分布式协议和算法
1. 分布式算法
1.1 分布式算法
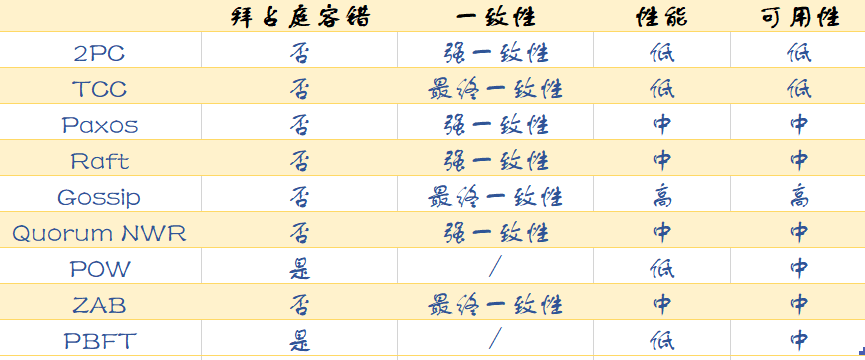
四大维度:拜占庭容错、一致性、性能、可用性。
1.2 拜占庭问题
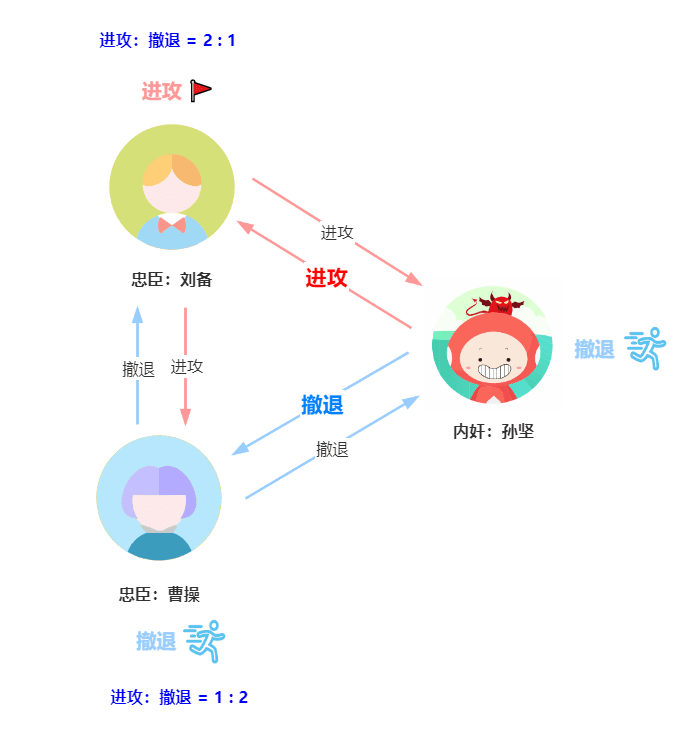
- 刘备决定进攻,通过信使告诉曹操和孙坚进攻。
- 曹操决定撤退,通过信使告诉刘备和孙坚撤退。
- 孙坚作为内奸使诈,通过信使告诉刘备进攻,告诉曹操撤退。
刘备的票数为进攻 2 票,撤退 1 票,曹操的票数为进攻 1 票,撤退 2 票。按照少数服从多数的原则,刘备最后会选择进攻,而曹操会选择撤退,孙坚作为内奸肯定不会进攻,刘备单独进攻反贼董卓,势单力薄,被董卓干掉了。
1.3 拜占庭问题解法
如果叛将人数为 m,将军数 n >= 3m + 1,那么就可以解决拜占庭将军问题。
前提条件:叛将数 m 已知,需要进行 m + 1 轮的作战协商。
比如上述的攻打董卓问题,曹操、刘备、孙坚三个人当中,孙坚是叛将,他可以使诈,使作战计划不统一。必须增加一位忠臣袁绍来协商共识,才能达成一致性作战计划。
可不要小瞧拜占庭问题,它可是分布式场景最复杂的的故障场景。比如在数字货币的区块链技术中就有用到这些知识点。而且必须使用拜占庭容错算法(也就是 Byzantine Fault Tolerance,BFT)。
拜占庭容错算法还有 FBFT 算法,PoW 算法。
有了拜占庭容错算法,肯定有非拜占庭容错算法,顾名思义,就是没有发送误导信息的节点。CFT 算法就是解决分布式系统中存在故障,但不存在恶意节点的场景下的共识问题。简单来说就是可能因系统故障造成丢失消息或消息重复,但不存在错误消息、伪造消息。对应的算法有 Paxos 算法、Raft 算法、ZAB 协议。
这么多算法该如何选择?
节点可信,选非拜占庭容错算法。否则就用拜占庭容错算法,如区块链中用到的 PoW 算法。
1.4 四大维度
拜占庭容错
拜占庭容错就是《拜占庭将军问题》中提出的一个模型,该模型描述了一个完全不可信的场景。不可信体现在:
- 故障行为。比如节点故障了。
- 恶意行为。比如恶意节点冒充正常节点,发出错误指令。
一致性
一致性分为三种:
- 强一致性:保证写操作完成后,任何后续访问都能读到更新后的值。
- 弱一致性:写操作完成后,系统不能保证后续的访问都能读到更新后的值。
- 最终一致性:保证如果对某个对象没有新的写操作,最终所有后续访问都能读到相同的最近更新的值。
在数据库操作层面,我们多使用二阶段提交协议(2PC)保证强一致性。在分布式系统中,多使用 Raft 算法来保证强一致性。
如果考虑可用性,则使用 Gossip 协议实现最终一致性,配合 Quorum NWR 算法的三个参数来调节容错能力。而 zookeeper 基于读性能的考虑,通过 ZAB 协议提供最终一致性。
性能
可用性最强的就是 Gossip 协议了,即时只有一个节点,集群可以提供服务。
然后是 Paxos/Raft/ZAB/Quorum NWR/FBFT/POW 算法,能够容忍部分节点故障。
而 2PC、TCC 要求所有节点都正常运行,系统才能正常工作,可用性最低。
可用性
上面可用性的排序同样适用于性能维度。Gossip 协议可用于 AP 型分布式系统,水平扩展能力强,读写性能最强。
Paxos/Raft/ZAB/Quorum NWR/FBFT/POW 算法都是领导者模型,写性能依赖领导者,读性能依赖一致性的实现。性能处于中等位置。
而 2PC、TCC 实现事务时,需要预留和锁定资源,性能较差。
2. Paxos 算法
Paxos 是分布式算法中的老大哥,可以说 Paxos 是分布式共识的代名词。最常用的分布式共识算法都是基于它改进。比如 Raft 算法。所以学习分布式算法必须先学习 Paxos 算法。
Paxos 算法主要包含两个部分:
- Basic Paxos 算法:多个节点之间如何就某个值达成共识。(这个值我们称作
提案 Value) - Multi-Paxos 算法:执行多个 Basic Paxos 实例,就一系列值达成共识。
2.1 角色
Paxos 中有三种角色:提议者(Proposer)、接受者(Acceptor)、学习者(Learner)。
- 提议者(Proposer):提议一个值,用于投票表决。
- 接受者(Acceptor):对提议的值进行投票,并接受达成共识的值,存储保存。
- 学习者(Learner):不参与投票的过程,接受达成共识的值,存储数据。
有的节点即可以扮演接受者,也可以扮演提议者。
2.2 流程
而 Paxos 算法达成共识分两个阶段。准备(Prepare)阶段和接受(Accept)阶段。
接受者是通过编号达成共识的,当接受者通过了一个提案时,就通知所有的学习者。
2.3 提案编号
提案编号代表优先级,保证了三个承诺:
- 如果
准备请求的提案编号,小于等于接受者已经响应的准备请求的提案编号,那么接受者将承诺不响应这个准备请求。 - 如果
接受请求中的提案的提案编号,小于接受者已经响应的准备请求的提案,那么接受者将承诺不通过这个提案。 - 如果接受者之前有通过提案,那么接受者将承诺,会在
准备请求的响应中,包含已经通过的最大编号的提案信息。


3. Raft 算法
Raft 算法是分布式系统开发首选的共识算法。比如现在流行 Etcd、Consul。Raft 算法是通过一切以领导者为准的方式,实现一系列值的共识和各节点日志的一致。
动画演示:http://thesecretlivesofdata.com/raft/
3.1 角色
跟随者(Follower):默默接收和来自领导者的消息,当领导者心跳信息超时的时候,就主动站出来,推荐自己当候选人。
候选人(Candidate):通知其他节点来投票,如果赢得了大多数投票选票,就晋升当领导者。
领导者(Leader): 处理写请求、管理日志复制和不断地发送心跳信息。
3.2 Leader选举
初始状态下,所有节点都是跟随者的状态。
有三个节点(Node) a、b、c,每个人的任期(Term)都为 0。
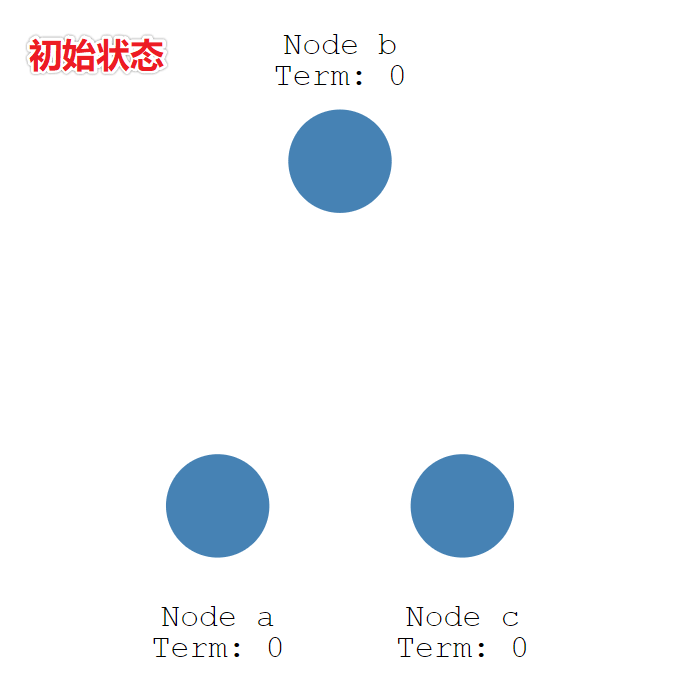
随机超时成为候选人。
Raft 算法每个节点随机超时时间的特性,如下图所示,三个节点的超时计时器开始运行,A 先超时。
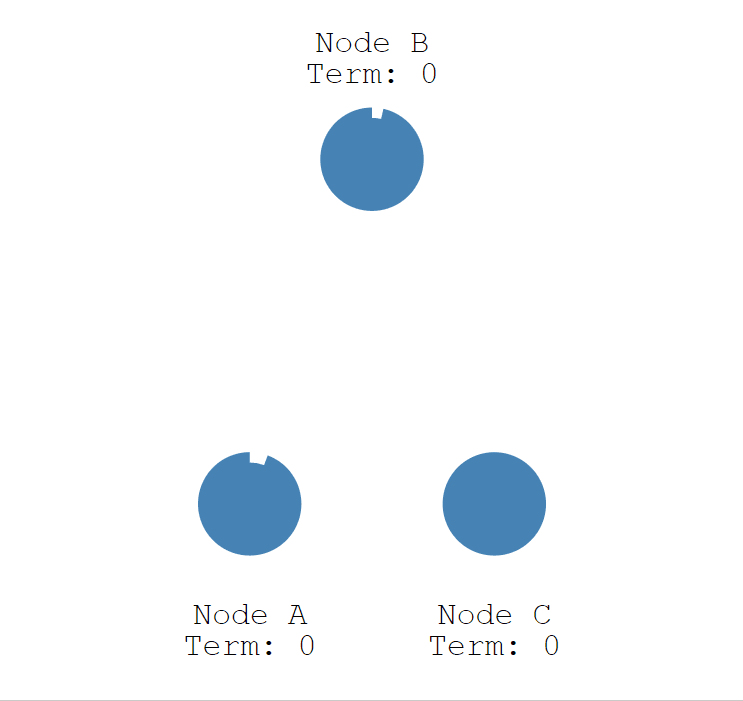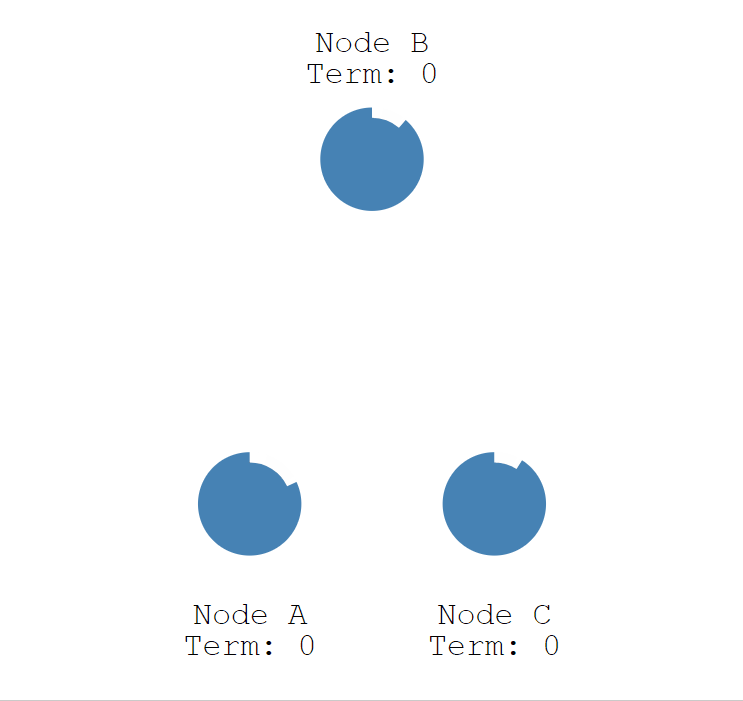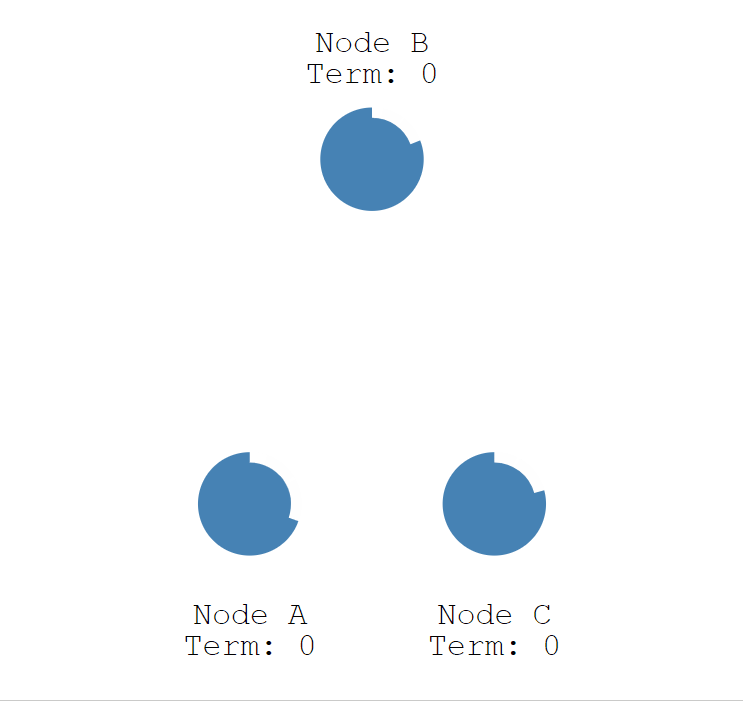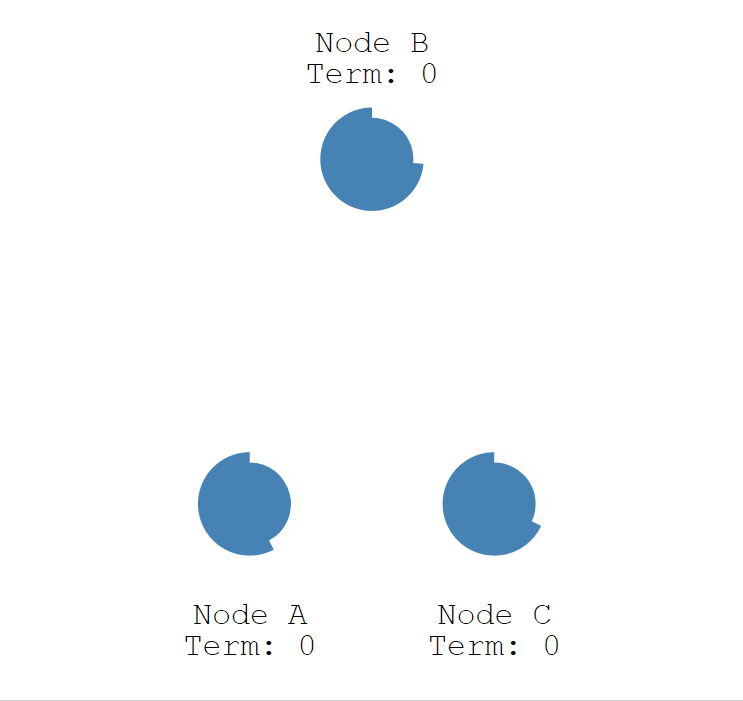
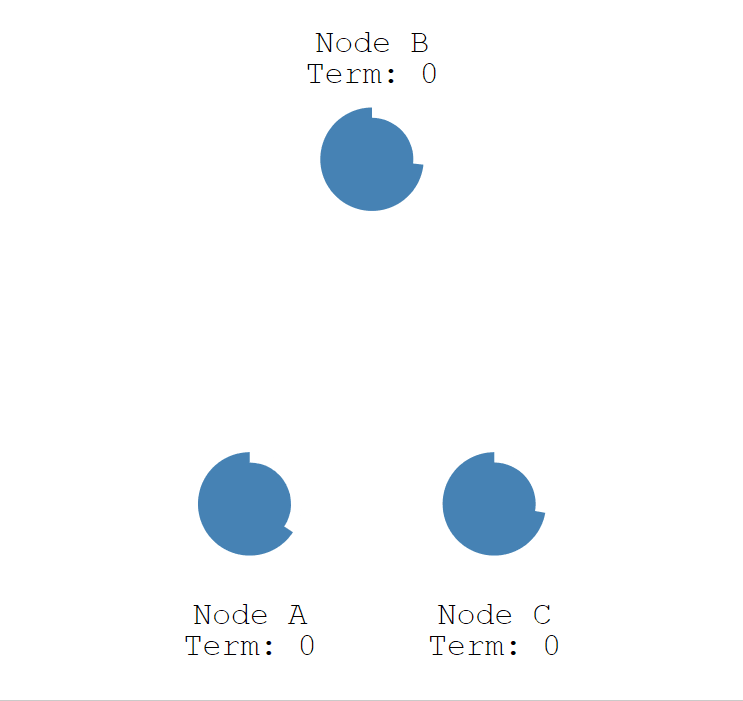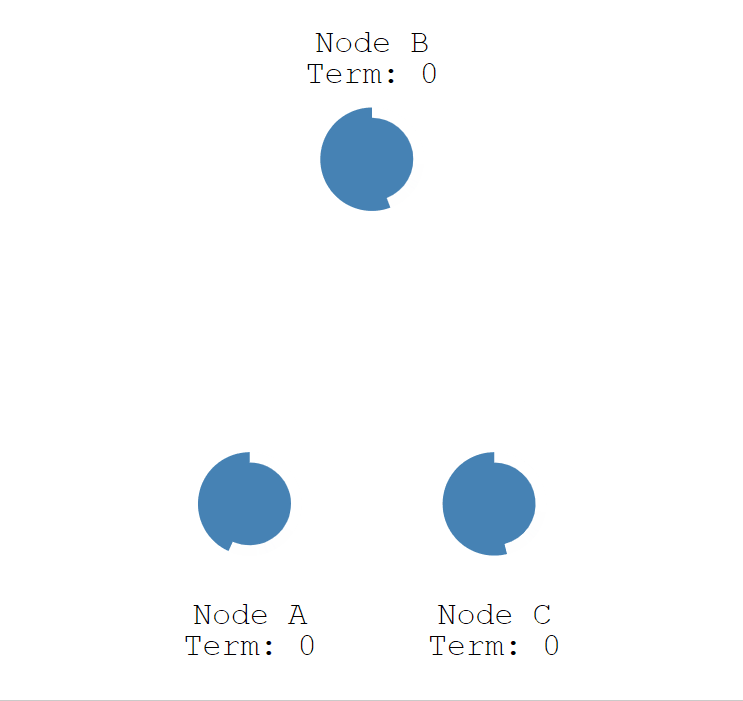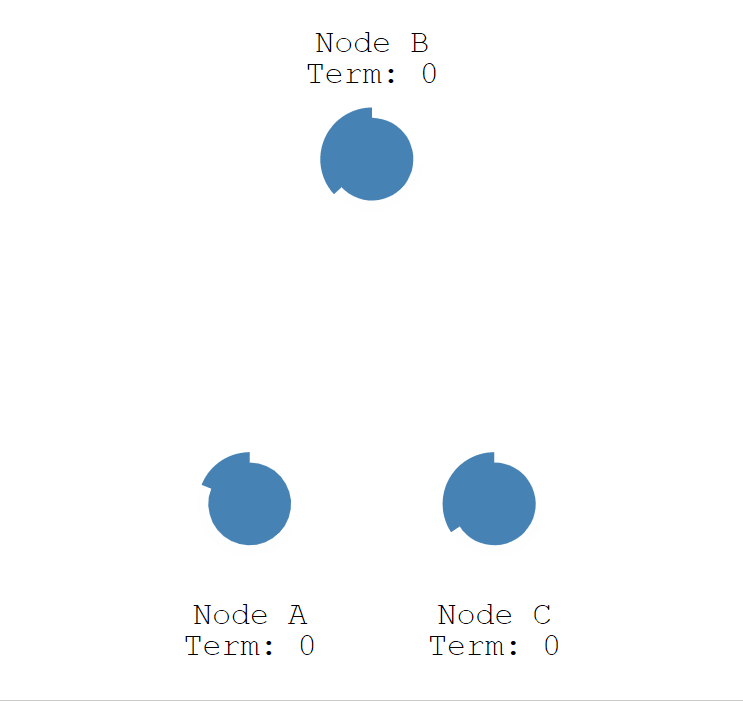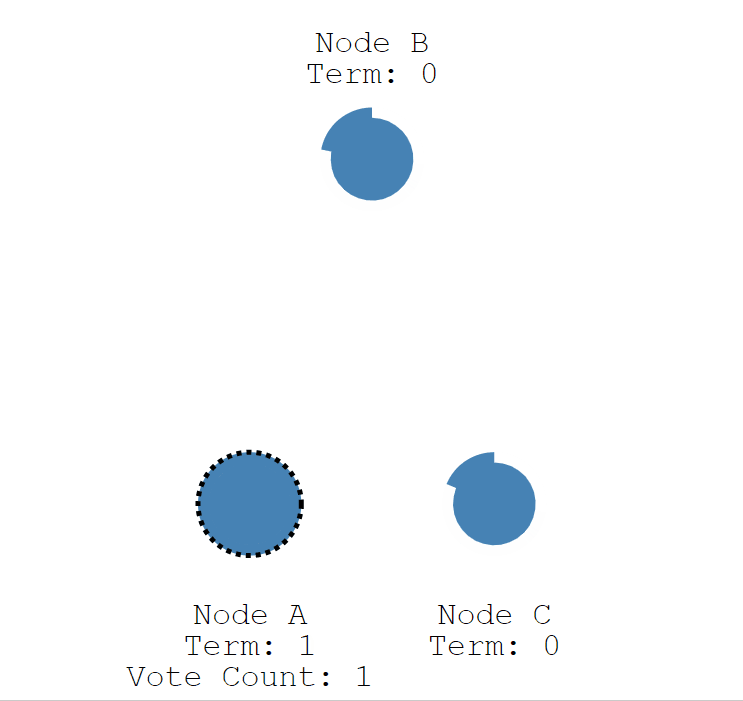
当 A 节点的超时时间到了后,A 节点成为候选者,并增加自己的任期编号,Term 值从 0 更新为 1,并给自己投了一票。
- Node A:Term = 1, Vote Count = 1。
- Node B:Term = 0。
- Node C:Term = 0。
候选者让其他人投票
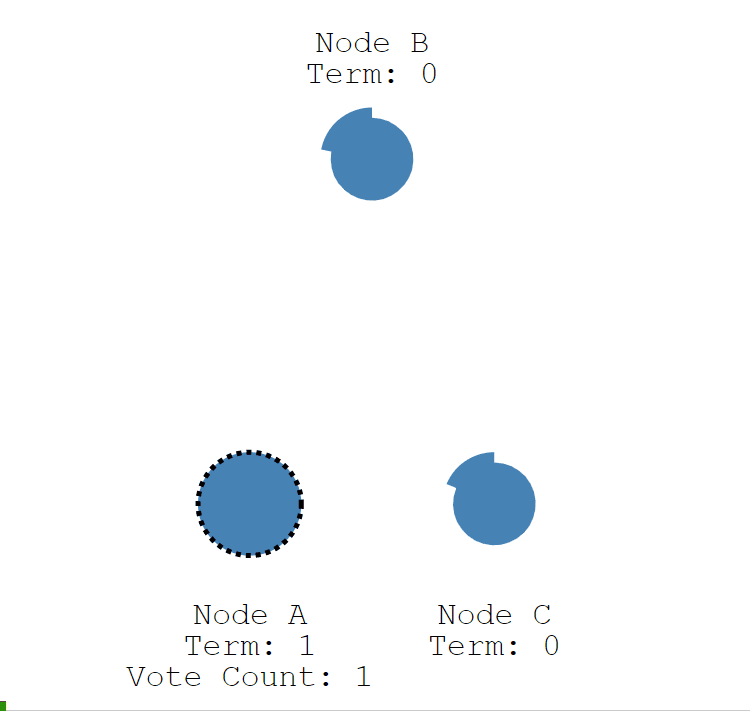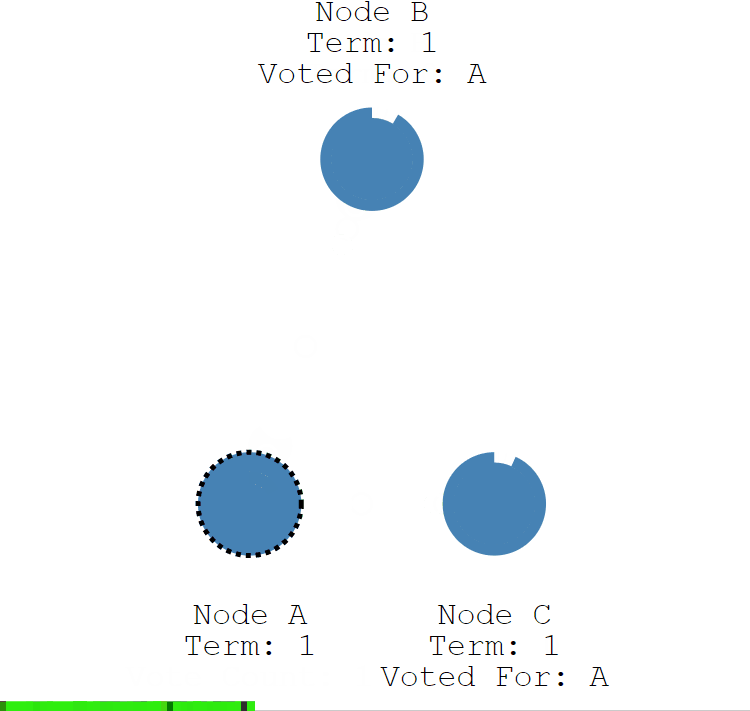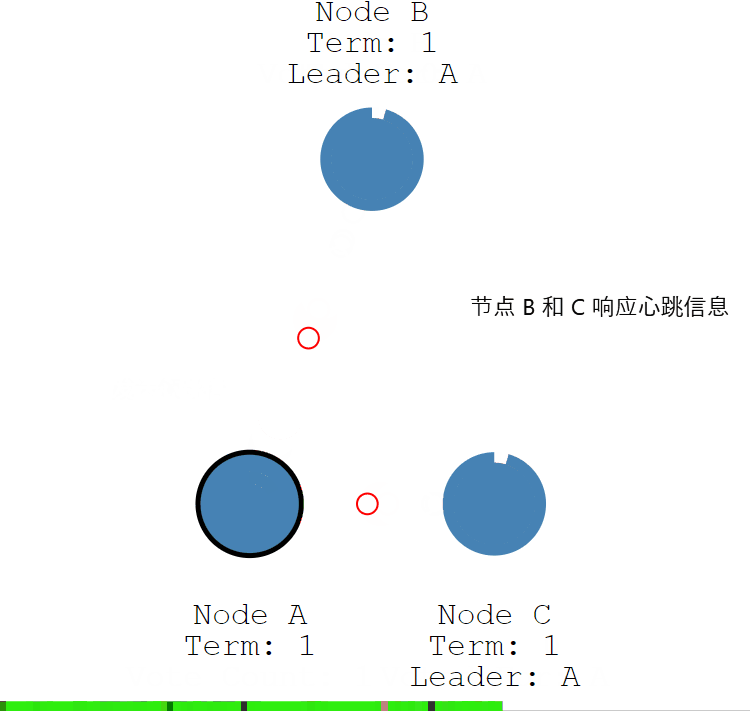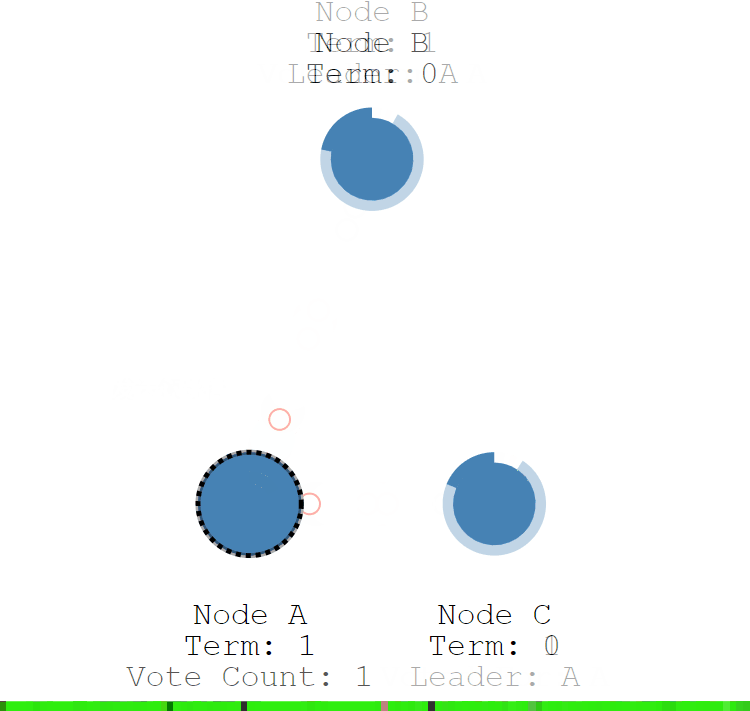
节点 A 成为候选者后,向其他节点发送请求投票 RPC 信息,请它们选举自己为领导者。
节点 B 和 节点 C 接收到节点 A 发送的请求投票信息后,在编号为 1 的这届任期内,还没有进行过投票,就把选票投给节点 A,并增加自己的任期编号。
节点 A 收到 3 次投票,得到了大多数节点的投票,从候选者成为本届任期内的新的领导者。
节点 A 作为领导者,固定的时间间隔给 节点 B 和节点 C 发送心跳信息,告诉节点 B 和 C,我是领导者,组织其他跟随者发起新的选举。
节点 B 和节点 C 发送响应信息给节点 A,告诉节点 A 我是正常的。
1. 任期
英文单词是 term,领导者是有任期的。
- 自动增加:跟随者在等待领导者心跳信息超时后,推荐自己为候选人,会增加自己的任期号,如上图所示,节点 A 任期为 0,推举自己为候选人时,任期编号增加为 1。
- 更新为较大值:当节点发现自己的任期编号比其他节点小时,会更新到较大的编号值。比如节点 A 的任期为 1,请求投票,投票消息中包含了节点 A 的任期编号,且编号为 1,节点 B 收到消息后,会将自己的任期编号更新为 1。
- 恢复为跟随者:如果一个候选人或者领导者,发现自己的任期编号比其他节点小,那么它会立即恢复成跟随者状态。这种场景出现在分区错误恢复后,任期为 3 的领导者受到任期编号为 4 的心跳消息,那么前者将立即恢复成跟随者状态。
- 拒绝消息:如果一个节点接收到较小的任期编号值的请求,那么它会直接拒绝这个请求,比如任期编号为 6 的节点 A,收到任期编号为 5 的节点 B 的请求投票 RPC 消息,那么节点 A 会拒绝这个消息。
2. 大多数
假设一个集群由 N 个节点组成,那么大多数就是至少 N/2+1。例如:3 个节点的集群,大多数就是 2。
3. 领导者故障
如果领导者节点出现故障,则会触发新的一轮选举。如下图所示,领导者节点 A 发生故障,节点 B 和 节点 C 就会重新选举 Leader。
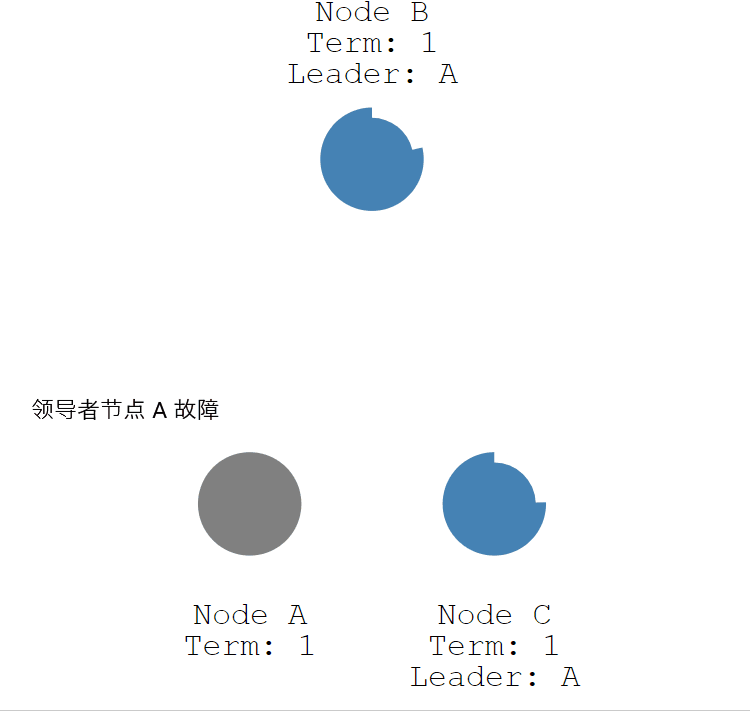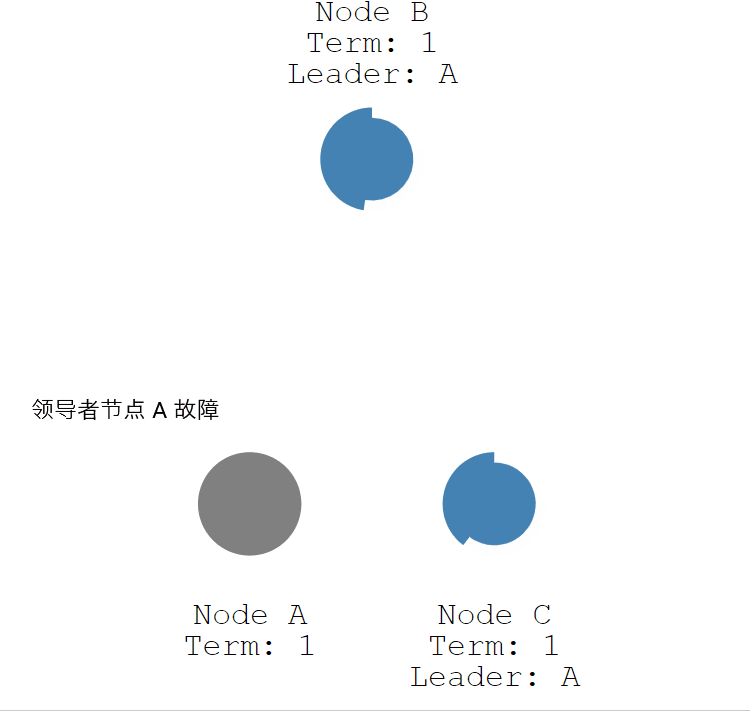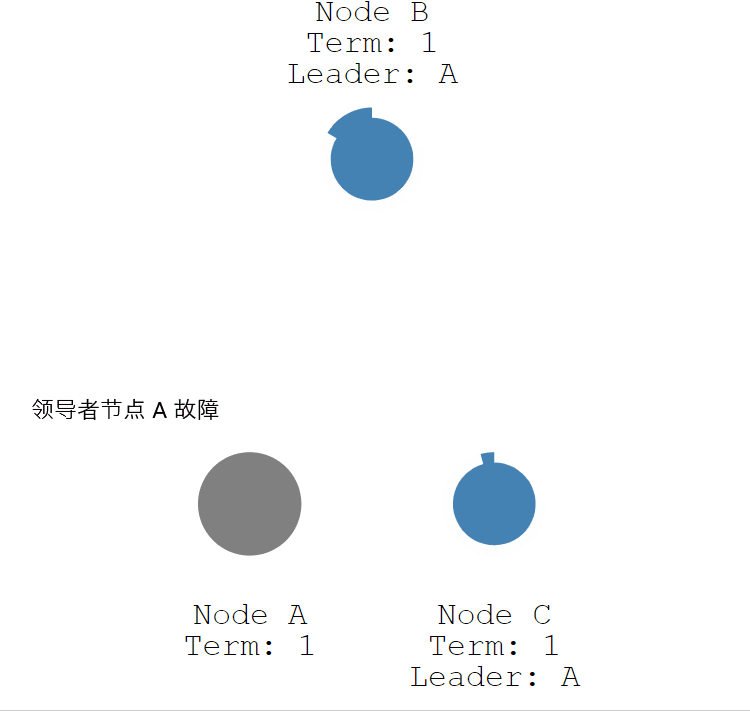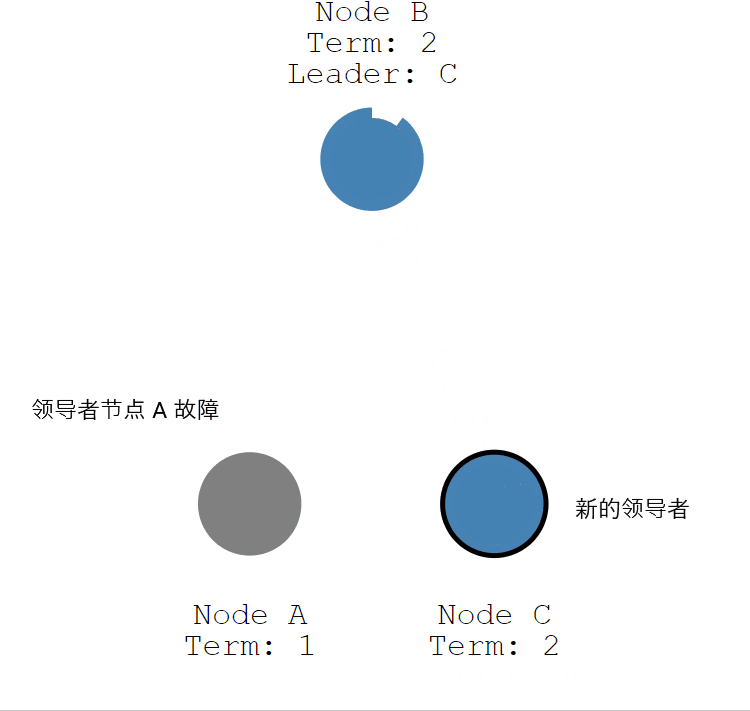
- 节点 A 发生故障,节点 B 和节点 C 没有收到领导者节点 A 的心跳信息,等待超时。
- 节点 C 先发生超时,节点 C 成为候选人。
- 节点 C 向节点 A 和节点 B 发起请求投票信息。
- 节点 C 响应投票,将票投给了 C,而节点 A 因为发生故障了,无法响应 C 的投票请求。
- 节点 C 收到两票(大多数票数),成为领导者。
- 节点 C 向节点 A 和 B 发送心跳信息,节点 B 响应心跳信息,节点 A 不响应心跳信息。
3.3 日志同步
Leader选出后,就开始接收客户端的请求。Leader把请求作为日志条目(Log entries)加入到它的日志中,然后并行的向其他服务器发起 RPC 复制日志条目。
如果一个日志条目被复制到大多数服务器上,就被认为可以提交(commit)了。
Leader通过强制Followers复制它的日志来处理日志的不一致,Followers上的不一致的日志会被Leader的日志覆盖。
3.4 日志快照
在实际的系统中,不能让日志无限增长,否则系统重启时需要花很长的时间进行回放,从而影响可用性。Raft采用对整个系统进行snapshot来解决,snapshot之前的日志都可以丢弃。
做snapshot既不要做的太频繁,否则消耗磁盘带宽, 也不要做的太不频繁,否则一旦节点重启需要回放大量日志,影响可用性。推荐当日志达到某个固定的大小做一次snapshot。
4. ZAB 算法
ZAB 协议的全称是 Zookeeper Atomic Broadcase,原子广播协议。
4.1 角色
- Observer:和 Follower 一样,唯一不同的是,不参与 Leader 的选举,且状态为 OBSERING。
- Follower:负责处理客户端发送的读请求,转发写事务请求给 Leader。参与 Leader 的选举,状态为 FOLLOWING。
- Leader:负责处理客户端发送的读、写事务请求。同步写事务请求给其他节点,且需要保证事务的顺序性。状态为 LEADING。
4.2 选举
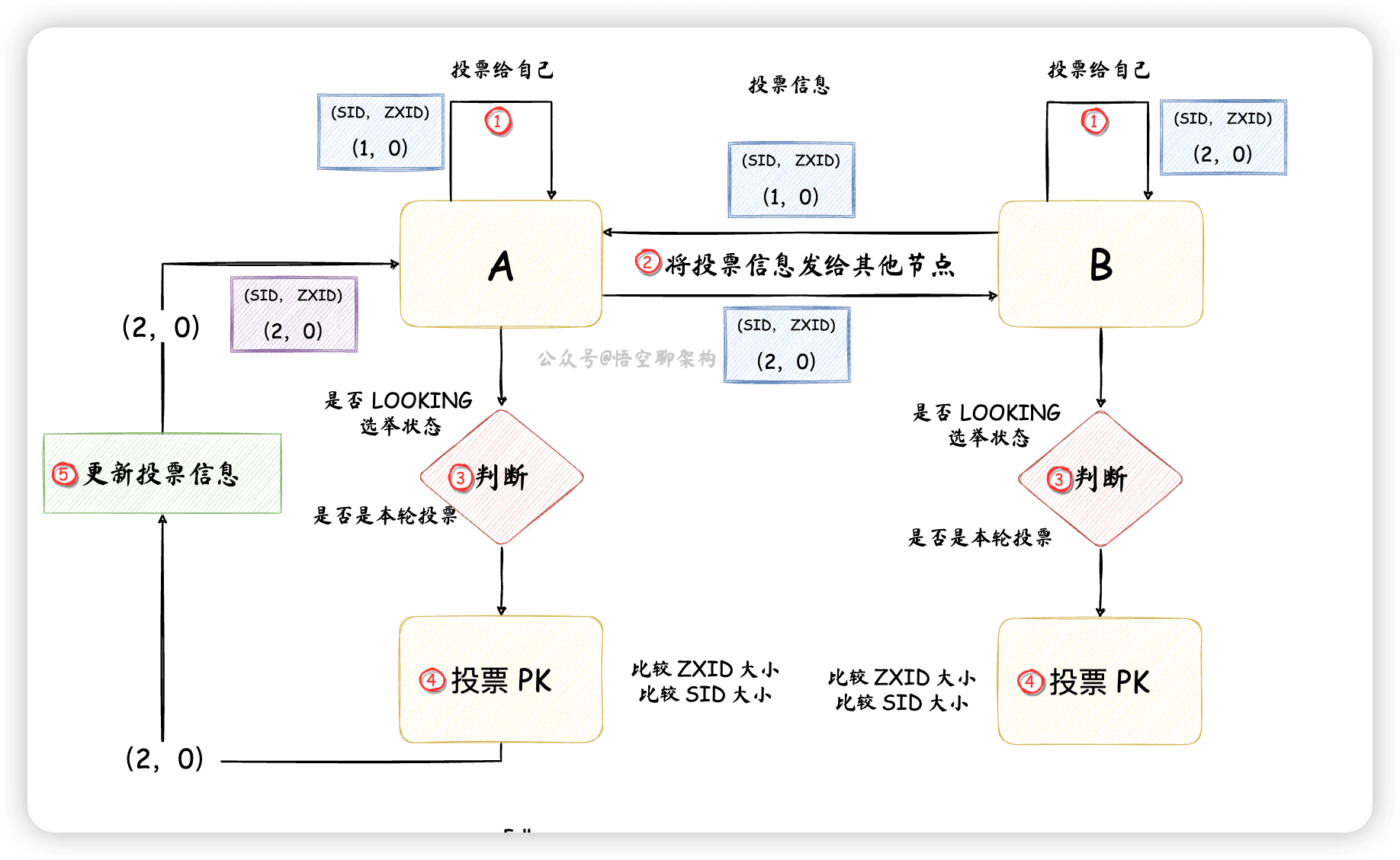
- 节点 A 先
投票给自己,投票信息包含节点 id(SID)和一个ZXID,如 (1,0)。SID 是配置好的,且唯一,ZXID 是唯一的递增编号。 - 节点 B 先
投票给自己,投票信息为(2,0)。 - 然后节点 A 和 B 将自己的投票信息
投票给集群中所有节点。 - 节点 A 收到节点 B 的投票信息后,
检查下节点 B 的状态是否是本轮投票,以及是否是正在选举(LOOKING)的状态。 - 投票 PK:节点 A 会将自己的投票和别人的投票进行 PK,如果别的节点发过来的 ZXID 较大,则把自己的投票信息
更新为别的节点发过来的投票信息,如果 ZXID 相等,则比较 SID。这里节点 A 和 节点 B 的 ZXID 相同,SID 的话,节点 B 要大些,所以节点 A 更新投票信息为(2,0),然后将投票信息再次发送出去。而节点 B不需要更新投票信息,但是下一轮还需要再次将投票发出去。
4.3 领导者故障
- 剩下的 Follower 进行选举,Observer 不参与选举。
- 投票信息中的 zxid 用的是本地磁盘日志文件中的。如果这个节点上的 zxid 较大,就会被当选为 Leader。如果 Follower 的 zxid 都相同,则 Follower 的节点 id 较大的会被选为 Leader。
4.4 节点之间同步数据
而客户端发送读写请求时是不知道自己连的是Leader 还是 Follower。
如果客户端连的是主节点,发送了写请求,那么 Leader 执行 2PC(两阶段提交协议)同步给其他 Follower 和 Observer 就可以了。
如果客户端连的是 Follower,发送了写请求,那么 Follower 会将写请求转发给 Leader,然后 Leader 再进行 2PC 同步数据给 Follower。
5. 头脑风暴
- Paxos 有三个角色,提议者,接受者,学习者。分为准备阶段和接受阶段。
- Raft 有三个角色,默认都是 follower,通过随机定时任务变为 候选者,让其他人给自己投票,最终成为领导者。主发送心跳信息和处理写请求。其中有term编号,每次都递增,处理比自己大的编号消息。
- Zab 有三个角色,都是给自己投票,然后投票PK。