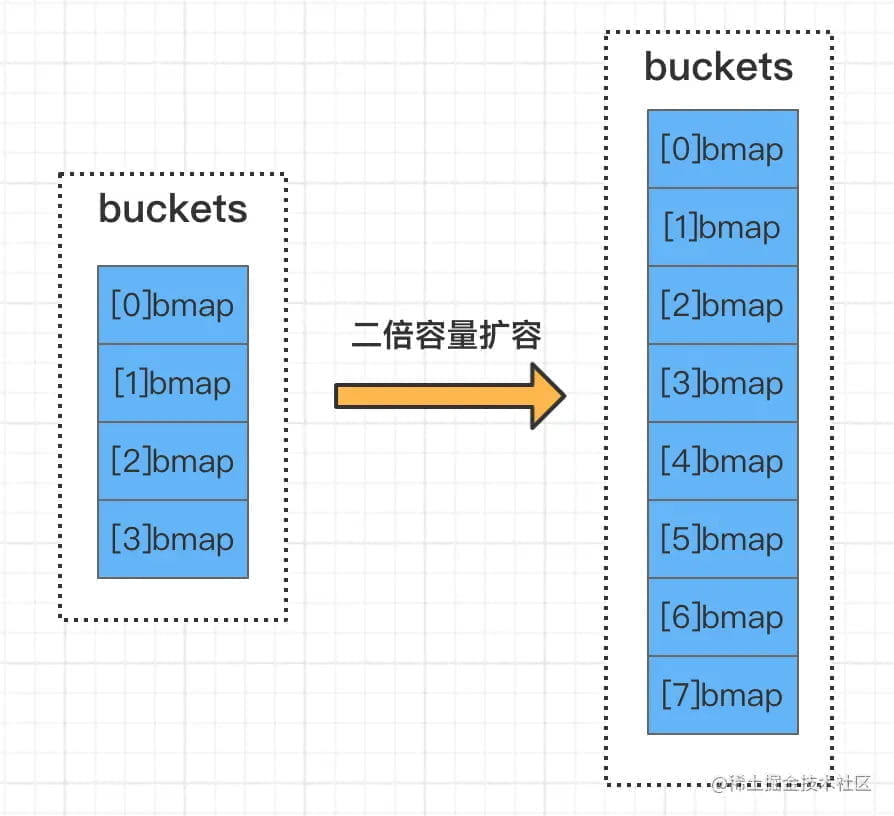
扩容前 B=2(4 个桶),扩容后 B=3(8 个桶)。
迁移规则:hash 值的第 B+1 位决定元素迁移方向。如果该位为 0,元素留在原桶(索引不变);如果为 1,元素迁移到 原索引 + 2^B 的新桶。
例如:hash 值后三位为 101
- 扩容前 B=2,用低 2 位(01)定位,在 1 号桶
- 扩容后 B=3,用低 3 位(101)定位,在 5 号桶(原桶索引 1 + 2^2 = 5)
渐进式扩容流程:
- 扩容触发时,oldbuckets 指向原桶数组,buckets 指向新桶数组
- 每次 map 写操作触发最多 2 个桶的迁移(避免一次性迁移卡顿)
- 扩容未完成期间,读操作会先查 oldbuckets,再查 buckets
- 迁移完成后,释放 oldbuckets
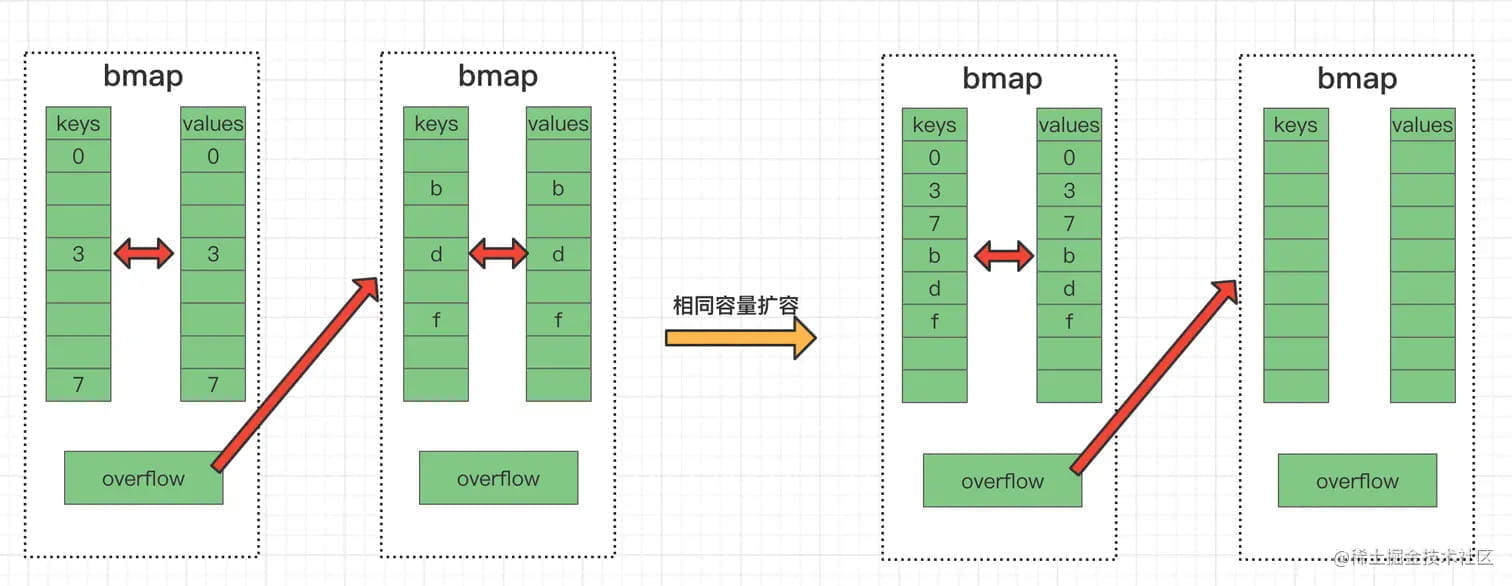
2.2 等量扩容
当溢出桶过多但负载不高时触发,目的是整理碎片,不增加桶数量。
触发场景:频繁的插入和删除操作会导致桶中出现大量断续空位,使得溢出桶链表过长,影响性能。等量扩容将元素重新排列到桶内的连续位置,减少溢出桶。
2.3 扩容触发条件
条件 1:负载因子 ≥ 6.5
每个桶最多 8 个元素。当平均每个桶的元素数达到 6.5 时,触发扩容。
条件 2:溢出桶过多
- B < 15:溢出桶数量 > 2^B
- B ≥ 15:溢出桶数量 > 2^15
当溢出桶过多时,触发等量扩容(B 不变),整理数据减少溢出桶。
3. 关键特性
3.1 Map 元素不可取址
1 | type Student struct { |
原因:map 扩容时会重新分配内存,原来的地址会失效。如果允许取址,扩容后这些地址将指向无效内存,导致数据不一致或程序崩溃。
3.2 线程不安全
多个 goroutine 并发读写同一个 map 是不安全的,会导致数据竞争或 panic。
示例场景:map 有 4 个桶(B=2)
- goroutine2 计算 key2 的 hash 值,定位到 1 号桶
- goroutine1 插入 key1,触发扩容(B=2 → B=3)
- 数据从 buckets 迁移到 oldbuckets
- goroutine2 继续在 1 号桶查找,获取失败
解决方案:使用 sync.Mutex 或 sync.RWMutex 保护 map 操作,或使用 Go 1.9 引入的 sync.Map(适用于特定场景)。
3.3 遍历无序
map 扩容后,key 会在桶之间重新分布。有些 key 会迁移到 原桶索引 + 2^B 的新桶,有些 key 保持不变。因此,扩容前后遍历顺序会发生变化。
为了防止开发者依赖不稳定的遍历顺序,Go 在每次遍历时使用随机起始桶号,确保遍历结果不可预测。
4. 核心要点
- Go 使用拉链法实现 map
- 基本结构:桶数组 + 桶内 key-value 数组 + 溢出桶链表
- key 的 hash 值:低 B 位定位桶,高 8 位(tophash)定位桶内位置
- 每个桶固定 8 个键值对,超出部分使用溢出桶
- 二倍扩容增加桶数量,元素会迁移;等量扩容整理碎片,桶数量不变
- 扩容采用渐进式迁移,避免性能抖动
- map 元素不可取址、线程不安全、遍历无序