k8s设计模式和容器标准
如果把 Kubernetes 比作云时代的操作系统,那容器就是操作系统中的进程。容器的本质是个特殊的进程,就是云时代的操作系统 Kubernetes 中的进程。
在一个真正的 os 内,进程并非“孤苦伶仃” 独自运行,而是以进程序,有原则的组织在一起。如 rsyslogd 程序负责 Linux 日志处理,rsyslogd 的主程序 main 以及它要用到的内核日志模块 imklog 同属于 2312 进程组。 而 Kubernetes 所做的,其实就是将“进程组”的概念映射到容器技术,并使其成为云原生操作系统“os”内的“一等公民”。
1. 容器设计模式
1.1 背景
场景一
假设现在有两个应用,其中一个是 Nginx,另一个是为该 Nginx 收集日志的 Filebeat,你希望将它们封装为容器镜像,以方便日后分发。
最直接的方案就将 Nginx 和 Filebeat 直接编译成同一个容器镜像,这是可以做到的,而且并不复杂,然而这样做会埋下很大隐患:它违背了 Docker 提倡的单个容器封装单进程应用的最佳实践。
场景二
假设现在有两个 Docker 镜像,其中一个封装了 HTTP 服务,为便于称呼,我们叫它 Nginx 容器,另一个封装了日志收集服务,我们叫它 Filebeat 容器。现在要求 Filebeat 容器能收集 Nginx 容器产生的日志信息。
场景二依然不难解决,只要在 Nginx 容器和 Filebeat 容器启动时,分别将它们的日志目录和收集目录挂载为宿主机同一个磁盘位置的 Volume 即可,这种操作在 Docker 中是十分常用的容器间信息交换手段。这种针对具体应用需求来共享名称空间的方案,的确可以工作,却并不够优雅,也谈不上有什么扩展性。
1.2 方案
如果现在我们把容器与进程在概念上对应起来,那容器编排的第一个扩展点,就是要找到容器领域中与“进程组”相对应的概念,这是实现容器从隔离到协作的第一步,在 Kubernetes 的设计里,这个对应物叫作 Pod。
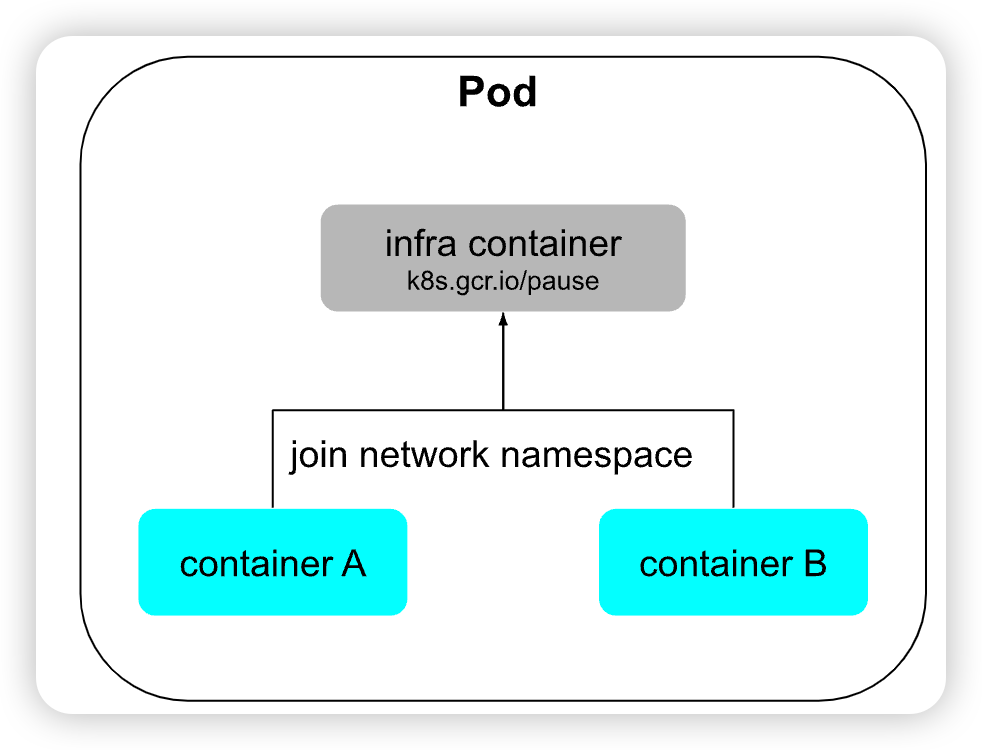
1.3 k8s 架构
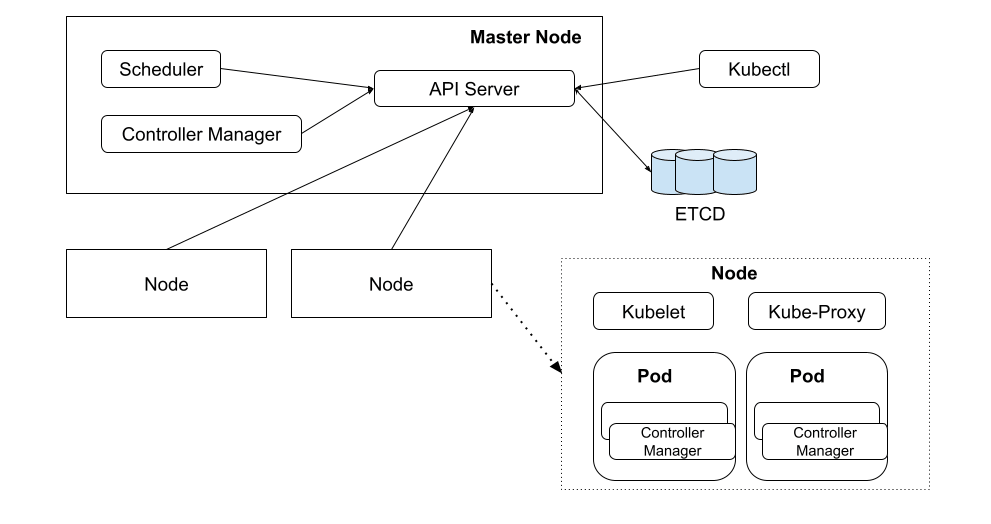
Master Node
- API Server: 操作 Kubernetes 各个资源的应用接口。并提供认证、授权、访问控制、API 注册和发现等机制。
- Scheduler(调度器):负责调度 Pod 到合适的 Node 上。例如,通过 API Server 创建 Pod 后,Scheduler 将按照调度策略寻找一个合适的 Node。
- Controller Manager(集群控制器):负责执行对集群的管理操作。例如,按照预期增加或者删除 Pod,按照既定顺序系统一系列 Pod。
Node 通常也被称为工作节点,可以有多个,用于运行 Pod 并根据 Control Plane 的命令管理各个 Pod。
- Kubelet 是 Kubernetes 在 Node 节点上运行的代理,负责所在 Node 上 Pod 创建、销毁等整个生命周期的管理。
- Kube-proxy 在 Kubernetes 中,将一组特定的 Pod 抽象为 Service,Kube-proxy 通过维护节点上的网络规则,为 Service 提供集群内服务发现和负载均衡功能。
- Container runtime (容器运行时):负责 Pod 和内部容器的运行。
2. 容器标准
在我们使用 docker run 命令时,便是将镜像中的各个层和配置组织起来从而启动一个新的容器。镜像就是一系列文件和配置的组合,它是静态的、只读的、不可修改的,而容器则是镜像的实例化,它是可操作的、动态的、可修改的。
2.1 OCI
OCI(Open Container Initiative,开放容器倡议)组织,该倡议组织的目标是推动容器运行时和容器镜像格式的开放标准化,创建一套通用的容器标准,以确保不同容器运行时和工具之间的互操作性和可移植性。
从 docker v1.11 版本开始,docker 就不是简单通过 Docker Daemon 来启动了,而是通过集成 containerd、containerd-shim、runc 等多个组件共同完成。docker 架构流程图已如下所示:
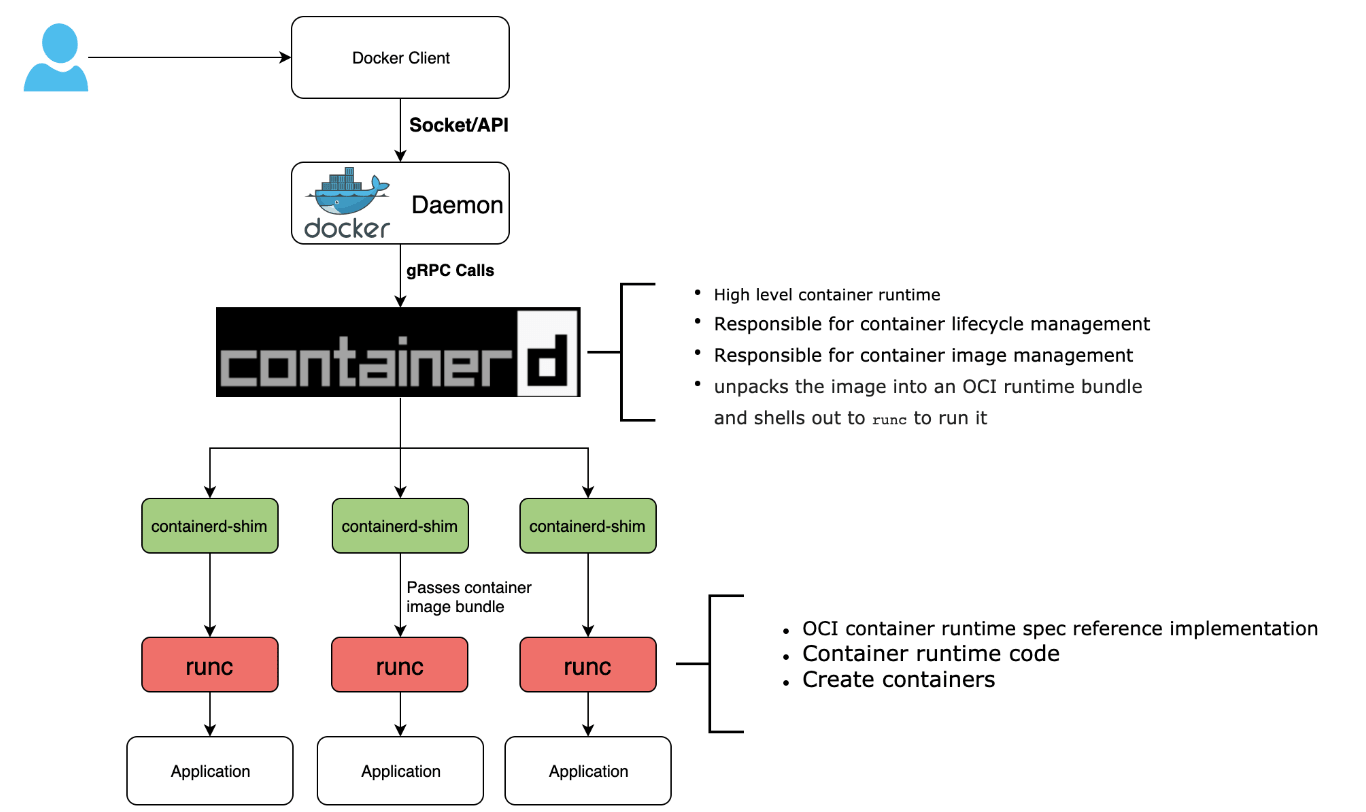 从 Docker 的拆分来看,容器运行时根据功能的不同分成了两类:
从 Docker 的拆分来看,容器运行时根据功能的不同分成了两类:只关注如 namespace、cgroups、镜像拆包等基础的容器运行时实现被称为低层运行时(low-level container runtime),目前应用最广泛的低层运行时是 runc;
支持更多高级功能,例如镜像管理、CRI 实现的运行时被称为高层运行时(high-level container runtime),目前应用最广泛高层运行时是 containerd。这两类运行时按照各自的分工,共同协作完成容器整个生命周期的管理工作。
2.2 CRI
早期 Kubernetes 完全依赖且绑定 Docker,并没有过多考虑够日后使用其他容器引擎的可能性。当时 kubernetes 管理容器的方式通过内部的 DockerManager 直接调用 Docker API 来创建和管理容器。
Kubernetes 从 1.5 版本开始,在遵循 OCI 基础上,将容器操作抽象为一个接口,该接口作为 Kubelet 与运行时实现对接的桥梁,Kubelet 通过发送接口请求对容器进行启动和管理,各个容器运行时只要实现这个接口就可以接入 Kubernetes,这便是 CRI(Container Runtime Interface,容器运行时接口)。
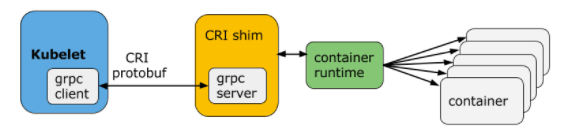
从上图可以看出:CRI 主要有 gRPC client、gRPC Server 和具体容器运行时实现三个组件。其中 Kubelet 作为 gRPC Client 调用 CRI 接口,CRI shim 作为 gRPC Server 来响应 CRI 请求,并负责将 CRI 请求内容转换为具体的运行时管理操作。因此,任何容器运行时实现想要接入 Kubernetes,都需要实现一个基于 CRI 接口规范的 CRI shim(gRPC Server)。
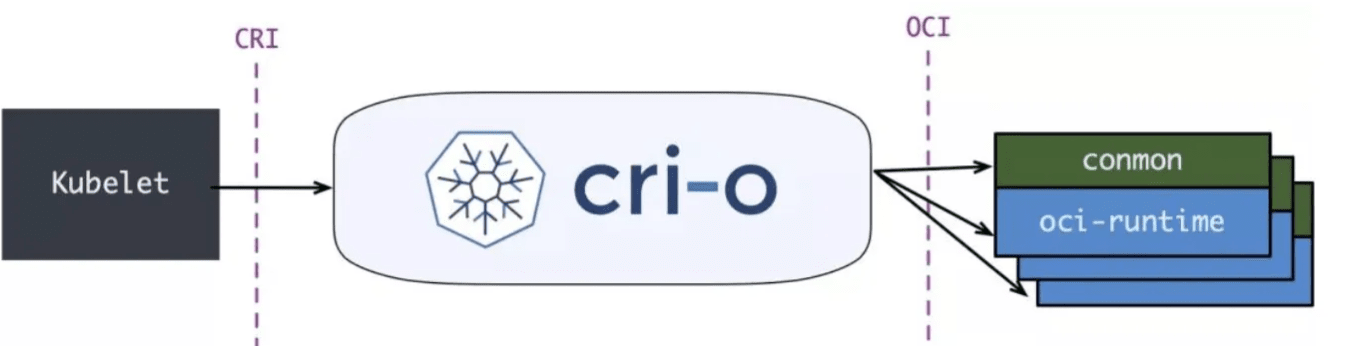
2.3 CRI-O
2017 年,由 Google、RedHat、Intel、SUSE、IBM 联合发起的 CRI-O(Container Runtime Interface Orchestrator)项目发布了首个正式版本。从名字就可以看出,它非常纯粹, 就是兼容 CRI 和 OCI, 做一个 Kubernetes 专用的轻量运行时。
Kubernetes 里就出现了两种调用链:
第一种是用 CRI 接口调用 dockershim,然后 dockershim 调用 Docker,Docker 再走 containerd 去操作容器。
第二种是用 CRI 接口直接调用 containerd 去操作容器。
2.4 Containerd
从 Kubernetes 角度看,选择 containerd 作为运行时的组件,它调用链更短,组件更少,更稳定,占用节点资源更少。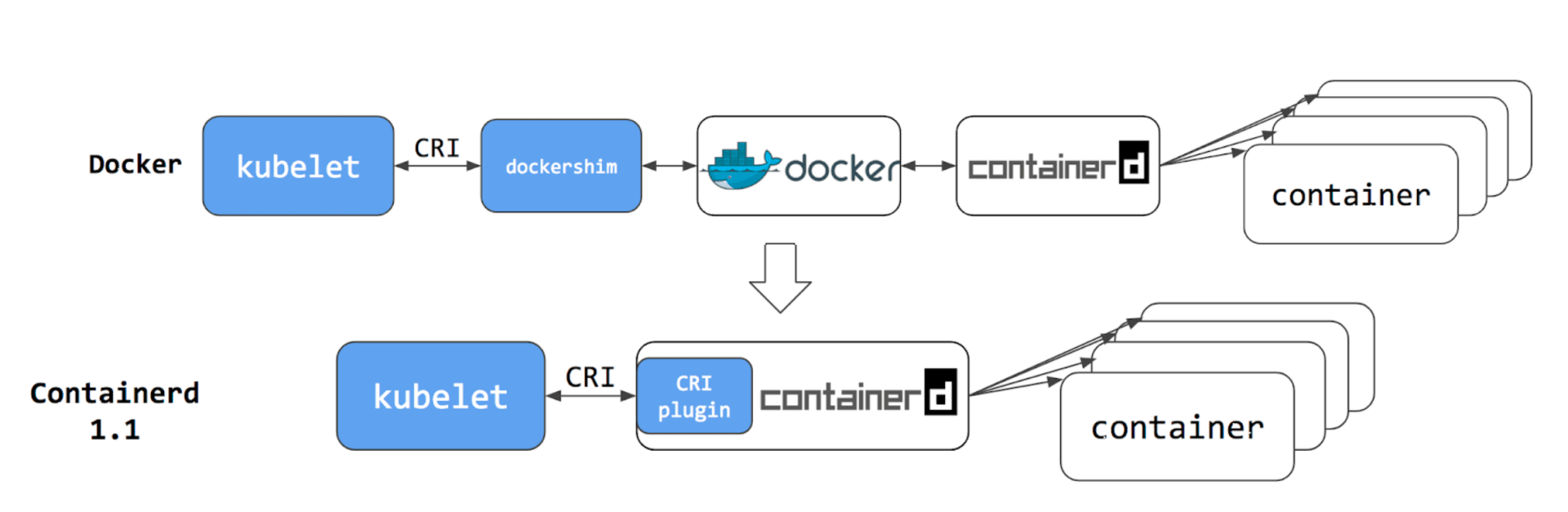
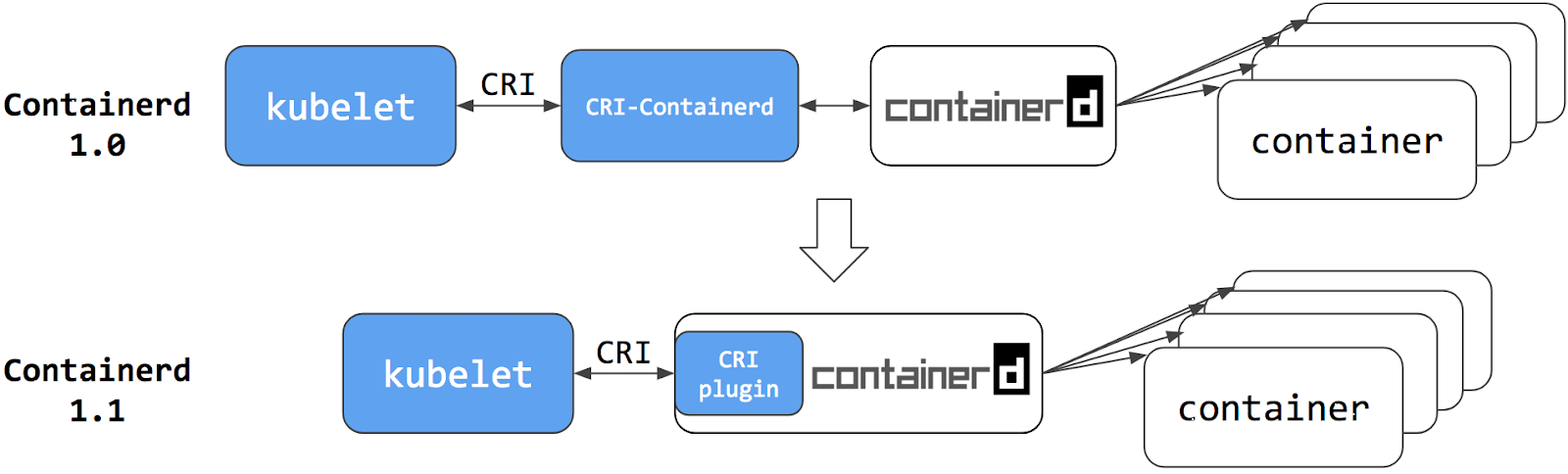
Kubernetes 从 1.10 版本宣布开始支持 containerd 1.1,在调用链中已经能够完全抹去 Docker Engine 的存在。此时,再观察 Kubernetes 到容器运行时的调用链,你会发现调用步骤会比通过 DockerShim、Docker Engine 与 containerd 交互的步骤要减少两步,用户只要愿意抛弃掉 Docker 情怀,在容器编排上便可至少省略一次 HTTP 调用,获得性能上的收益。
它实际上只是“弃用了 dockershim”这个小组件,也就是说把 dockershim 移出了 kubelet,并不是“弃用了 Docker”这个软件产品。
“弃用 Docker”对 Kubernetes 和 Docker 来说都不会有什么太大的影响,因为他们两个都早已经把下层都改成了开源的 containerd,原来的 Docker 镜像和容器仍然会正常运行,唯一的变化就是 Kubernetes 绕过了 Docker,直接调用 Docker 内部的 containerd 而已。