Istio教程04-超时重试负载均衡和熔断
在服务调用中遇到HTTP 503错误时,我们可以配置Istio来重试失败的请求,最多可以重试三次。我们可以准确地配置哪些失败的请求要重试、重试次数,以及每次重试的超时时间。
由于服务代理是按服务实例部署的,我们可以配置非常精细的重试行为,以适应应用程序的特定需求。Istio的所有弹性设置都是如此,服务代理实现了这些开箱即用的弹性模式:
- 客户端负载均衡。
- 位置感知负载均衡。
- 超时和重试。
- 熔断。
1. VirtualService 层
1.1 超时
- 服务A调用服务B的超时时间为1s,而服务B调用服务C设置了2s超时,哪个超时会先触发?通常最严格的规则会先执行,所以从服务B到服务C的调用超时可能永远不会被触发。
- 比较合理的方法是在系统的边界(流量进入的地方)设置较长的超时时间,而在调用链路中较深的层设置更短(或更严格)的超时时间。
超时显示失败
我们使用Istio VirtualService资源指定请求的超时,例如将调用 simple-backend 服务的一半请求设置为1s的延迟,给网格中调用simple-backend的客户端设定0.5s的超时。


当调用服务时,一旦调用时间超过0.5s就会失败,并返回HTTP 500错误:

1.2 重试
Istio默认启用了重试功能,并且最多重试两次。在默认情况下,Istio会尝试调用一次;如果失败,则会再尝试两次。
在第一次尝试中不可能成功发送请求:
connect-failure
refused-stream
unavailable(gRPC状态码14)
cancelled(gRPC状态码1)
retriable-status-codes(在Istio中,默认是HTTP 503)。
关闭重试看到预期的失败
我们部署一个有周期性(75%)故障的simple-backend服务。首先通过配置VirtualService资源来禁用示例应用程序的默认重试次数,将最大重试次数设置为0。


开启重试不再显示失败


重试的超时设置
- 重试有自己的超时设置——perTryTimeout。注意,perTryTimeout值乘以总的重试次数必须小于全局的请求超时时间。
- 例如,设置全局的超时时间为1s,重试次数为3次,每次重试的超时时间为500ms,这是不可行的。因为全局的请求超时将在所有重试执行完成之前就会被触发。
重试的惊群效应
- 随意的重试设置(如默认值)会导致严重的“惊群效应”。例如,一个服务链有5个调用,每一步可以重试请求2次,最终可能会对每个调用产生32个请求。如果服务链末端资源过载,这种额外的负载可能会使目标资源不堪重负,以至于压垮它。
- 一种策略是在系统的边界将重试次数限制为一次或零次,只在调用链路的深处重试,中间服务不重试。但这也有可能行不通。
- 另一种策略是对总的重试次数设置上限。我们可以通过重试预算来做到这一点;不过Istio的API中还未提供这一功能。Istio中也有变通方案。
2. DestinationRule 层
2.1 客户端负载均衡
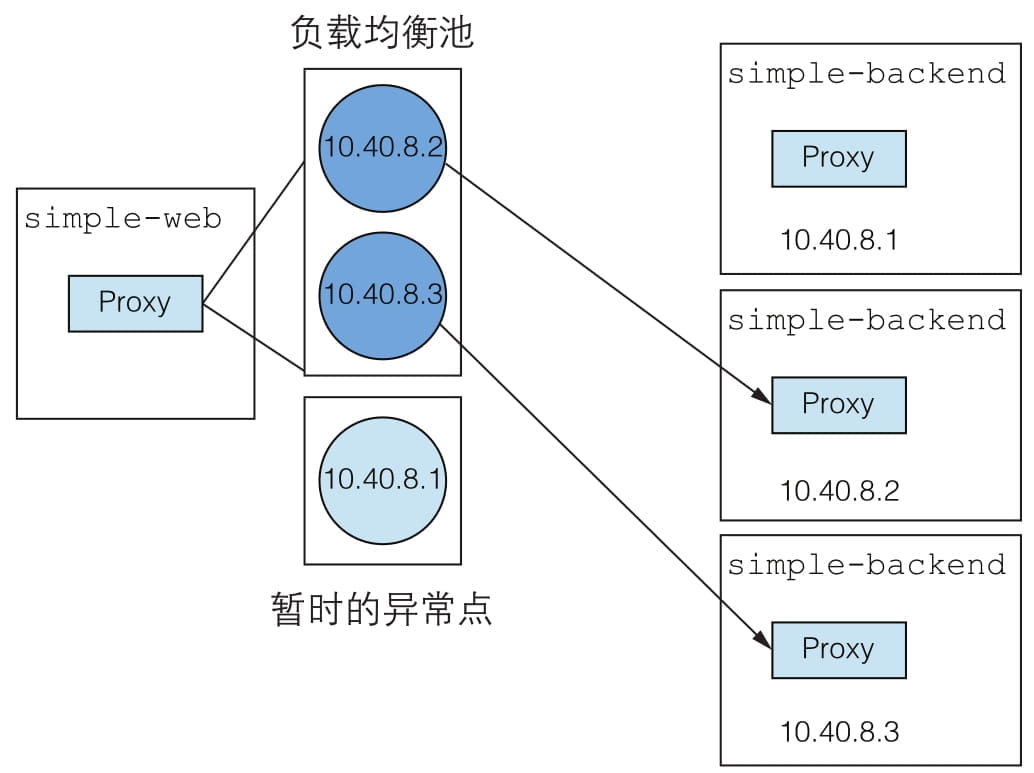
simple-web服务调用simple-backend服务,但simple-backend服务有多个副本。

服务的开发人员和运维人员可以通过定义DestinationRule资源来设置客户端使用何种负载均衡算法。Istio的服务代理是基于Envoy的,因此支持Envoy的负载均衡算法,包括:1. 轮询(默认)2. 随机 3 加权最小请求数。

simple-web和simple-backend之间的调用被有效地分配到了不同的simple-backend端点。

2.2 位置感知负载均衡
- 我们可以用istio-locality标记Pod,并给它一个明确的区域/可用区。这足以验证位置感知路由和负载均衡。

为了让位置感知负载均衡在Istio中发挥作用,我们还需要一个配置:健康检查。如果没有健康检查,Istio就不知道负载均衡池中哪些端点是不健康的,也不知道该用什么方法路由到下一个区域。
2.3 熔断
服务熔断定义:当下游的服务因为某种原因导致服务不可用或响应过慢时,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回。当下游服务恢复后,上游服务会恢复调用。
熔断器状态:
最开始处于
closed状态,一旦检测到错误(或慢响应)达到一定阈值,便转为open状态,此时不再调用下游目标服务。等待一段时间后,会转化为
half open状态,尝试放行一部分请求到下游服务。一旦检测到响应成功,回归到
closed状态,也即恢复服务;否则回到open状态。其中熔断器从
close变为open状态要同时满足以下2个条件:
- 前提条件:在滑动时间窗口内至少有一定数量的请求(即最少请求数)
- 指标达到阈值:在滑动时间窗口内统计的错误请求率或慢请求率达到一定阈值
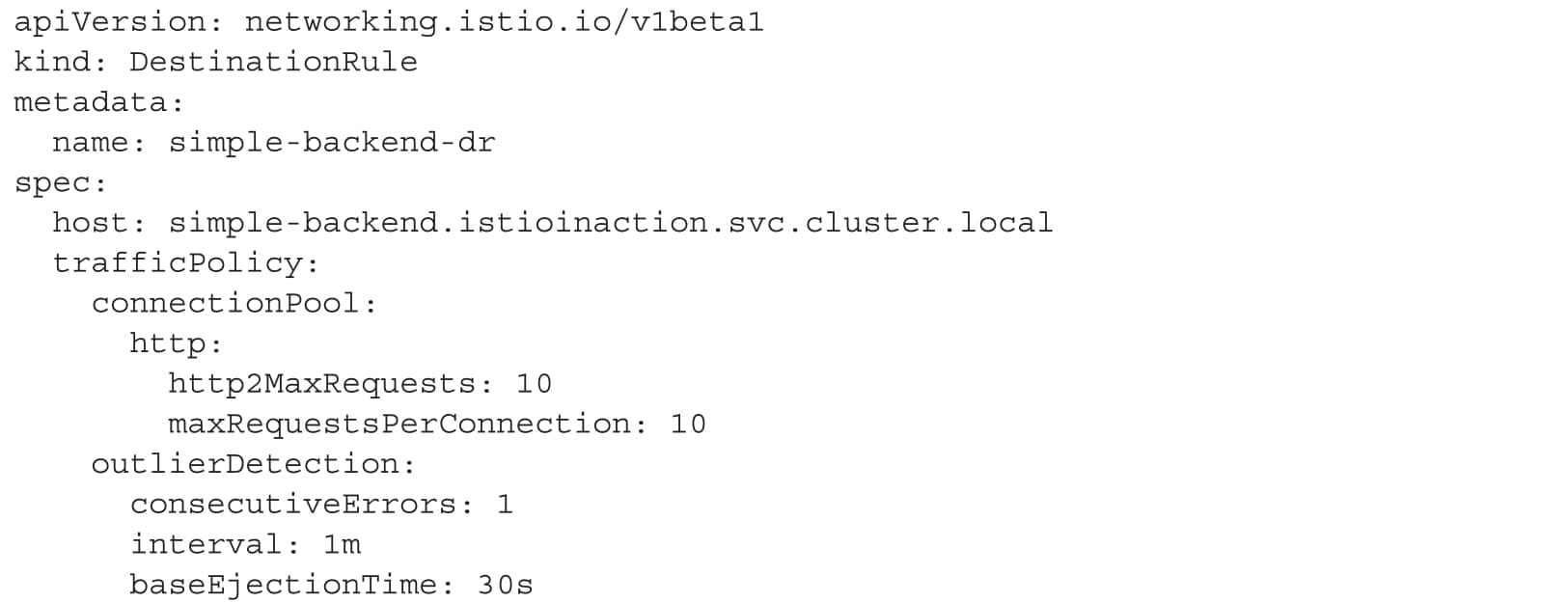
设置连接限制
如果simple-web服务调用simple-backend服务,simple-backend服务在连续的调用中返回错误,那么与其通过不断重试给系统增加压力,还不如停止对simple-backend服务发送请求。
在Istio中,我们可以使用DestinationRule中的connectionPool来限制调用服务的连接和请求的数量。如果有太多的请求积压在一起,就可以将它们短路(快速失败)并返回给客户端。

如果把连接数和每秒的请求数增加到两个,会发生什么?从负载测试工具来看,基本上会从两个连接每秒发送一个请求。在Istio代理层面,请求会超过连接数限制并开始排队。如果达到了最大请求数或最大待处理请求数,就可能触发熔断器。我们来测试一下:

区分熔断和其他故障
在例子中,simple-web如何知道请求因为熔断而失败,并把这个问题与应用程序或网络故障区分开来?
当请求因触发熔断阈值而失败时,Istio的服务代理会添加一个x-envoy-overloaded头。
利用异常点检测剔除不健康的服务
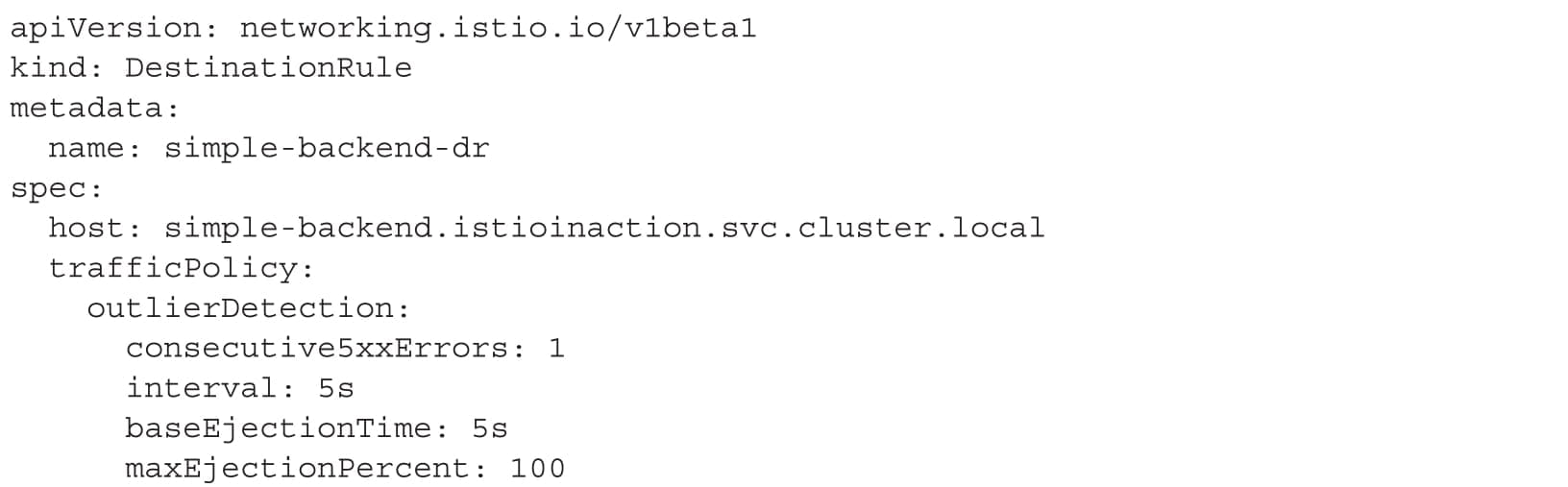
我们将consecutive5xxErrors的值设置为1,这意味着只要有一个失败的请求,异常点检测就会被触发。
interval字段指定了Istio服务代理检查主机的频率,并根据consecutive5xxErrors设置决定是否驱逐一个端点。如果一个端点被驱逐,它将被逐出n*baseEjectionTime的时间,其中n是该端点被逐出的次数。过了这段时间之后,它又会被添加回负载均衡池中。
3. 头脑风暴
3.1 弹性能力
- 重试和超时是在VirtualService资源中配置的。
- 负载均衡是通过DestinationRule资源配置的。ROUND_ROBIN——默认算法,将请求以轮询的方式发送到端点。RANDOM——将请求发送到随机端点。LEAST_CONN——将请求发送到活动请求最少的端点(已废弃)。
- 熔断在DestinationRule资源中配置,在发送额外的流量之前,它允许上游服务有时间恢复。
3.2 每层的特点
- Pod 特点:spec.containers
- Rc,Rs 特点:spec.replicas
- Service 特点:spec.ports
- Ingress 特点:spec.rules
- Deployment 特点:spec.replicas, spec.strategy
- Gateway 特点:spec.servers
- VirtualService 特点:spec.hosts, spec.gateways, spec.http
- DestinationRule:spec.host, spec.subsets
4. 参考文档
- 《istio in action》