k8s教程03-控制器ReplicaSet和CronJob
1. ReplicationController(弃用)
ReplicationController旨在创建和管理⼀个pod的多个副本(replicas)。这就是ReplicationController名字的由来。
ReplicationController会持续监控正在运⾏的pod列表,并保证相应“类型”的pod的数⽬与期望相符。如正在运⾏的pod太少,它会根据 pod模板创建新的副本。如正在运⾏的pod太多,它将删除多余的副本。
⼀个ReplicationController有三个主要部分
label selector(标签选择器),⽤于确定ReplicationController作⽤域中有哪些pod
replica count(副本个数),指定应运⾏的pod数量
pod template(pod模板),⽤于创建新的pod副本
1.1 创建

Kubernetes会创建⼀个名为kubia的新ReplicationController,它确保符合标签选择器app=kubia的pod实例始终是三个。当没有⾜够的pod时,根据提供的pod模板创建新的pod。

1.2 查看信息

1.3 将pod移⼊或移出作⽤域
在任何时刻,ReplicationController管理与标签选择器匹配的pod。通过更改pod的标签,可以将它从ReplicationController的作⽤域中添加或删除。


你现在有四个pod:⼀个不是由你的ReplicationController管理的,其他三个是。其中包括新建的pod。
1.4 ⽔平缩放pod

在Kubernetes中⽔平伸缩pod是陈述式的:“我想要运⾏x个实例。”你不是告诉Kubernetes做什么或如何去做,只是指定了期望的状态。
1.5 删除RC
当使⽤kubectl delete删除ReplicationController时,可以通过给命令增加–cascade=false选项来保持pod的运⾏。

2. ReplicaSet(新的rc)
ReplicaSet的⾏为与ReplicationController完全相同,但pod选择器的表达能⼒更强。虽然ReplicationController的标签选择器只允许包含某个标签的匹配pod,但ReplicaSet的选择器还允许匹配缺少某个标签的 pod,或包含特定标签名的pod,不管其值如何。
2.1 定义

唯⼀的区别在选择器中。不必在selector属性中直接列出pod需要的标签,⽽是在selector.matchLabels下指定它们。这是在ReplicaSet中定义标签选择器的更简单(也更不具表达⼒)的⽅式。
3. DaemonSet
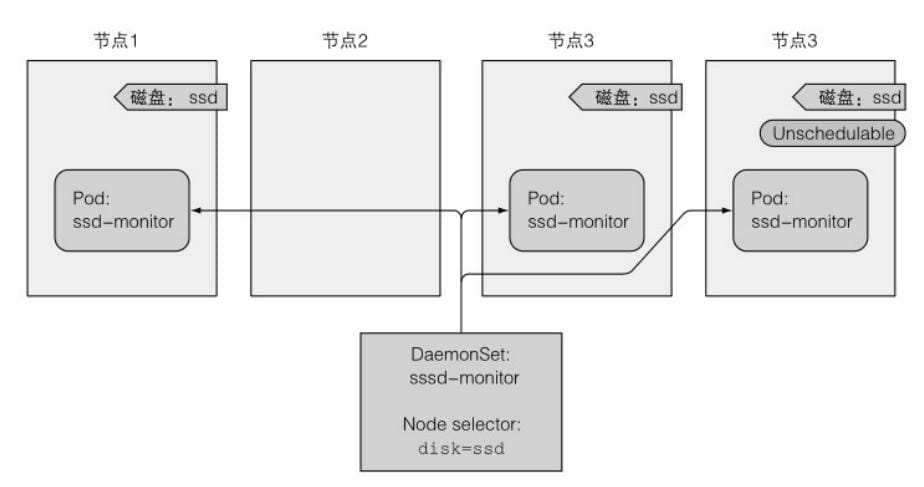
DaemonSet在每个节点上只运⾏⼀个pod副本,⼀个典型的例⼦是Kubernetes⾃⼰的kube-proxy进程,它需要运⾏在所有节点上才能使服务⼯作。
3.1 定义

3.2 效果
4. Job
允许你运⾏⼀种pod,该pod在内部进程成功结束时,不重启容器。⼀旦任务完成,pod就被认为处于完成状态。
4.1 定义
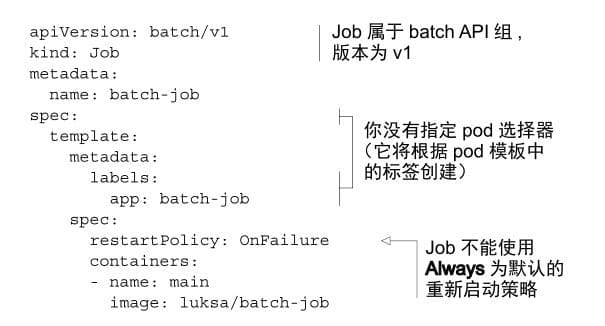
在使⽤kubectl create命令创建此作业后,应该看到它⽴即启动⼀个 pod:

4.2 执行完成

4.3 串行和并行执行

通过将parallelism设置为2,Job创建两个pod并⾏运⾏它们,只要其中⼀个pod完成任务,⼯作将运⾏下⼀个pod,直到五个pod都成功完成任务。

4.4 限制Job pod完成任务的时间
- 通过在pod配置中设置activeDeadlineSeconds属性,可以限制pod的时间。如果pod运⾏时间超过此时间,系统将尝试终⽌pod,并将Job标记为失败。
- 通过指定Job manifest中的spec.backoffLimit字段,可以配置 Job在被标记为失败之前可以重试的次数。如果你没有明确指定它,则默认为6。
5. CronJob
5.1 定义

5.2 延迟控制
如果任务开始不能落后于预定的时间过多。在这种情况下,可以通过指定CronJob规范中的startingDeadlineSeconds字段来指定截⽌⽇期,如下⾯的代码清单所⽰。

⼯作运⾏的时间应该是10:30:00。如果因为任何原因10:30:15不启动,任务将不会运⾏,并将显⽰为Failed。
6. 参考资料
- 《k8s in action》