分布式ID的snowflake算法
1. Snowflake(雪花算法)
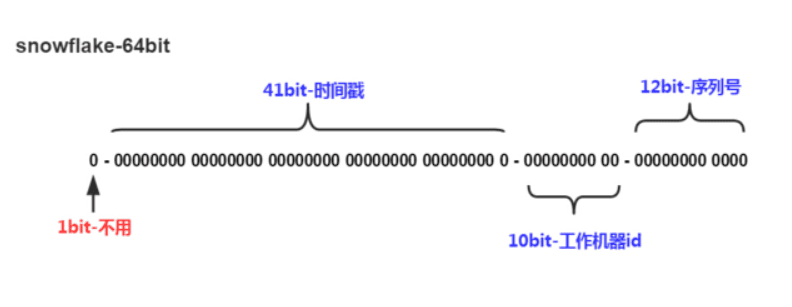
1 | | 1 bit (符号位) | 41 bits (时间戳) | 10 bits (机器 ID) | 12 bits (序列号) | |
- 第 1 位:符号位 (Sign Bit)
- 这 1 位是固定的 0 ,确保生成的 ID 永远是正数。在很多编程语言中,最高位是符号位,0 代表正数,1 代表负数。
- 第 2-42 位:时间戳 (Timestamp)
- 这 41 位用来记录 毫秒级的时间戳 。但它不是直接存储当前的 Unix 时间戳,而是存储 时间戳的差值 (当前时间 - 一个预设的起始时间)。
- 这个设计非常巧妙:
- 节省空间 :41 位可以表示 2^41 - 1 个毫秒数,大约可以使用 (2^41) / (1000 * 60 * 60 * 24 * 365) ≈ 69 年。通过设定一个较近的起始时间(比如项目上线的年份),可以有效延长 ID 的使用寿命。
- 趋势递增 :由于时间戳在高位,所以生成的 ID 基本上是随着时间的推移而递增的。这对于数据库索引等场景非常友好,可以有效减少 B+ 树的页分裂,提高插入性能。
- 第 43-52 位:机器 ID (Worker ID)
- 这 10 位用来标识生成 ID 的机器。 2^10 等于 1024,意味着最多可以支持 1024 台机器同时工作。
- 这 10 位也可以进一步划分,比如前 5 位代表数据中心 ID( 2^5 =32 个数据中心),后 5 位代表该数据中心的机器 ID( 2^5 =32 台机器),这样扩展性和管理性更强。
- 正是因为有了机器 ID,Snowflake 才能在分布式环境下保证不同机器生成的 ID 不会冲突。
- 第 53-64 位:序列号 (Sequence Number)
- 这 12 位是 同一台机器、同一个毫秒内 生成不同 ID 的关键。
- 2^12 等于 4096,意味着一台机器在 1 毫秒内最多可以生成 4096 个不同的 ID。
- 当同一毫秒内有新的 ID 生成请求时,这个序列号就会从 0 开始自增。如果 1 毫秒内生成的 ID 超过了 4096 个,算法会等待到下一毫秒,序列号重置为 0,继续生成。
- 这保证了高并发下的唯一性。
2. 原理
2.1 解决了什么问题
在单机时代,给数据分配唯一 ID 很简单,用数据库的自增主键(1, 2, 3…)就行。但当你的业务火爆到需要上百台服务器同时写入数据时,问题就来了:
- ID 冲突:服务器 A 和服务器 B 可能在同一时刻都想生成 ID
101,怎么办? - 性能瓶颈:如果让一台中心服务器专门发号,那它很快就会成为整个系统的瓶颈。
- 无序性问题:我们通常希望新创建的数据 ID 在数值上也比老数据大,这样数据库索引效率更高,也便于排序。常见的替代方案 UUID (例如
f47ac10b-58cc-4372-a567-0e02b2c3d479) 是无序的,且太长,占用存储空间。
Snowflake 算法优雅地解决了以上所有问题:它不依赖中央协调(高性能、高可用),生成的 ID 全局唯一,并且因为内含了时间戳,所以它是按时间趋势递增的,对数据库非常友好。
2.2 注意事项
- 时钟同步是生命线:整个算法强依赖于机器的时间戳。如果服务器时钟发生回拨(比如手动修改或 NTP 校准导致时间倒退),可能会生成重复的 ID!必须部署 NTP 服务来保证所有服务器时钟基本同步。
- 数据中心和机器 ID 的分配:这 10 位 ID 必须在你的整个分布式系统中是唯一且固定的。不能让两台机器拿到同一个 ID 配置。通常可以通过配置文件、启动参数、或 Zookeeper/Etcd 等配置中心来统一管理和分配。
- 前端精度丢失:JavaScript 的
Number类型无法精确表示完整的 64 位整数(最大安全整数是2^53 - 1)。如果直接把 Snowflake ID(long类型)传给前端,会丢失精度。最佳实践是在后端将 64 位长整型转换为字符串再传给前端。 - 从 ID 反解信息:你可以编写一个工具函数,输入一个 Snowflake ID,就能反解析出它的生成时间、数据中心ID和机器ID。这在排查问题时非常有用(例如:“这个异常订单是哪个机房的哪台机器在什么时候生成的?”)。
2.3 Snowflake vs UUID
很多人会问:“既然有 UUID,为什么还要用 Snowflake?” 它们是解决唯一 ID 问题的两种不同思路。
| 特性 (Feature) | Snowflake (雪花算法) | UUID (通用唯一识别码) |
|---|---|---|
| 结构 (Structure) | 64位整数 (long) | 128位,通常表示为32个十六进制字符和4个连字符 |
| 有序性 (Sortability) | 趋势递增,对数据库索引友好 | 完全无序(除了少数特殊版本的UUID) |
| 长度 (Length) | 8字节 | 16字节 (作为字符串存储则更长,约36字节) |
| 可读性 (Readability) | 纯数字,但可从中反解出时间、机器ID等信息 | 随机字符串,人类几乎不可读 |
| 生成性能 (Performance) | 极高,纯内存计算,单机可达400万/秒 | 也很高,但通常涉及更多系统调用,略慢于Snowflake |
| 适用场景 (Use Case) | 业务ID(订单号、消息ID),需要排序和高性能的场景 | 任何需要唯一标识符的地方,尤其是不关心排序的场景(如文件名、对象标识) |
总结:当你需要一个既唯一又能按时间排序的、对性能和存储有要求的数字 ID 时,选 Snowflake。如果只是需要一个“随便什么都行,只要不重复”的标识符,UUID 更简单方便。
3. 问题
3.1 工作机器 Id 重复怎么办?
ID 冲突的后果很严重,因此解决方案的核心在于“预防”,而不是“补救”。 必须设计一套可靠的机制来确保 Worker ID 的唯一性分配。
最原始的方式,在服务的配置文件或启动参数中为每一台实例硬编码一个不同的
Worker ID。利用 Zookeeper / Etcd 等分布式协调服务(业界主流方案)
- 启动时注册:每个服务实例启动时,都在 Zookeeper 的一个预设父路径(如
/snowflake-workers/)下尝试创建一个临时的顺序节点(Ephemeral Sequential Node)。 - 获取唯一 ID:Zookeeper 会保证创建的节点名是唯一的,并且带有一个自增的序号(例如
/snowflake-workers/worker-0000000001)。服务实例只需要截取这个序号(例如1)作为自己的Worker ID。 - 自动回收:由于创建的是临时节点,它与服务实例的会话是绑定的。一旦服务实例宕机或与 Zookeeper 断开连接,这个临时节点就会被 Zookeeper 自动删除。这意味着它所占用的
Worker ID被隐式地释放了,避免了Worker ID的永久性泄露。
优点:全自动、高可用、无单点故障(Zookeeper 本身是集群)。完美解决了动态扩缩容场景下的
Worker ID分配问题。缺点:需要引入并维护一套 Zookeeper/Etcd 集群
- 启动时注册:每个服务实例启动时,都在 Zookeeper 的一个预设父路径(如
3.2 时钟回拨问题怎么解决?
时钟回拨是 Snowflake 的另一个致命伤。它不仅会破坏 ID 的趋势递增性,更有可能导致生成重复的 ID。想象一下,时钟从 T2 回拨到 T1,那么在 T1 到 T2 这个时间段内,算法可能会生成与过去一模一样的 ID。
策略1:直接拒绝服务(抛出异常)
在生成 ID 的函数内部,总是记录上一次生成 ID 时的时间戳
lastTimestamp。牺牲了可用性。在时钟问题解决前,该服务实例将无法提供 ID 生成服务,可能会影响业务。
策略2:等待时钟追赶(自旋等待)
1 | # 伪代码 |
- 在等待期间,生成 ID 的线程会被阻塞,导致 CPU 空转和请求延迟增加。如果回拨时间很长,可能会导致大量请求超时。
策略3:多级防护
- 小幅回拨(<5ms):等待恢复
- 中幅回拨(5ms-1s):使用扩展位或逻辑时钟
- 大幅回拨(>1s):切换备用方案或报警人工介入
4. Golang 实现
4.1 Snowflake
https://github.com/bwmarrin/snowflake
使用单调时钟计算可防止单机时钟漂移。
1 | package main |