url编码问题
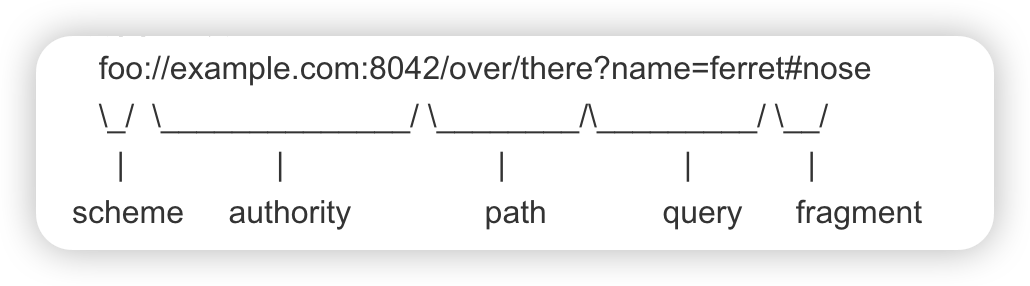 URI 是统一资源标识的意思,通常我们所说的 Url 只是 URI 的一种。典型 Url 的格式如上面所示。下面提到的 Url 编码,实际上应该指的是 URI 编码。
URI 是统一资源标识的意思,通常我们所说的 Url 只是 URI 的一种。典型 Url 的格式如上面所示。下面提到的 Url 编码,实际上应该指的是 URI 编码。
1. 现状
一般来说,URL 只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。比如,世界上有英文字母的网址 “http://www.abc.com",但是没有希腊字母的网址 “http://www.aβγ.com"(读作阿尔法 - 贝塔 - 伽玛.com)。
网络标准 RFC 1738 做了硬性规定:
1 | "...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL." |
1.1 不编码的问题
对于 Url 来说,之所以要进行编码,是因为 Url 中有些字符会引起歧义。例如 Url 参数 ?q=abc&ie=utf-8。如果你的 value 字符串中包含了=或者&,那么势必会造成接收 Url 的服务器解析错误。
又如 Url 的编码格式采用的是 ASCII 码,而不是 Unicode,这也就是说你不能在 Url 中包含任何非 ASCII 字符,例如中文。
1.2 保留字符
1 | Url可以划分成若干个组件,协议、主机、路径等。有一些字符(:/?#[]@)是用作分隔不同组件的。例如:冒号用于分隔协议和主机,/用于分隔 主机和路径,?用于分隔路径和查询参数,等等。还有一些字符(!$&'()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中 的键值对,&符号用于分隔查询多个键值对。当组件中的普通数据包含这些特殊字符时,需要对其进行编码。 |
1.3 不安全字符
还有一些字符,当他们直接放在 Url 中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。
| 字符 | 原因 |
|---|---|
| 空格 | Url 在传输的过程,或者用户在排版的过程,或者文本处理程序在处理 Url 的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉 |
| 引号以及<> | 引号和尖括号通常用于在普通文本中起到分隔 Url 的作用 |
| # | 通常用于表示书签或者锚点 |
| % | 百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码 |
| {}|^[]`~ | 某一些网关或者传输代理会篡改这些字符 |
1.4 规则
Url 中只允许使用可打印字符。US-ASCII 码中的 10-7F 字节全都表示控制字符,这些字符都不能直接出现在 Url 中。同时,对于 80-FF 字节(ISO-8859-1),由于已经超出了 US-ACII 定义的字节范围,因此也不可以放在 Url 中。
需要注意的是,对于 Url 中的合法字符,编码和不编码是等价的,但是对于上面提到的这些字符,如果不经过编码,那么它们有可能会造成 Url 语义的不同。
因此对于 Url 而言,只有普通英文字符和数字,特殊字符还有保留字符,才能出现在未经编码的 Url 之中。其他字符均需要经过编码之后才能出现在 Url 中。
2. 百分号编码
Url 编码通常也被称为百分号编码(Url Encoding,also known as percent-encoding),是因为它的编码方式非常简单,使用% 百分号加上两位的字符——0123456789ABCDEF——代表一个字节的十六进制形式。Url 编码默认使用的字符集是 US-ASCII。例如 a 在 US-ASCII 码中对应的字节是 0x61,那么 Url 编码之后得到的就是%61,我们在地址栏上输入 http://g.cn/search?q=%61%62%63 实际上就等同于在 google 上搜索 abc 了。
2.1 保留字符的 Url 编码
| ! | * | “ | ‘ | ( | ) | ; | : | @ | & |
|---|---|---|---|---|---|---|---|---|---|
%21 | %2A | %22 | %27 | %28 | %29 | %3B | %3A | %40 | %26 |
| = | + | $ | , | / | ? | % | # | [ | ] |
%3D | %2B | %24 | %2C | %2F | %3F | %25 | %23 | %5B | %5D |
2.2 Unicode 字符编码
对于非 ASCII 字符,需要使用 ASCII 字符集的超集进行编码得到相应的字节,然后对每个字节执行百分号编码。 对于 Unicode 字符,RFC 文档建议使用 utf-8 对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如 “ 中文 “ 使用 UTF-8 字符集得到 的字节为 0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过 Url 编码之后得到 “%E4%B8%AD%E6%96%87”。
如果某个字节对应着 ASCII 字符集中的某个非保留字符,则此字节无需使用百分号表示。例如 “Url 编码 “,使用 UTF-8 编码得到的字节是 0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由于前三个字节对应着 ASCII 中的非保留字符 “Url”,因此这三个字节可以用非保留字符 “Url” 表示。最终的 Url 编码可以简化成 “Url%E7%BC%96%E7%A0%81” ,当然,如果你用 “%55%72%6C%E7%BC%96%E7%A0%81” 也是可以的。
3. Js 的编码函数
Javascript 中提供了 3 对函数用来对 Url 编码以得到合法的 Url,它们分别是 escape / unescape,encodeURI / decodeURI 和 encodeURIComponent / decodeURIComponent。由于解码和编码的过程是可逆的,因此这里只解释编码的过程。
下面的表格列出了这三个函数的安全字符(即函数不会对这些字符进行编码)
| 安全字符 | |
|---|---|
| escape(69 个) | */@+-._0-9a-zA-Z |
| encodeURI(82 个) | !#$&’()*+,/:;=?@-.*~0-9a-zA-Z |
| encodeURIComponent(71 个) | !’()*-.*~0-9a-zA-Z |
3.1 对 Unicode 字符的编码方式不同
对于 Unicode 字符,escape 的编码方式是%u_xxxx_,其中的 xxxx 是用来表示 unicode 字符的 4 位十六进制字符。这种方式已经被 W3C 废弃了。但是在 ECMA-262 标准中仍然保留着 escape 的这种编码语法。
encodeURI 和 encodeURIComponent 则使用 UTF-8 对非 ASCII 字符进行编码,然后再进行百分号编码。这是 RFC 推荐的。因此建议尽可能的使用这两个函数替代 escape 进行编码。
3.2 encodeURI 和 encodeURIComponent
encodeURI() 着眼于对整个 URL 进行编码,特殊含义的符号 “; / ? : @ & = + $ , #” 不进行编码
encodeURIComponent() 对 URL 的组成部分进行个别编码,所以 “; / ? : @ & = + $ , #” 在这里是可以进行编码
1 | <script type="text/javascript"> |