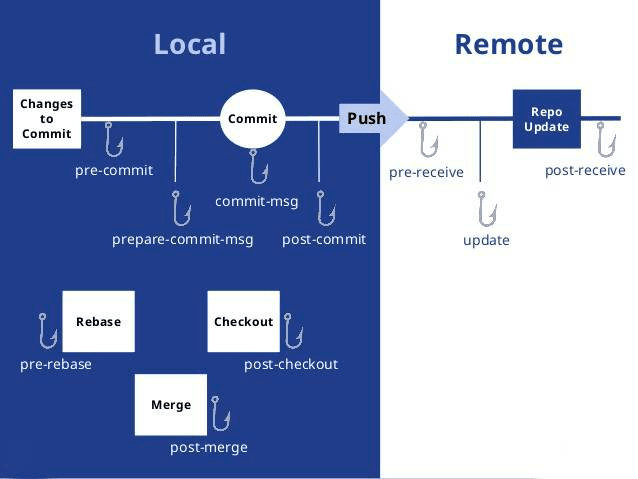
我的知识管理工作流
我的知识管理工作流整体来说非常简单,只有三步:
• I-Inbox:输入,即知识、信息的获取;
• P-Process:加工,即对知识、信息进行要点提取、整合、理解、内化、总结等处理;
• O-Output:输出,即写作、分享并获取反馈。
输入(readwise & raindrop)–> Obsidian同步整合信息 –> 输出(typora + blog)
我的知识管理工作流整体来说非常简单,只有三步:
• I-Inbox:输入,即知识、信息的获取;
• P-Process:加工,即对知识、信息进行要点提取、整合、理解、内化、总结等处理;
• O-Output:输出,即写作、分享并获取反馈。
输入(readwise & raindrop)–> Obsidian同步整合信息 –> 输出(typora + blog)
1 | # 查看健康 |
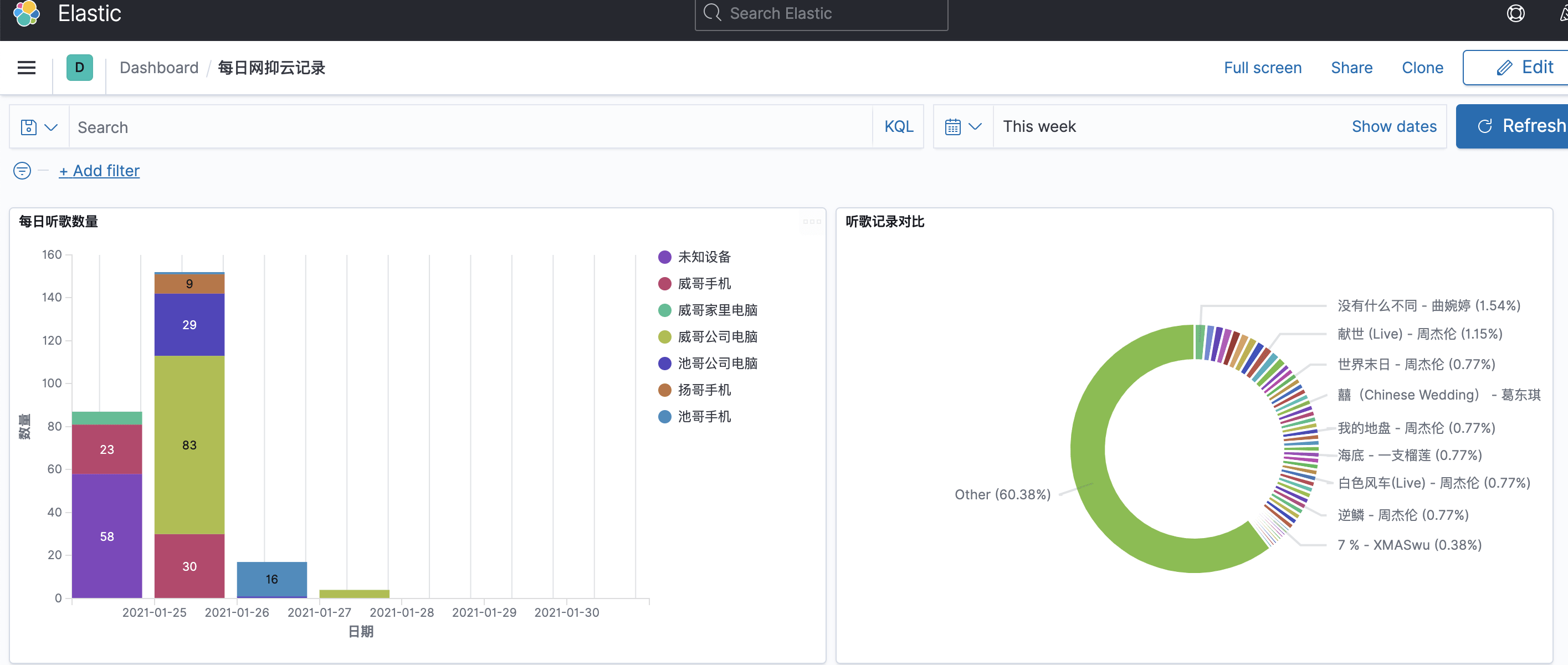
打工人每日网抑云, 所以就用 es简单做个网易云听歌记录. 先上效果图.
当您遇到如下问题时,可以使用分片集群解决:
许多人对复制和分片之间的区别感到困惑。记住,复制在多台服务器上创建了数据的精确副本,因此每台服务器都是其他服务器的镜像。相反,每个分片包含了不同的数据子集。
fzf (Fuzzy Finder) 是一款通用的命令行模糊搜索工具,能够通过模糊匹配关键词快速定位文件、历史命令、进程、Git 提交记录等。
它的核心设计哲学遵循 UNIX 管道理念:作为一个通用的交互式过滤器,接收标准输入(stdin),处理后将结果输出到标准输出(stdout)。这种设计使其能够与 find、grep、history 等任何命令无缝集成。
核心特性:
ripgrep 或 grep 可搜索文件内容。Ctrl + R,将枯燥的历史命令回溯转化为高效的交互式搜索体验。微服务集群中,每个应用基本都会依赖一定数量的外部服务。如果依赖服务过载,服务不可用的情况,在高并发场景下如果此时调用方不做任何处理,继续持续请求故障服务的话很容易引起整个微服务集群雪崩。
所以应该采用熔断的策略,不再调用下游服务。
首先先区分下熔断、限流、降级区别
限流
是针对服务请求数量的一种自我保护机制,当请求数量超出服务负载时,自动丢弃新的请求,是系统高可用架构的第一步。
熔断
是调用方自我保护的机制(客观上也能保护被调用方),熔断对象是外部服务。
降级
是被调用方(服务提供者)的防止因自身资源不足导致过载的自我保护机制,降级对象是自身。
| 触发条件 | 面向目标 | |
|---|---|---|
| 限流 | 上游服务请求多 | 上游 |
| 熔断 | 下游服务不可用 | 下游 |
| 降级 | 服务自身负载高 | 自身 |