sql进阶教程02-自连接
无论表还是视图,本质上都是集合。集合是 SQL 能处理的唯一的数据结构。
1.1 自连接使用
自连接和非等值连接结合起来非常好用。
1 | -- 用于获取排列的 SQL 语句 |
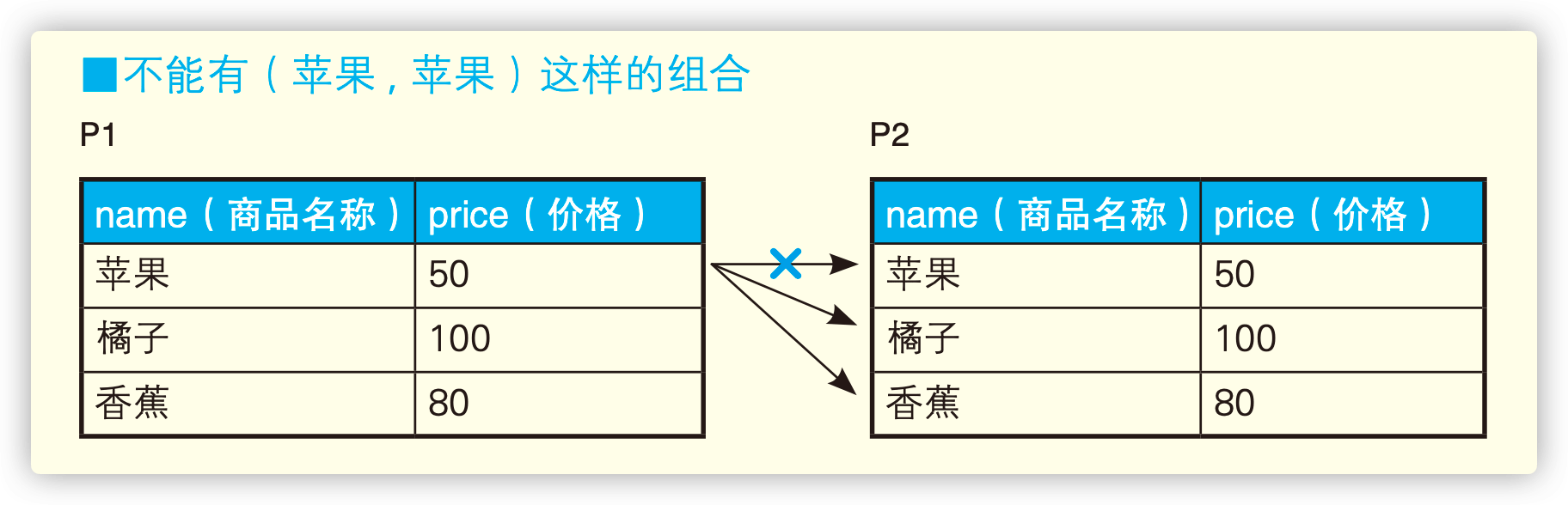
无论是 P1 还是 P2,实际上数据都来自同一张物理表 Product。但是,在 SQL 里,只要被赋予了不同的名称,即便是相同的表也 应该当作不同的表(集合)来对待。也就是说,P1 和 P2 可以看成是碰巧 存储了相同数据的两个集合。
1.2 查找局部不一致的列
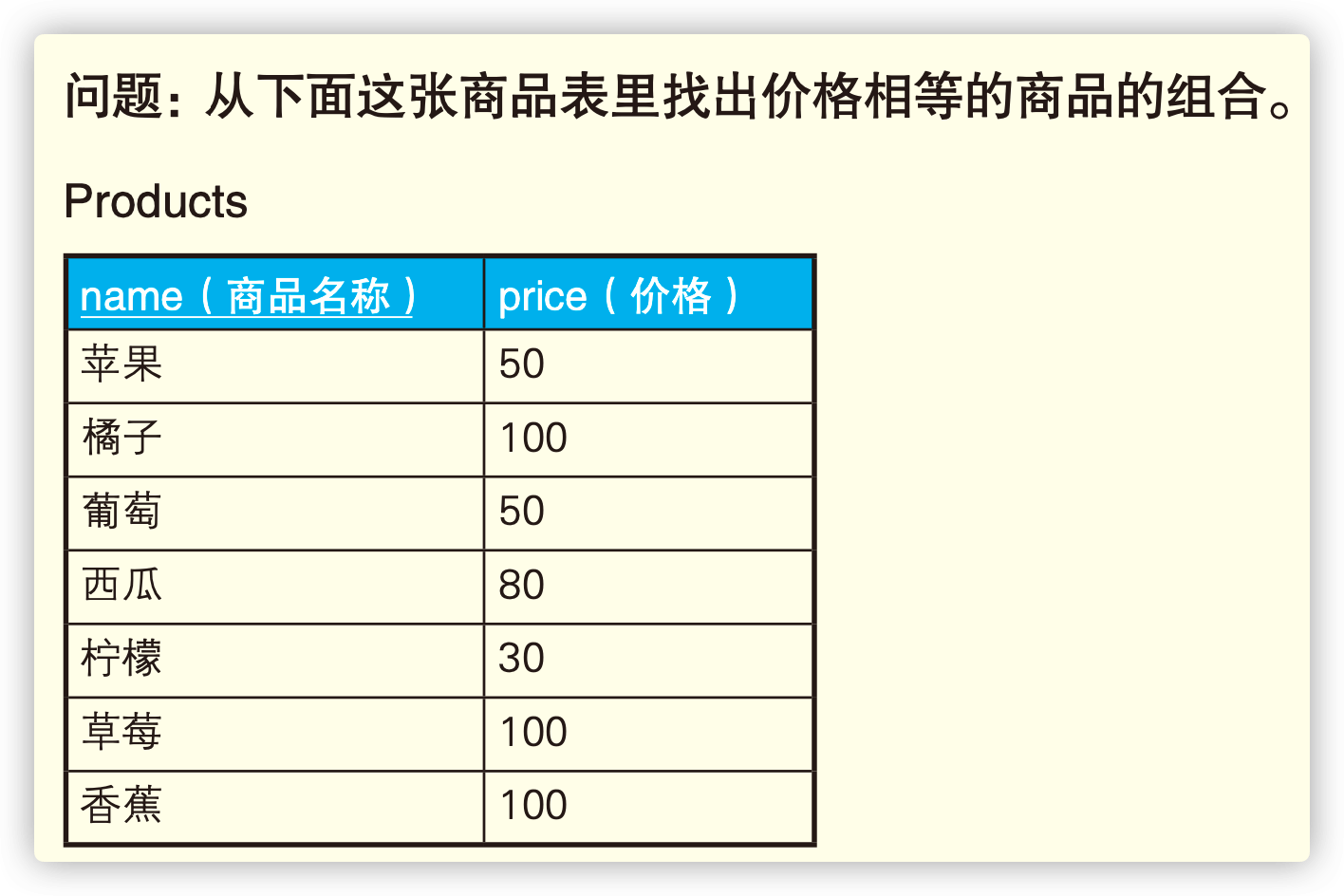
1 | SELECT DISTINCT P1.name,P1.price FROM Products P1, Products P2 WHERE P1.name <> P2.name AND P1.price = P2.price; |
1.3 排序
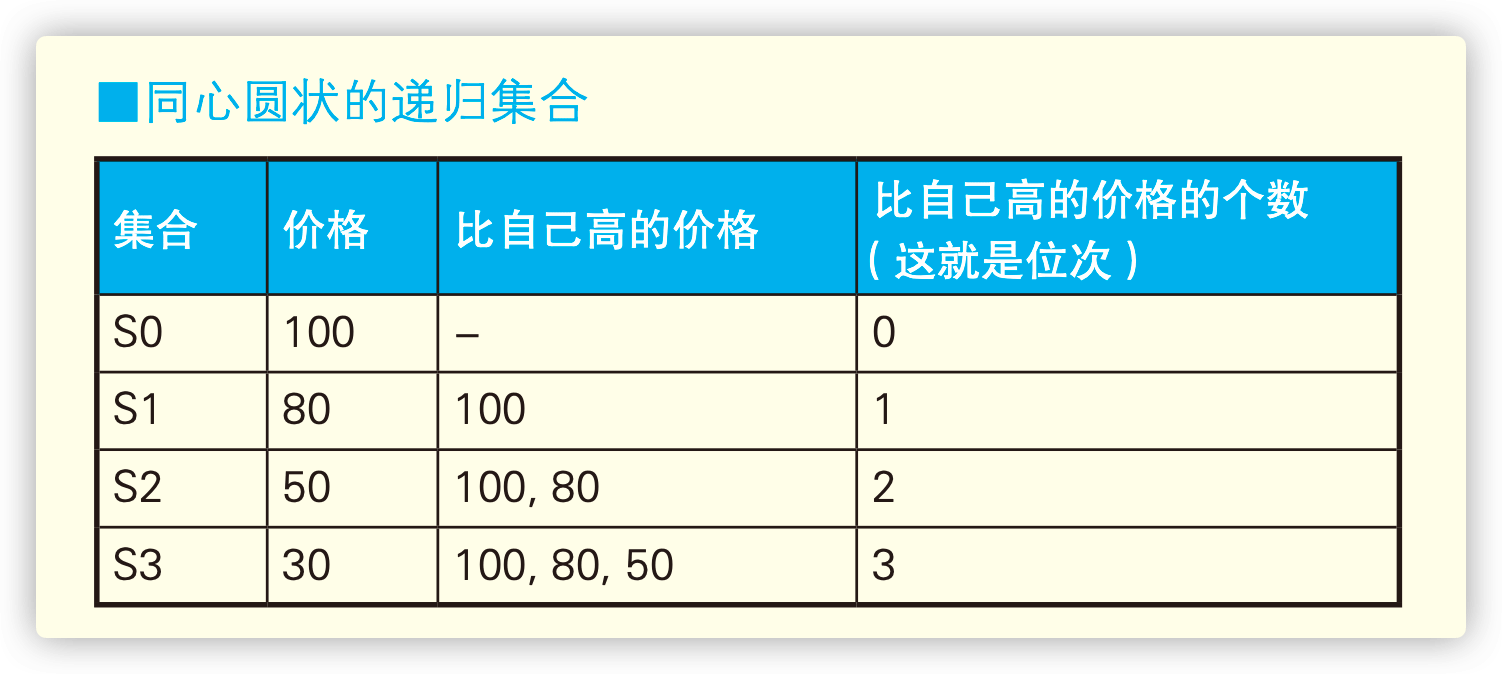
排序从 1 开始。如果已出现相同位次,则跳过之后的位次。
1 | SELECT name, price, (SELECT COUNT(P2.price) FROM Products P2 WHERE P2.price > P1.price) +1 AS rank |
这道例题很好 地体现了面向集合的思维方式。子查询所做的,是计算出价格比自己高的 记录的条数并将其作为自己的位次。
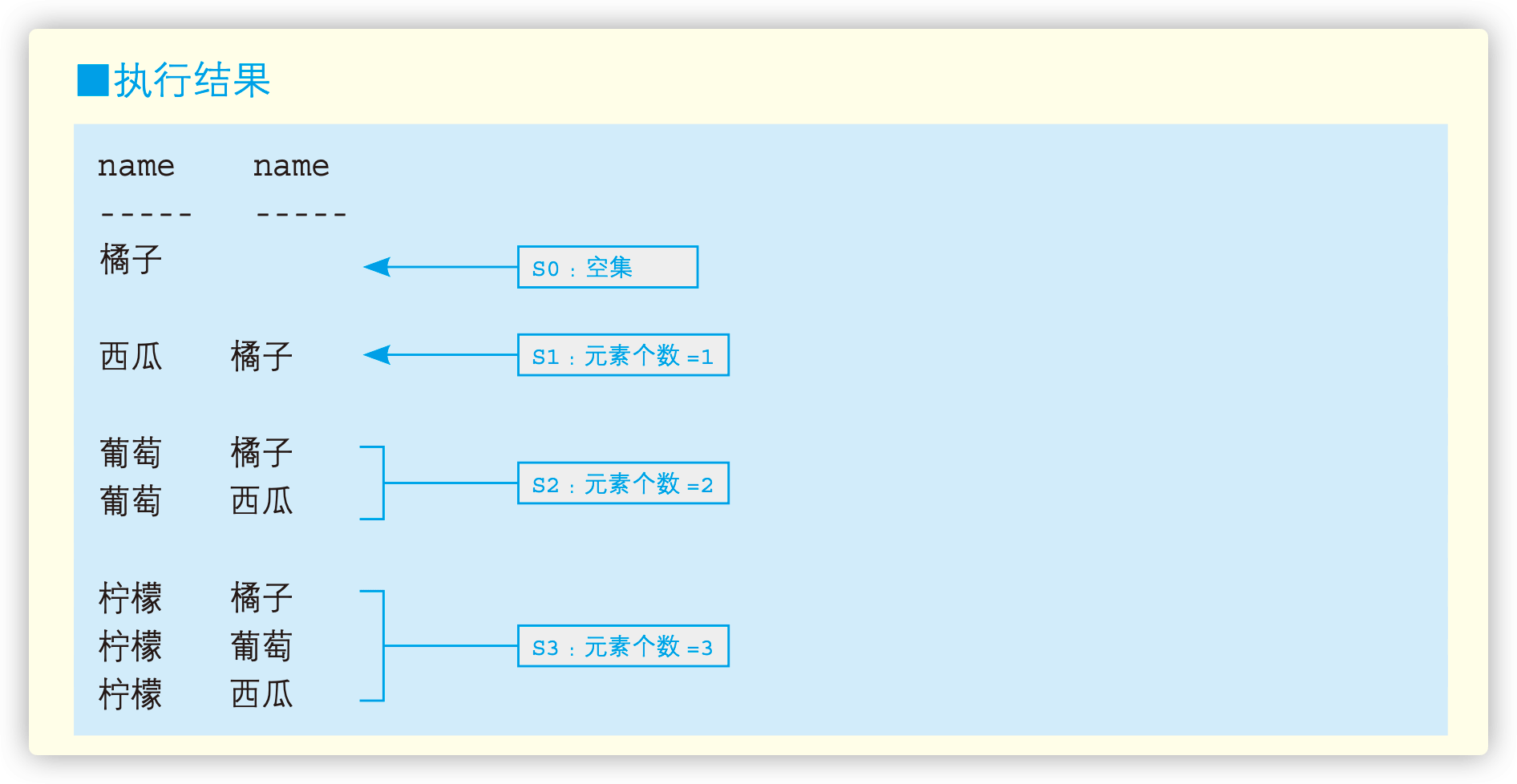
1.4 集合包含关系
1 | /* |
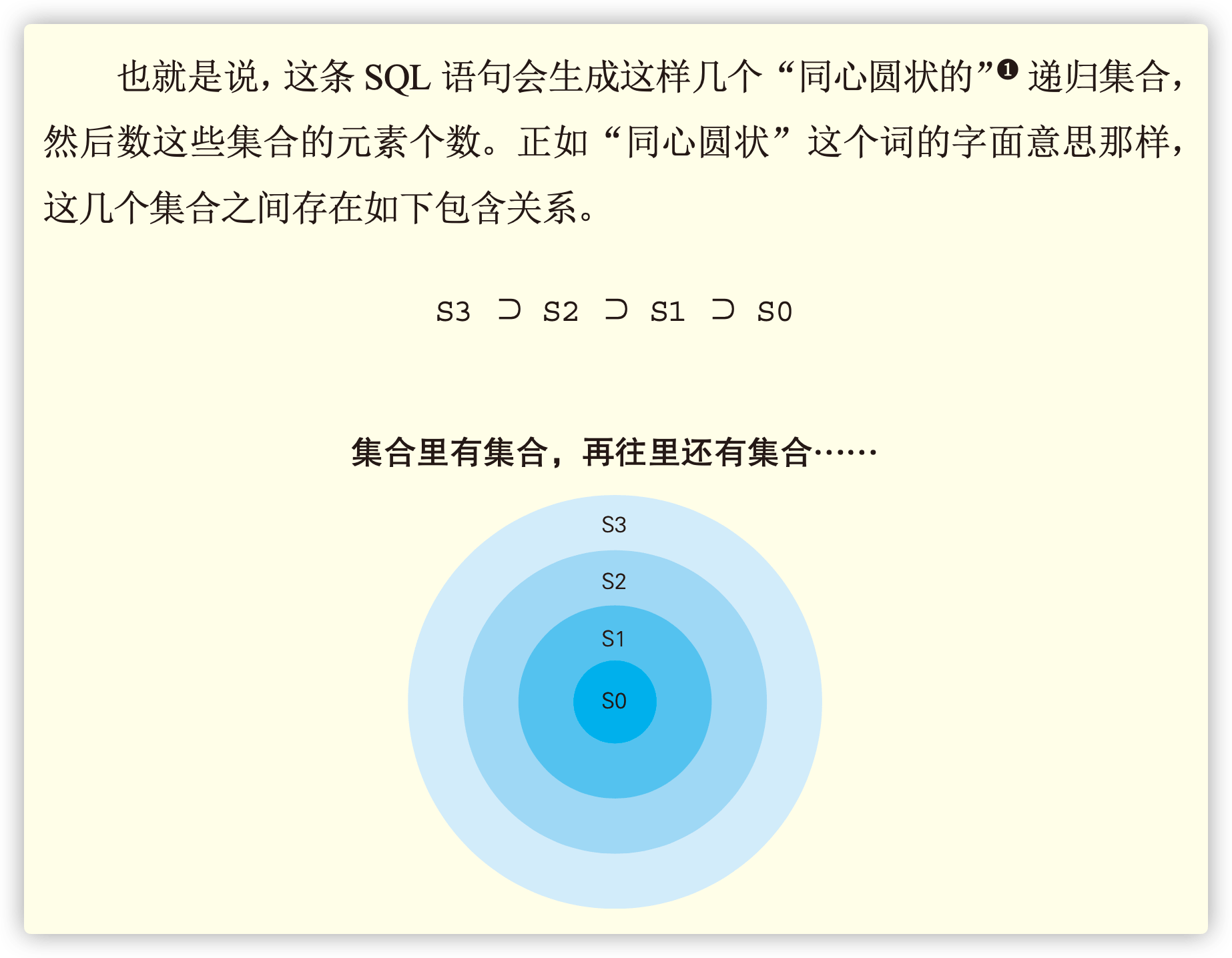
1.5 总结
与多表之间进行的普通连接相比,自连接的性能开销更大(特别是与非等值连接结合使用的时候),因此用于自连接的列推荐使用主键 或者在相关列上建立索引。
- 自连接经常和非等值连接结合起来使用。
- 自连接和GROUP BY结合使用可以生成递归集合。
- 将自连接看作不同表之间的连接更容易理解。
- 应把表看作行的集合,用面向集合的方法来思考。
- 自连接的性能开销更大,应尽量给用于连接的列建立索引。