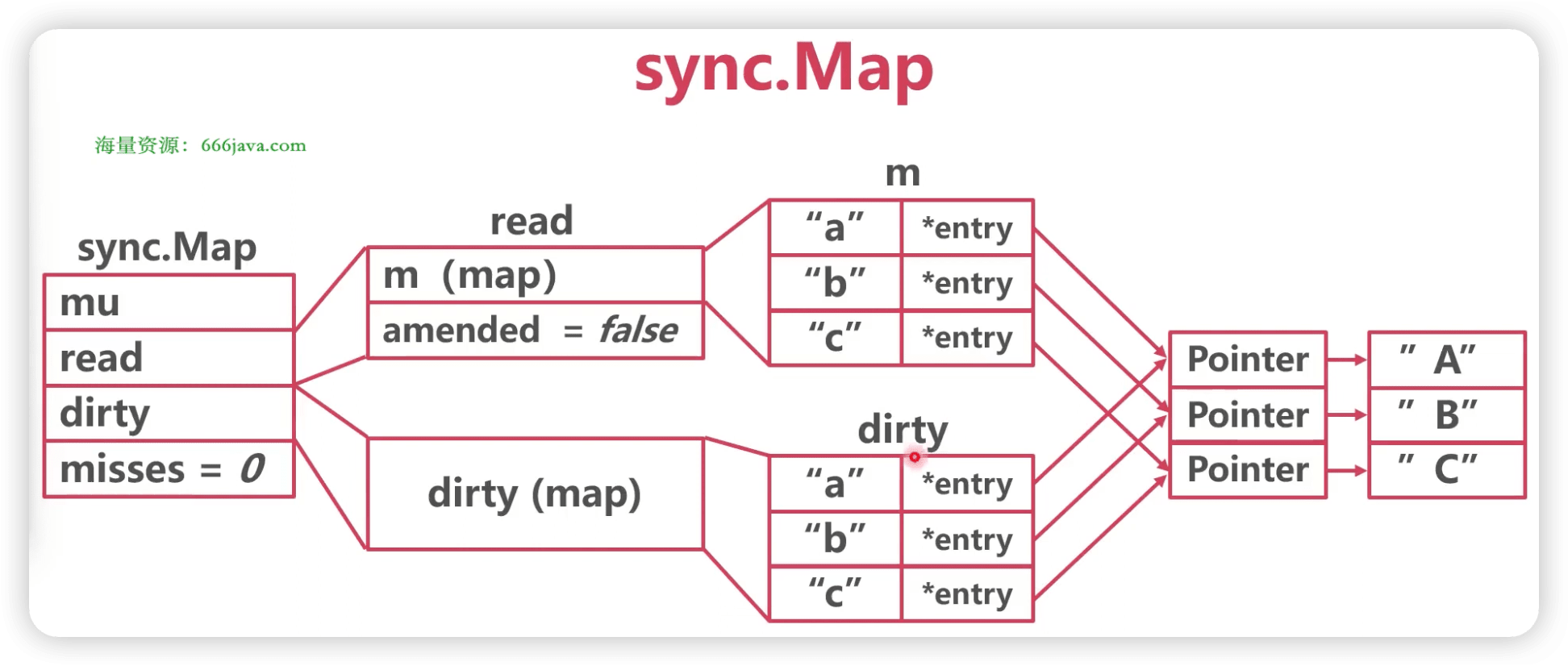
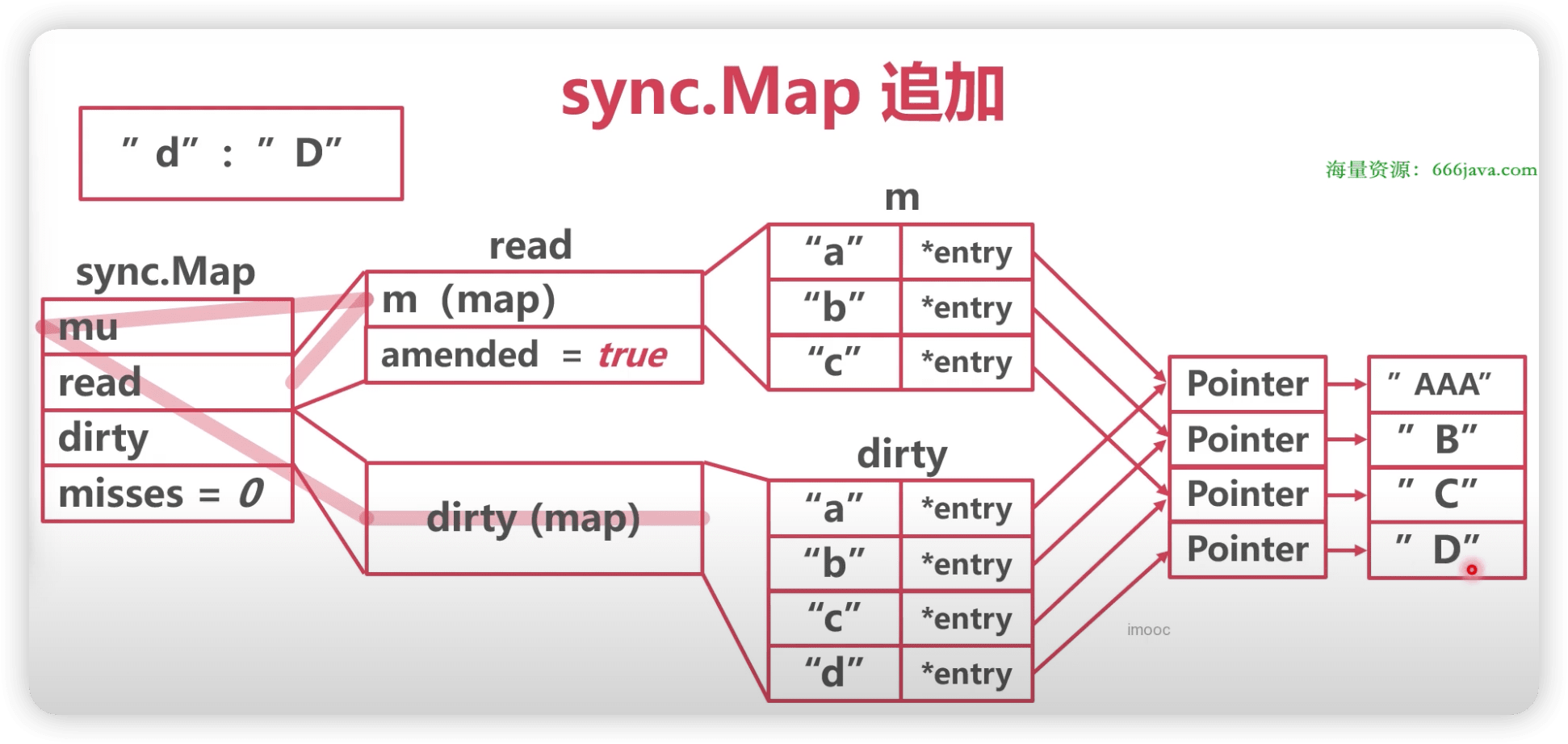
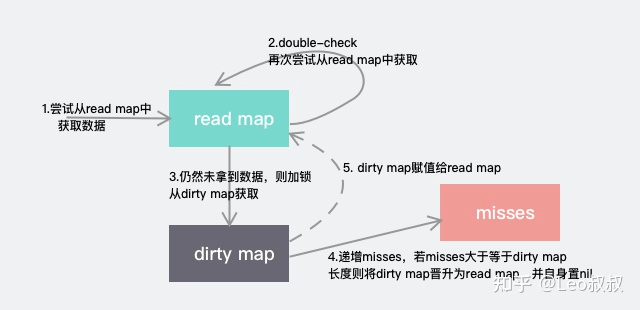
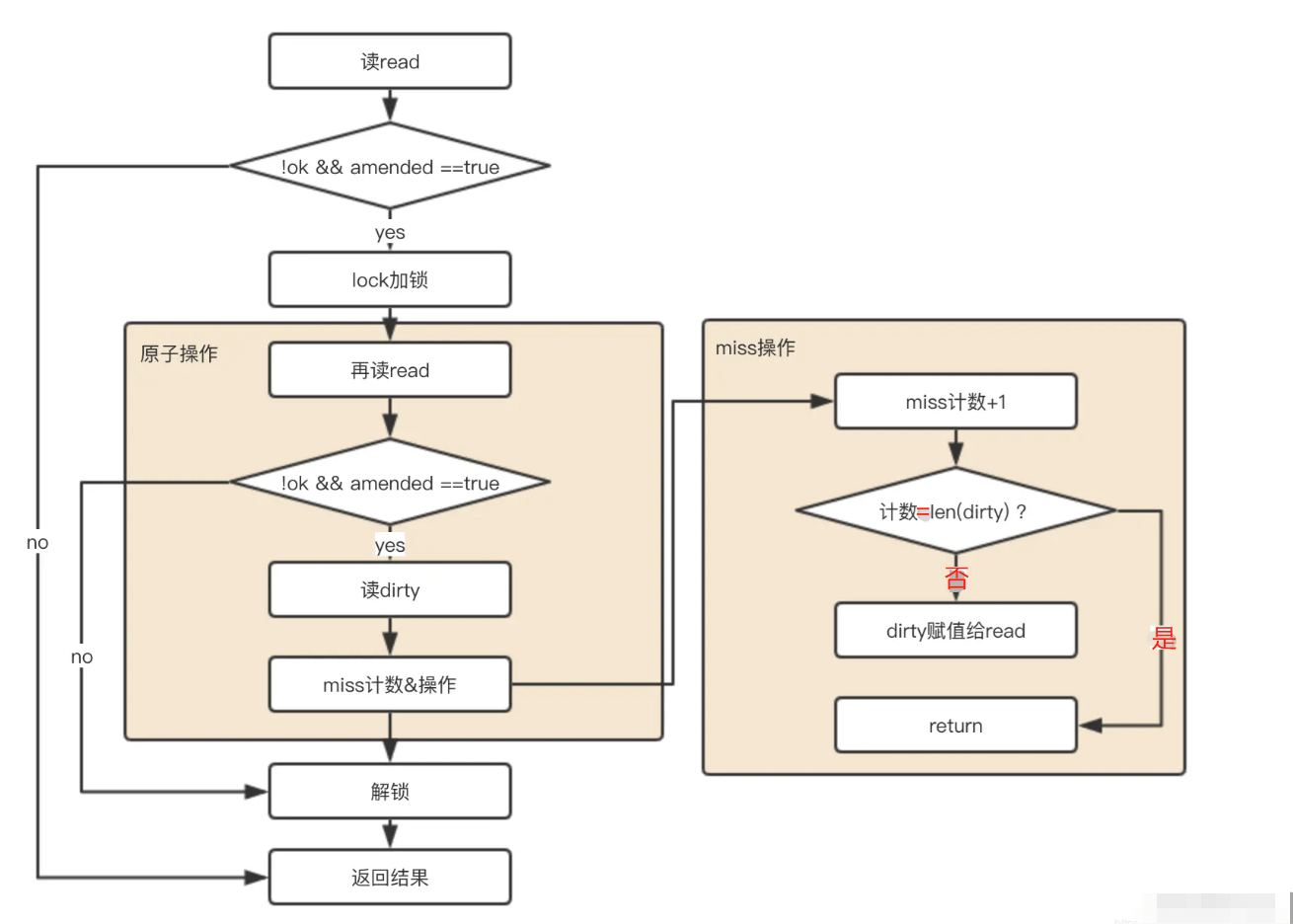
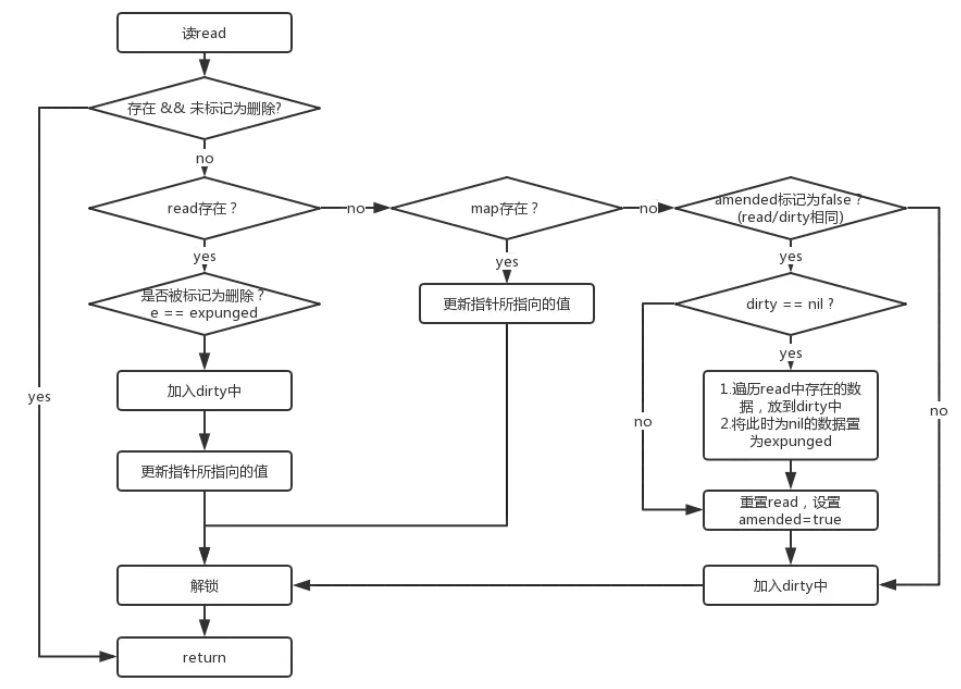
func(m *Map) Store(key, value interface{}) { // 如果m.read存在这个key,并且没有被标记删除,则尝试更新。 read, _ := m.read.Load().(readOnly) if e, ok := read.m[key]; ok && e.tryStore(&value) { return } // 如果read不存在或者已经被标记删除 m.mu.Lock() read, _ = m.read.Load().(readOnly) if e, ok := read.m[key]; ok { // read 存在该key // 如果read值域中entry已删除且被标记为expunge,则表明dirty没有key,可添加入dirty,并更新entry if e.unexpungeLocked() { // 加入dirty中,这里是指针 m.dirty[key] = e } // 更新value值 e.storeLocked(&value) } elseif e, ok := m.dirty[key]; ok { // dirty 存在该 key,更新 e.storeLocked(&value) } else { // read 和 dirty都没有 // 如果read与dirty相同,则触发一次dirty刷新(因为当read重置的时候,dirty已置为 nil了) if !read.amended { // 将read中未删除的数据加入到dirty中 m.dirtyLocked() // amended标记为read与dirty不相同,因为后面即将加入新数据。 m.read.Store(readOnly{m: read.m, amended: true}) } m.dirty[key] = newEntry(value) } m.mu.Unlock() }
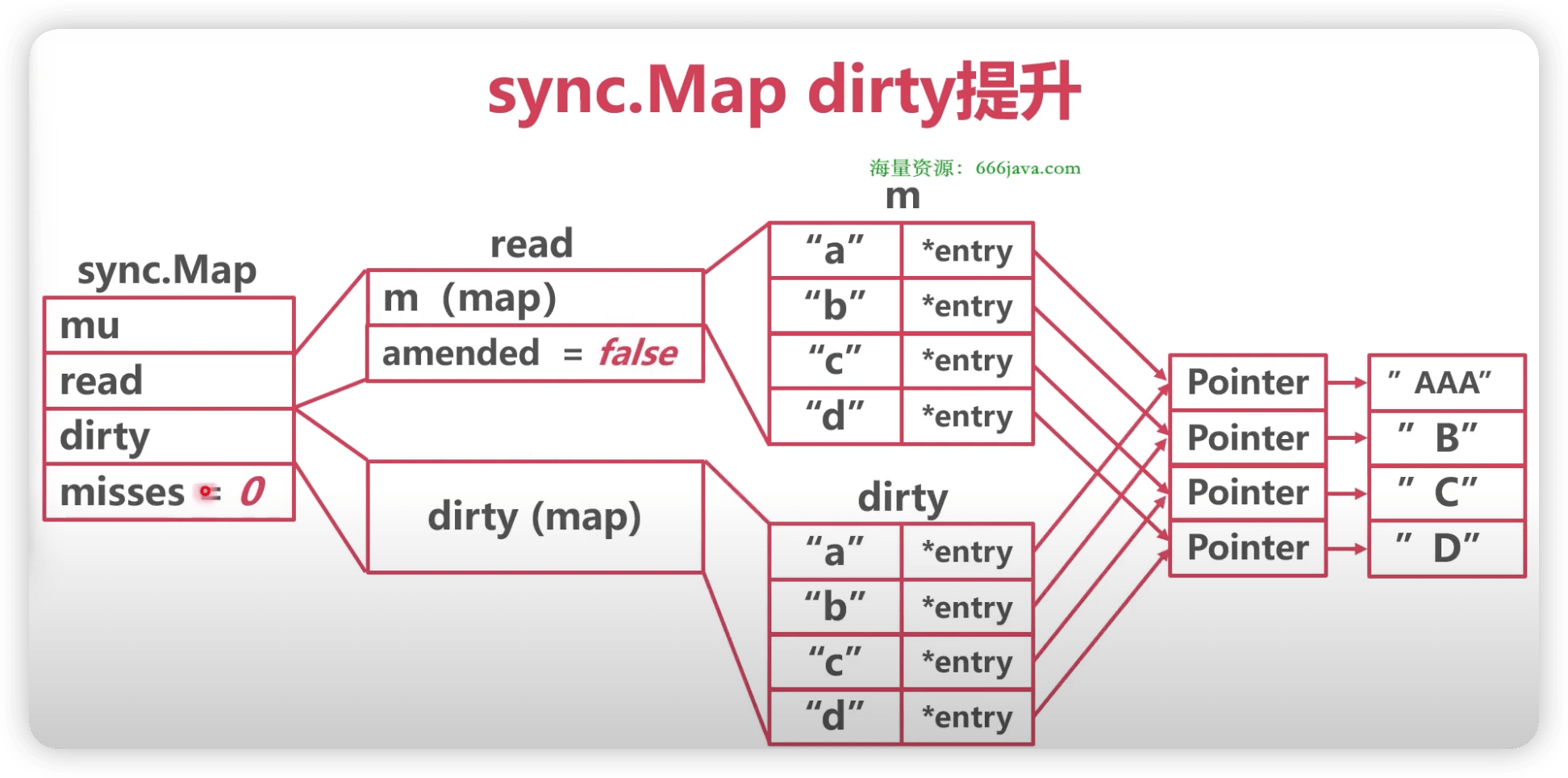
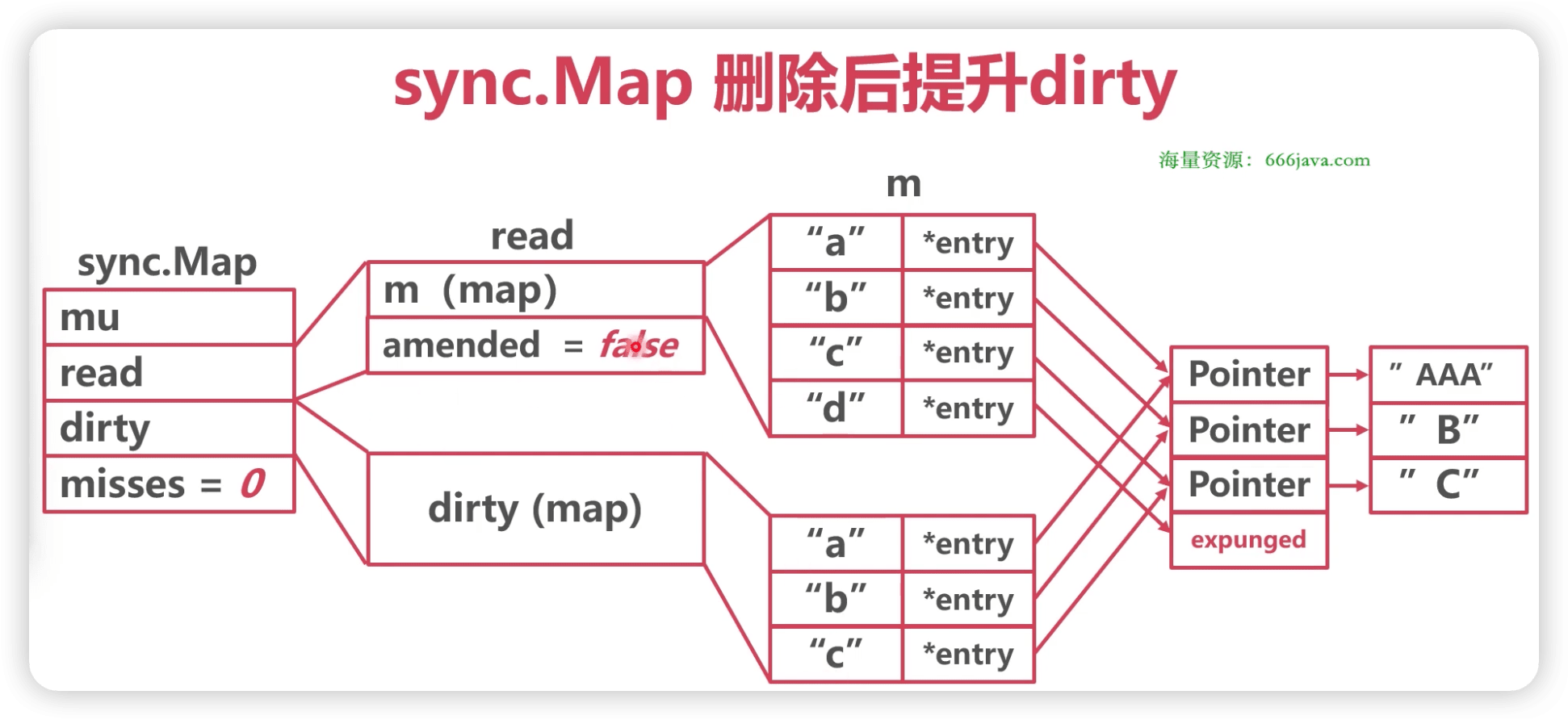
// 将read中未删除的数据加入到 dirty中 func(m *Map) dirtyLocked() { if m.dirty != nil { return } read, _ := m.read.Load().(readOnly) m.dirty = make(map[interface{}]*entry, len(read.m)) // 遍历read。 for k, e := range read.m { // 通过此次操作,dirty中的元素都是未被删除的,可见标记为expunged的元素不在dirty中!!! if !e.tryExpungeLocked() { m.dirty[k] = e } } }
// 判断entry是否被标记删除,并且将标记为nil的entry更新标记为expunge func(e *entry) tryExpungeLocked() (isExpunged bool) { p := atomic.LoadPointer(&e.p) for p == nil { // 将已经删除标记为nil的数据标记为expunged if atomic.CompareAndSwapPointer(&e.p, nil, expunged) { returntrue } p = atomic.LoadPointer(&e.p) } return p == expunged }
// 对entry尝试更新 (原子cas操作) func(e *entry) tryStore(i *interface{}) bool { p := atomic.LoadPointer(&e.p) if p == expunged { returnfalse } for { if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) { returntrue } p = atomic.LoadPointer(&e.p) if p == expunged { returnfalse } } }