redis缓存穿透和大key热key问题
1. 缓存问题
1.1 缓存穿透(透了要用布隆过滤器)
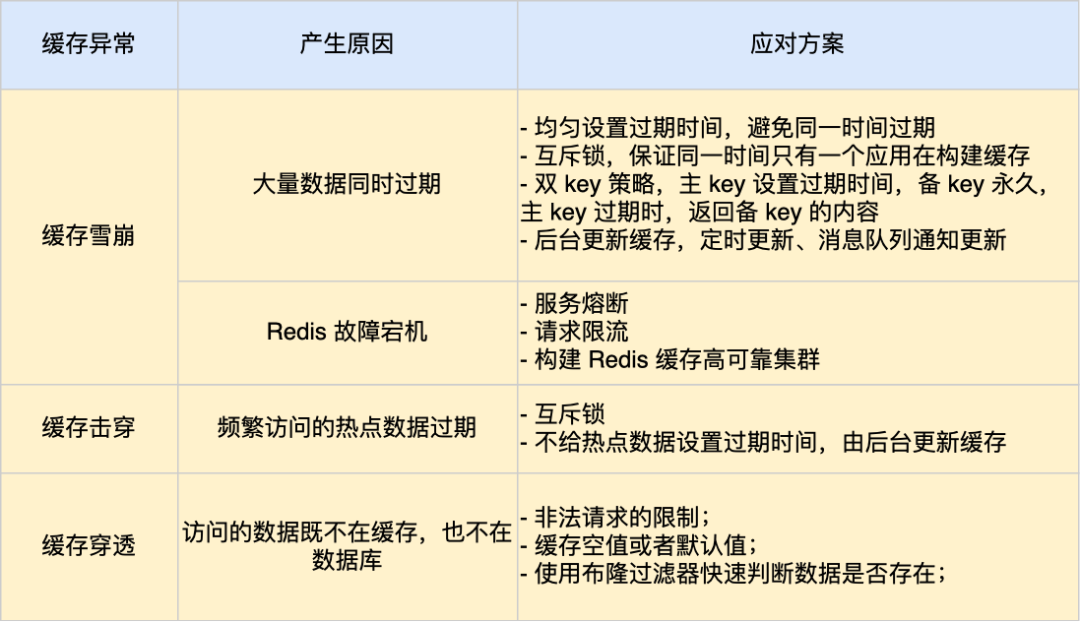
缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解放方案
非法请求的限制
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
缓存空值或者默认值
当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
使用布隆过滤器快速判断数据是否存在
bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。Redis 自身也是支持布隆过滤器的。
布隆过滤器
布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
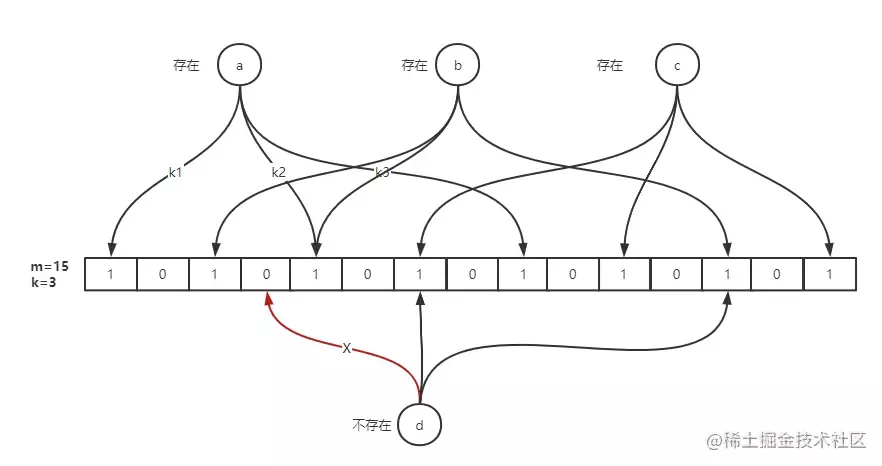
布隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。
位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
当一个元素加入布隆过滤器中的时候
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
1.2 缓存击穿
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题。可以认为缓存击穿是缓存雪崩的一个子集。
解决方案
- 互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
- 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
1.3 缓存雪崩
当大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
解决方案
均匀设置过期时间
对缓存数据设置过期时间时,给这些数据的过期时间加上一个随机数,这样就保证数据不会在同一时间过期。
后台更新缓存
业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。
服务熔断或请求限流机制
我们可以启动服务熔断机制,暂停业务应用对缓存服务的访问,直接返回错误,不用再继续访问数据库,从而降低对数据库的访问压力。
构建 Redis 缓存高可靠集群
如果 Redis 缓存的主节点故障宕机,从节点可以切换成为主节点,继续提供缓存服务,避免了由于 Redis 故障宕机而导致的缓存雪崩问题。
2. key 的问题
2.1 bigkey
通常以Key的大小和Key中成员的数量来综合判定,例如:
- Key本身的数据量过大:一个String类型的Key,它的值为5 MB。
- Key中的成员数过多:一个ZSET类型的Key,它的成员数量为10000个。
- Key中成员的数据量过大:一个Hash类型的Key,它的成员数量虽然只有1000个但这些成员的Value(值)总大小为100 MB。
查找大key
1 | redis-cli -h 127.0.0.1 -p6379 -a "password" -- bigkeys |
解决方案
对大 Key 进行拆分
例如将含有数万成员的一个HASH Key拆分为多个HASH Key,并确保每个Key的成员数量在合理范围。在Redis集群架构中,拆分大Key能对数据分片间的内存平衡起到显著作用。
对大 Key 进行清理
将不适用Redis能力的数据存至其它存储,并在Redis中删除此类数据。Redis 4.0及之后版本:您可以通过 UNLINK 命令安全地删除大Key甚至特大Key,该命令能够以非阻塞的方式,逐步地清理传入的Key。
监控 Redis 的内存水位
可以通过监控系统设置合理的Redis内存报警阈值进行提醒,例如Redis内存使用率超过70%、Redis的内存在1小时内增长率超过20%等。
对过期数据进行定期清理
堆积大量过期数据会造成大Key的产生,例如在HASH数据类型中以增量的形式不断写入大量数据而忽略了数据的时效性。可以通过定时任务的方式对失效数据进行清理。
2.2 hotkey
通常以其接收到的Key被请求频率来判定,例如:
QPS集中在特定的Key:Redis实例的总QPS(每秒查询率)为10,000,而其中一个Key的每秒访问量达到了7,000。
带宽使用率集中在特定的Key:对一个拥有上千个成员且总大小为1 MB的HASH Key每秒发送大量的 HGETALL 操作请求。
CPU使用时间占比集中在特定的Key:对一个拥有数万个成员的Key(ZSET类型)每秒发送大量的 ZRANGE 操作请求。
解决方案
在Redis集群架构中对热Key进行复制
例如将热Key foo复制出3个内容完全一样的Key并名为foo2、foo3、foo4,将这三个Key迁移到其他数据分片来解决单个数据分片的热Key压力。(由原来更新一个Key演变为需要更新多个Key)
使用读写分离架构
如果热Key的产生来自于读请求,您可以将实例改造成读写分离架构来降低每个数据分片的读请求压力,甚至可以不断地增加从节点。但是读写分离架构在增加业务代码复杂度的同时,也会增加Redis集群架构复杂度。
内存预热
是指在系统启动或重启后,主动将热点数据加载到内存中。这样当用户访问这些热点数据时,可以直接从内存中获取,避免对 Redis 造成压力。
2.3 分区不均匀
可能原因:大Key、Hash Tags。
- 大key。对key进行拆分。
HashTag 机制使用{}大括号,指定key只计算大括号内字符串的哈希,从而将不同key的健值对插入到同一个哈希槽。
检查下业务代码,有没有引入HashTag,将太多的key路由到了一个实例。
3. 头脑风暴
缓存穿透:布隆过滤器。缓存击穿:热点数据不过期或加锁。缓存雪崩:随机过期时间。
大key要去做分割,热key要去分片或内存预热,分区不均匀是大key和hashtag机制。