mongodb实战问题
1. 连接
1.1 client连接
Mac 终端连接
1
2
3
4
5
6
7
8
9
10
11brew install mongosh
mongosh "mongodb://user:password@xxxxxxx.com:3717/db_name"
# 查看当前在哪个数据库
db
# 查看所有数据库
show dbs
# 查看数据库所有集合
show collections
Studio 3T
Navicat,直接输入uri 连接

1.2 集群连接
协议拆解
1 | "mongodb://admin:k55@abc.mongodb.rds.aliyuncs.com:3717/hello" |
副本集实例
MongoDB复制集里Primary节点是不固定的,不固定的,不固定的,重要的事情说3遍。
当连接复制集时,如果直接指定Primary的地址来连接,当时可能可以正确读写数据的,但一旦复制集发生主备切换,你连接的Primary会降级为Secondary,你将无法继续执行写操作,这将严重影响到你的线上服务。
所以生产环境千万不要直连Primary,千万不要直连Primary,千万不要直连Primary。
1 | MongoClientURI connectionString = new MongoClientURI("mongodb://root:****@dds-bp114e3f1fc441342.mongodb.rds.aliyuncs.com:3717,dds-bp114e3f1fc441341.mongodb.rds.aliyuncs.com:3717/admin?replicaSet=mgset-677201"); |
分片集群实例
MongoDB分片集群实例分别提供Mongos、Shard和ConfigServer组件单独的连接地址,以及适用于应用程序连接的高可用ConnectionStringURI地址。
生产程序不建议使用单节点连接地址。
1 | MongoClientURI connectionString = new MongoClientURI("mongodb://root:****@s-xxxxxxxx.mongodb.rds.aliyuncs.com:3717,s-xxxxxxxx.mongodb.rds.aliyuncs.com:3717/admin"); |
1.3 规则
副本集直连 mongod 节点的场景,禁止只在连接串中配置单个 IP;分片集群禁止只连接单个 mongos 地址(除非 mongos 和应用服务器部署在一起)
线上业务如果只连接副本集主节点,一旦数据库发生 HA 会造成写入中断;如果只连接单个 mongos,这个 mongos 故障后会造成业务中断。
2. 主键
2.1 类型
默认主键
在插入文档时,如果我们没有为”_id”字段指定值,MongoDB会自动生成一个唯一的ObjectId作为默认值。这个ObjectId是由时间戳、机器标识、进程ID和随机数组成的。
1 | db.users.insertOne({ name: "John", age: 30 }); |
自定义主键
如果我们想要自定义主键,可以手动为文档指定主键字段。自定义主键可以是任何类型,例如字符串、数字、日期等等。
在这种情况下,我们需要确保该字段的值在文档集合中是唯一的。
1 | db.users.createIndex({ email: 1 }, { unique: true }); |
2.2 规则
- 业务禁止自定义 _id 字段
_id是 MongoDB 内部的默认主键,默认这是一个自增的序列。如果自定义_id并且业务无法保证_id递增,每次插入数据后,_id索引不可避免需要对 B 树索引进行调整,这将对数据库带来额外的负担。
3. 索引
3.1 使用
1 | >db.collection.createIndex(keys, options) |
实战:
1 | db.createCollection("user_wxgroup_record"); |
3.2 规则
线上库建立索引,必须携带 background:true 参数建索引
MongoDB 4.2 及之前的版本,createIndex() 命令默认是 foreground 模式,这种模式下创建索引会阻塞数据库的所有操作,造成业务中断,线上业务执行 createIndex() 务必添加 background参数。禁止一个表内创建过多的索引:原则上不得超过5个索引
MongoDB 插入每条数据的时候同时需要写索引。索引越多,写入数据时就要花费更多的代价,因此禁止对索引的滥用。
4. 分片
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力, 大的查询量会将单机的CPU耗尽, 大的数据量对单机的存储压力较大, 最终会耗尽系统的内存而将压力转移到磁盘IO上。
为了解决这些问题, 有两个基本的方法: 垂直扩展和水平扩展。
垂直扩展:增加更多的CPU和存储资源来扩展容量。水平扩展:将数据集分布在多个服务器上。MongoDB的分片就是水平扩展的体现。
4.1 介绍
分片键
分片键就是在集合中选一个字段或者组合字段,用该键的值作为数据拆分的依据。
分片键必须是一个索引,集合设置分片并插入文档之后,其中的每个文档的分片的键和值都是不可更改的。如果需要修改文档的分片键,必须要先删除文档,再修改分片键,然后重新插入文档。
- 分片键是不可变。
- 分片键必须有索引。
- 分片键大小限制512bytes。
- 分片键用于路由查询。
- MongoDB不接受已进行collection级分片的collection上插入无分片
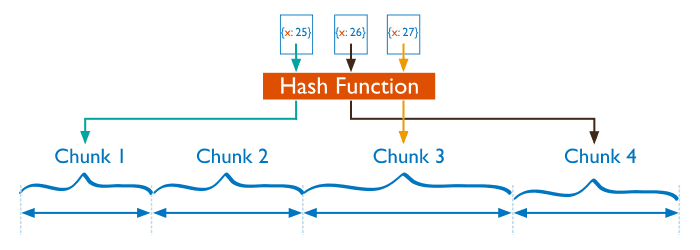
哈希分片
分片过程中利用哈希索引作为分片,基于哈希片键最大的好处就是保证数据在各个节点分布基本均匀。
对于基于哈希的分片,MongoDB计算一个字段的哈希值,并用这个哈希值来创建数据块。在使用基于哈希分片的系统中,拥有相近分片键的文档很可能不会存储在同一个数据块中,因此数据的分离性更好一些。
哈希分片是只能基于一个字段吗?MongoDB4.4版本中已经可以针对复合索引字段进行哈希分片。
范围分片
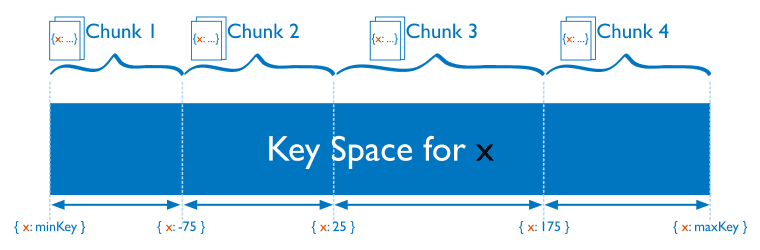
在使用片键做范围划分的系统中,拥有相近分片键的文档很可能存储在同一个数据块中,因此也会存储在同一个分片中。
4.2 使用
开启分片
1 | -- 使用如下命令,开启数据库分片开关。 |
实战:
1 | db.runCommand({shardcollection:"poros.user_web_group_record", key:{user_id: "hashed"}}); |
4.3 规则
分片集群禁止直连 mongod 节点写数据
分片集群应该通过 mongos 写数据,直接通过 mongod 写入的数据无路由信息,会导致访问不到。分片表原则上必须携带片键进行查询
分片表不带片键进行查询,需要扫描所有分片后在 mongos 聚合结果,比较消耗性能,不推荐使用。建议使用区分度较大的字段作为片键,最理想的情况是使用唯一主键作为片键
如果片键区分度不大,可能导致大量的记录集中在某些片上,而这种不均衡也无法添加分片进行扩展。因此建议使用区分度较大的字段作为片键。
如果使用 hash 分片,建议进行预分配,特别是表比较大且经常经常需要大量插入数据
shardCollection() 命令默认每个分片只会创建2个 chunk,随着数据量的越来越大,MongoDB 需要不断的 balance 和 splitChunk,这将对数据库带来较大的负担。
因此在对于大集合,建议提前进行预分片(shardCollection 命令指定 numInitialChunks 参数,每个分片最大支持8192个),特别是向大集合中批量导数据。没有按片建顺序扫描的强需求,不建议使用 range 分片,推荐 hash 分片
range 分片容易引起不均衡和数据热点,而且因为无法预分片所以随着数据的写入 balance 不可避免,因此不建议使用,除非有特殊的按片键范围查询需求。在 shardCollection 的时候,sh.shardCollection(“records.people”, { zipcode: 1 } ) 命令中1表示范围分片,sh.shardCollection(“records.people”, { zipcode: “hashed” } ) 命令中”hashed”表示 hash 分片。需注意不要用错。
分片集群中不建议使用非分片表
MongoDB 的分片集群如果未执行 shardCollection 命令,默认数据只存储在主分片上。大量未分片的表会造成分片和分片间的数据量不一致。集群长时间运行下去,可能会造成某些片数据量特别多甚至会打满磁盘,运维在这种情况下不得不使用 movePrimary 手动进行数据搬迁,从而增加了运维复杂度。
5. MongoDB Atlas 云端连接
ECS 任务连接 MongoDB Atlas 集群通常有两条路。
| 方案 | 类比 | 说明 |
|---|---|---|
| 公网 + IP 白名单 | 从大门进,门卫认 IP | ECS 经过固定公网出口访问 Atlas,把出口 IP 加到白名单 |
| VPC Peering / PrivateLink | 开内部通道 | AWS VPC 和 Atlas VPC 建专用连接,流量不走公网 |
5.1 公有子网和私有子网
判断 ECS 所在子网能不能访问公网,看路由表:
0.0.0.0/0 -> igw-xxx:公有子网,资源可直接出公网。0.0.0.0/0 -> nat-xxx:私有子网,通过 NAT Gateway 出公网。- 没有
0.0.0.0/0:通常没有出网能力。
如果 ECS 在私有子网里访问 Atlas 公网地址,通常需要 NAT Gateway。NAT Gateway 绑定 Elastic IP,这个固定公网 IP 就是 Atlas 白名单里要填的地址。
5.2 NAT Gateway 的作用
NAT Gateway 可以理解成私有子网的统一出口。子网里的 Task 没有公网 IP,但访问互联网时,外部看到的是 NAT Gateway 的 Elastic IP。
这也是 Atlas 公网白名单方案的关键:白名单不要填 Task 私有 IP,而是填 NAT Gateway 的固定公网 IP。