k8s教程05-Deployment滚动更新程序
Deployment,⽀持声明式地更新应⽤程序。
- Deployment是⼀种更⾼阶资源,⽤于部署应⽤程序并以声明的⽅式升级应⽤,⽽不是通过ReplicationController或ReplicaSet进⾏部署,它们都被认为是更底层的概念。
- 当创建⼀个Deployment时,ReplicaSet资源也会随之创建 。
- 在使⽤ Deployment 时 , 实 际 的 pod 是 由Deployment 的Replicaset创建和管理的,⽽不是由Deployment直接创建和管理的。
1. 更新应用版本
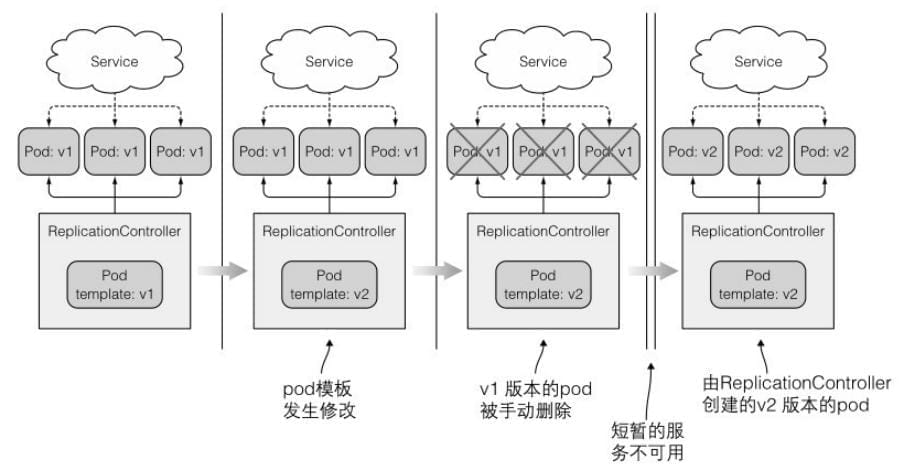
1.1 删除旧版本pod,⽤新版本pod替换
修改ReplicationController中的pod模板来升级并删除原有的pod。如果你可以接受从删除旧的pod到启动新pod之间短暂的服务不可⽤,那这将是更新⼀组pod的最简单⽅式。
1.2 创建新版本pod,再删除旧版本pod
这就是所谓的蓝绿部署。在切换之后,⼀旦 确 定 了 新 版 本 的 功 能 运 ⾏ 正 常 , 就 可 以 通 过 删 除 旧 的ReplicationController来删除旧版本的pod。
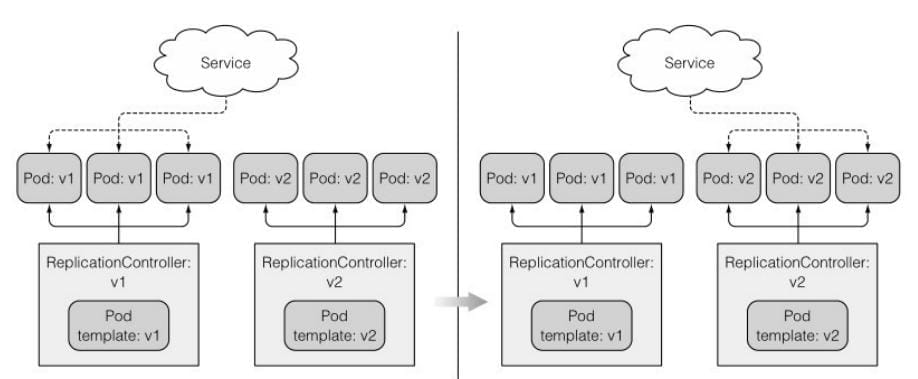
1.3 滚动升级
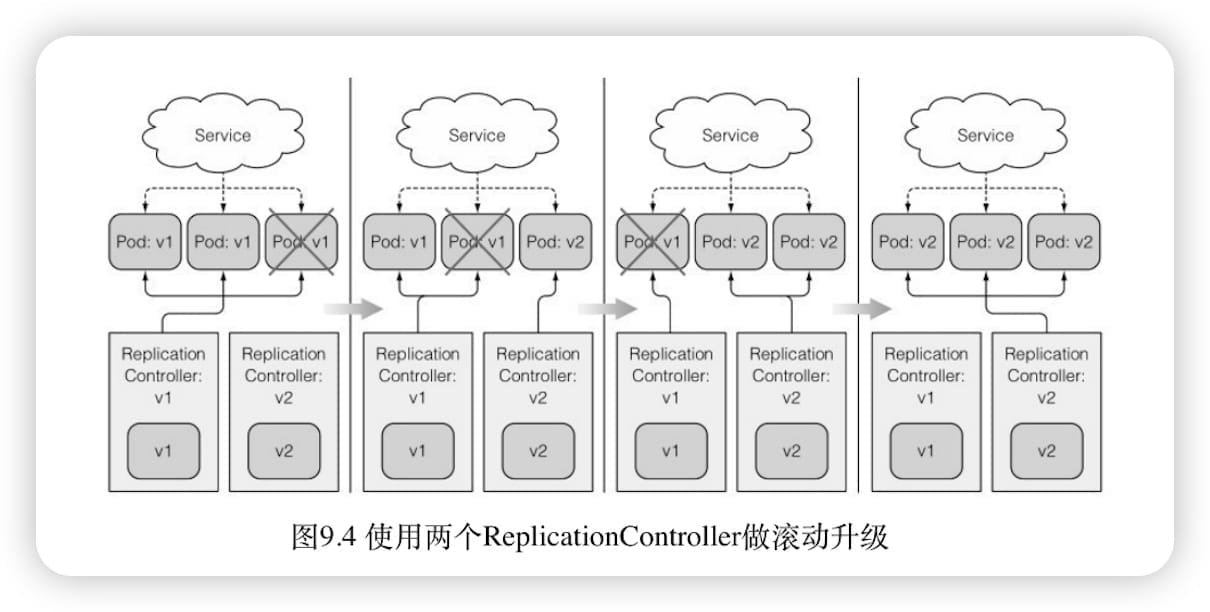
使⽤ReplicationController实现⾃动的滚动升级
kubectl 执⾏升级会使整个升级过程更容易。虽然这是⼀种相对过时的升级⽅式。
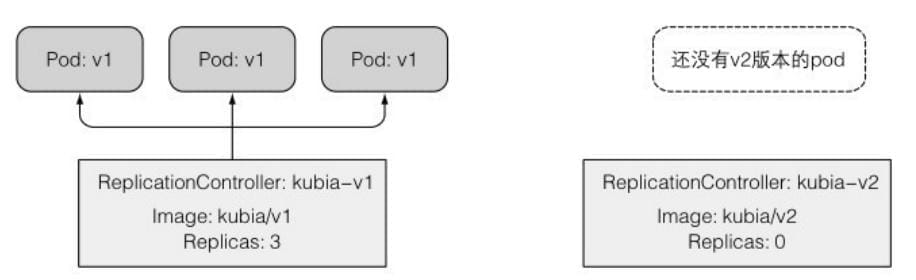
- v1 版本应用
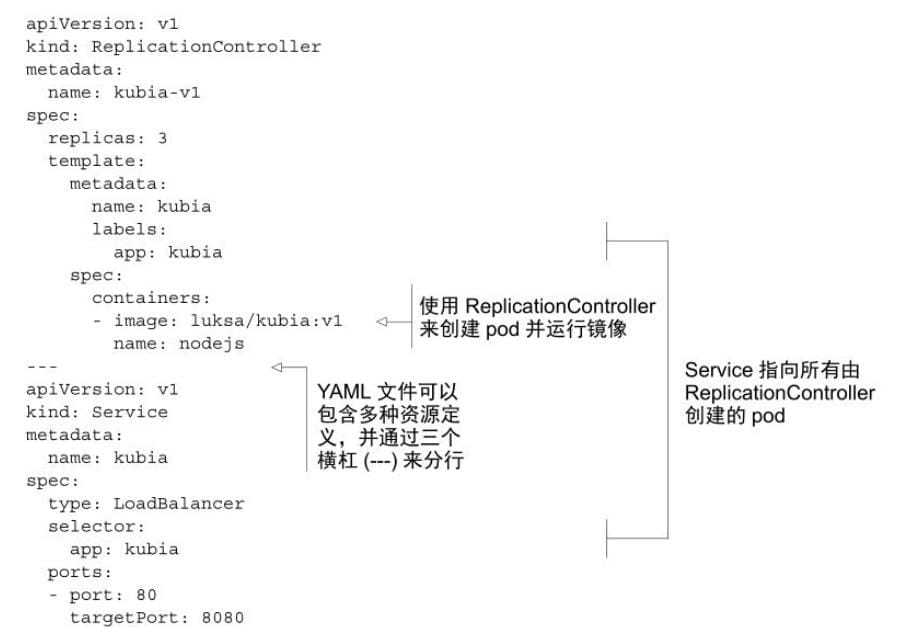

v2版本滚动升级
使 ⽤ kubia v2 版 本 应 ⽤ 来 替 换 运 ⾏ 着 kubia-v1 的ReplicationController , 将 新 的 复 制 控 制 器 命 名 为 kubia-v2 , 并 使 ⽤luksa/kubia:v2 作为容器镜像。

当你运⾏该命令时,⼀个名为kubia-v2 的新ReplicationController会⽴即被创建。
增加了额外的 deployment 标签。
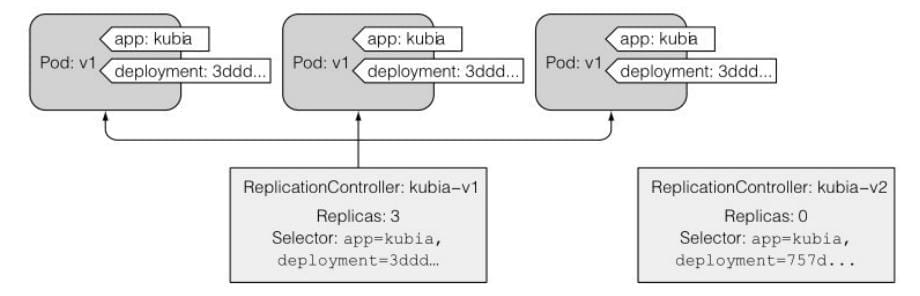
随着 kubectl 继续滚动升级,开始看到越来越多的请求被切换到 v2 pod。因为在升级过程中,v1 pod不断被删除,并被替换为运⾏新镜像的pod。
kubectl rolling-update已经过时
伸缩的请求是由kubectl 客户端执⾏的,⽽不是由Kubernetes master执⾏的。
但是为什么由客户端执⾏升级过程,⽽不是服务端执⾏是不好的呢?因为如果在 kubectl 执⾏升 级 时 失 去 了 ⽹ 络 连 接 , 升 级 进 程 将 会 中 断 。 pod 和ReplicationController最终会处于中间状态。
2. Deployment 滚动升级
2.1 创建
- 当创建⼀个Deployment时,ReplicaSet资源也会随之创建 。
- 使⽤ Deployment 时 ,实 际 的 pod 是 由 Deployment 的Replicaset创建和管理的,⽽不是由Deployment直接创建和管理的。
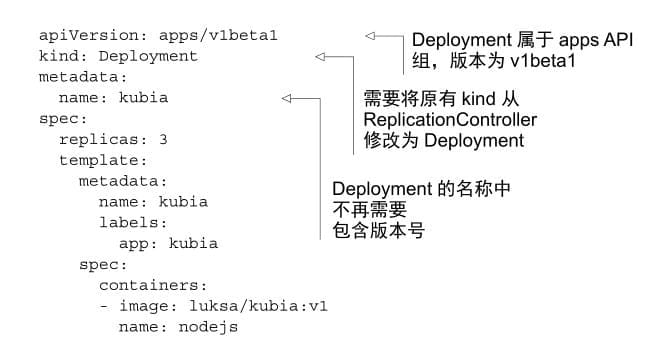


注意这个数字其实是 ReplicaSet 的hash 值。

2.2 滚动升级
如何达到新的系统状态的过程是由Deployment的升级策略决定的,默认策略是执⾏滚动更新(策略名为RollingUpdate)。另⼀种策略为Recreate,它会⼀次性删除所有旧版本的pod,然后创建新的pod。
更改容器的镜像

当执⾏完这个命令,kubia Deployment的pod模板内的镜像会被更改为luksa/kubia:v2(从:v1更改⽽来)
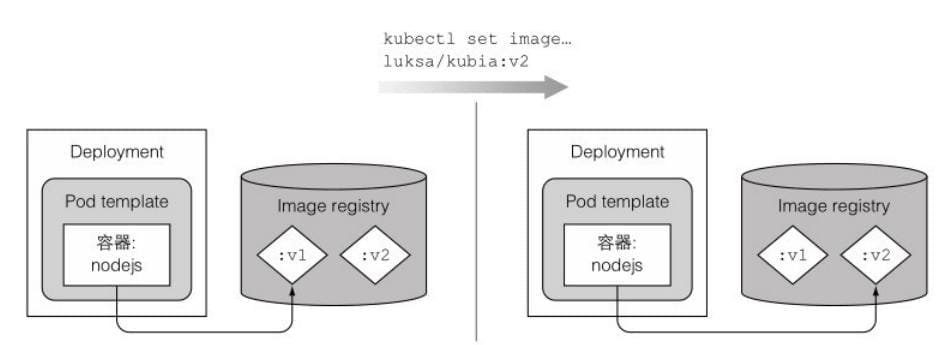
Deployment背后完成的整个升级过程和执⾏ kubectl rolling-update命令⾮常相似。⼀个新的ReplicaSet会被创建然后慢慢扩容,同时之前版本的Replicaset会慢慢缩容⾄0
2.3 回滚版本
Deployment可以⾮常容易地回滚到先前部署的版本,它可以让Kubernetes取消最后⼀次部署的Deployment:

在升级过程中已创建的pod会被删除并被⽼版本的pod替代。回滚升级之所以可以这么快地完成,是因为Deployment始终保持着升级的版本历史记录。之后也会看到,历史版本号会被保存在ReplicaSet中。
回滚特定的版本


2.4 控制滚动升级速率
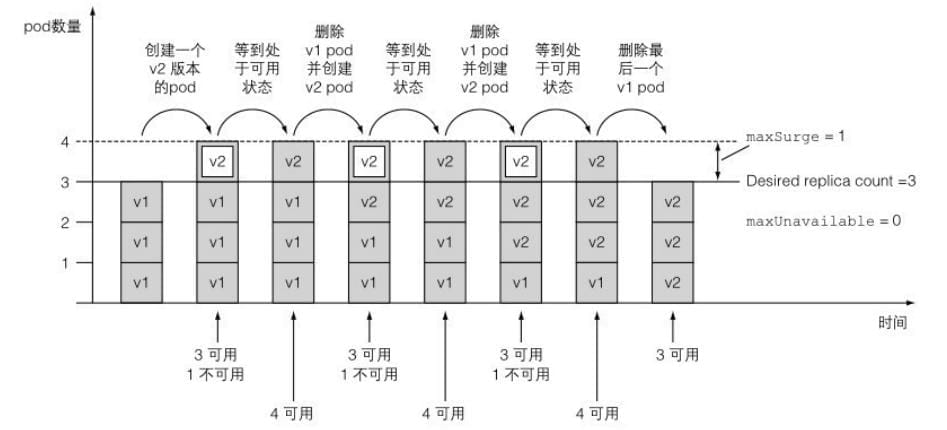
在Deployment的滚动升级期间,有两个属性会决定⼀次替换多少个pod:maxSurge和maxUnavailable。


由于在之前场景中,设置的期望副本数为3,上述的两个属性都设置为25%,maxSurge 允许最多pod数量达到 4,同时 maxUnavailable 不允许出现任何不可⽤的pod(也就是说三个pod必须⼀直处于可运⾏状态)
2.5 阻⽌出错版本的滚动升级
- minReadySeconds 属性指定新创建的pod⾄少要成功运⾏多久之后,才能将其视为可⽤。在pod可⽤之前,滚动升级的过程不会继续。
- 如果只定义就绪探针,没有正确设置 minReadySeconds,⼀旦有⼀次就绪探针调⽤成功,便会认为新的pod已经处于可⽤状态。因此最好适当地设置minReadySeconds 的值。
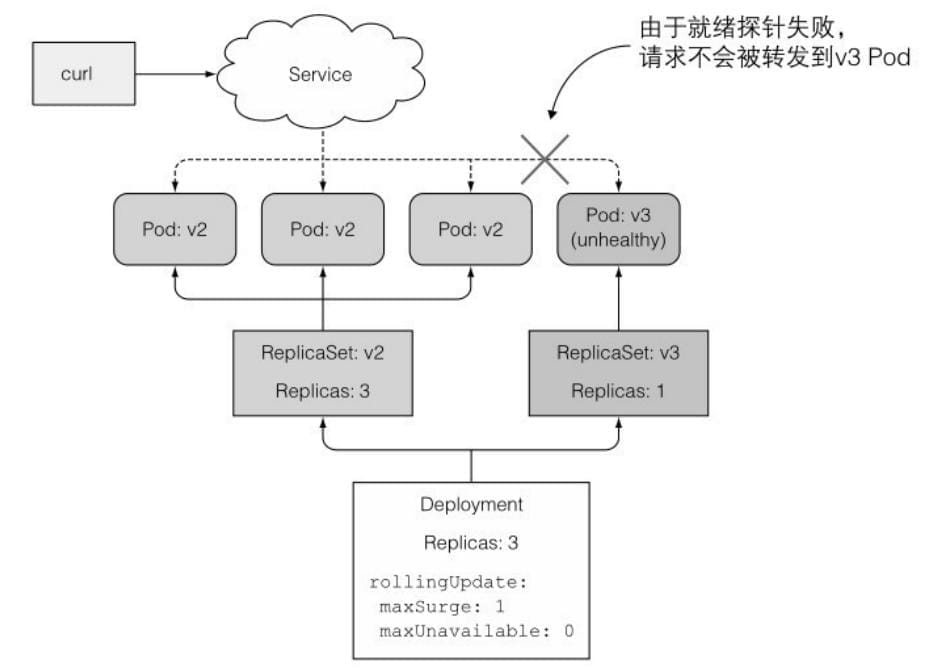
- 如果⼀个新的pod运⾏出错,并且在minReadySeconds 时间内它的就绪探针出现了失败,那么新版本的滚动升级将被阻⽌。

设置的v3版本有bug,5次访问后会报错,所以一直未就绪。

当新的pod启动时,就绪探针会每隔⼀秒发起请求(在pod spec中,就绪探针的间隔被设置为1秒)。在就绪探针失败时,pod会从Service的endpoint中移除。
3. 参考资料
- 《k8s in action》