golang的http库超时
1. Client 端
在作为客户端发送请求时,超时控制主要分两个层面:高层级的 http.Client 超时 和 低层级的 http.Transport 精细化控制。在大多数情况下,设置 http.Client.Timeout 就足够了,它可以有效地防止整个请求过程的无限期等待。
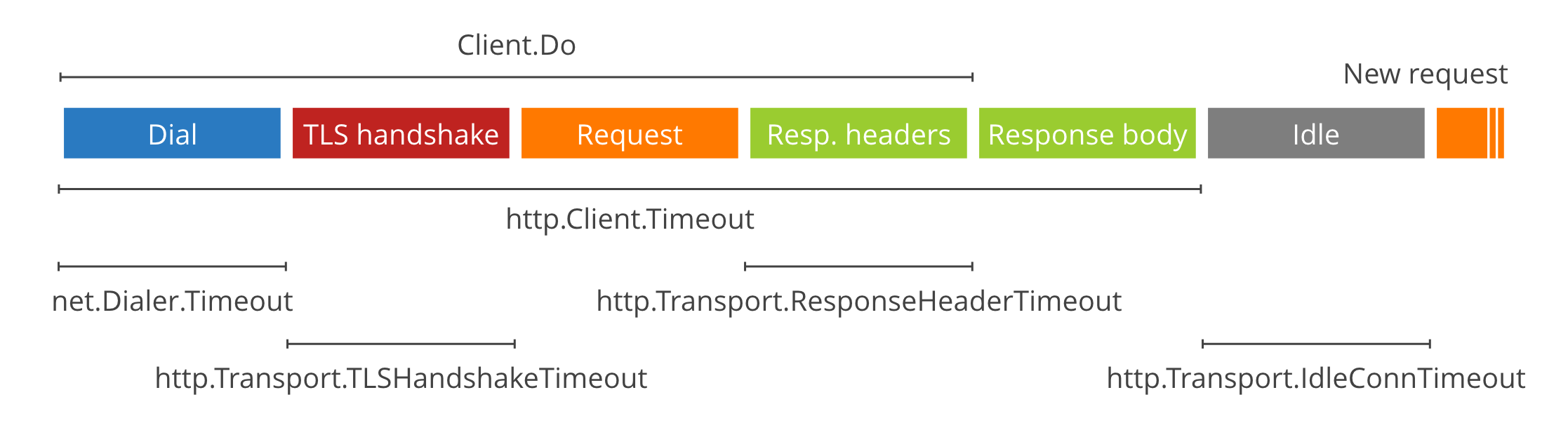
1.1 http.Client.Timeout
最简单,但有时太粗暴。这是最常用的设置,它控制包括连接、重定向(Redirects)以及读取响应体在内的整个请求生命周期的最大时长。
1 | c := &http.Client{ |
- 涵盖范围:Dial(拨号) -> TLS Handshake(握手) -> Request Headers/Body Send -> Response Headers Read -> Response Body Read。
- 优点:简单,能防止请求无限挂起。缺点:对于需要处理长流(Streaming)响应的请求(如下载大文件),这个超时如果不小心设置短了,连接会在中途被截断。
- 如果整个过程的累计时间超过
Timeout,请求会被强制取消,并返回net/http: request canceled (Client.Timeout exceeded)错误。
不需要依赖 Client 的全局配置:
- 使用
context是控制单个请求超时的最佳实践。 - 当
ctx超时或被 cancel 时,net/http库会立即关闭底层的 TCP 连接,从而中断请求。
1 | ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second) |
1.2 http.Transport
1 | t := &http.Transport{ |
- ResponseHeaderTimeout:非常有用。如果你连上服务器了,发了请求,但服务器处理逻辑卡死迟迟不回 Header,这个参数就会生效。
- 注意:Transport 中没有一个参数能直接限制 “ 发送 Request Body” 的时间。
2. Server 端
Server 端的超时设置更为关键,如果不设置,甚至可能导致 Slowloris 攻击(一种通过建立大量慢连接耗尽服务器资源的攻击)。服务器超时主要在 http.Server 结构体中配置。
1 | srv := &http.Server{ |
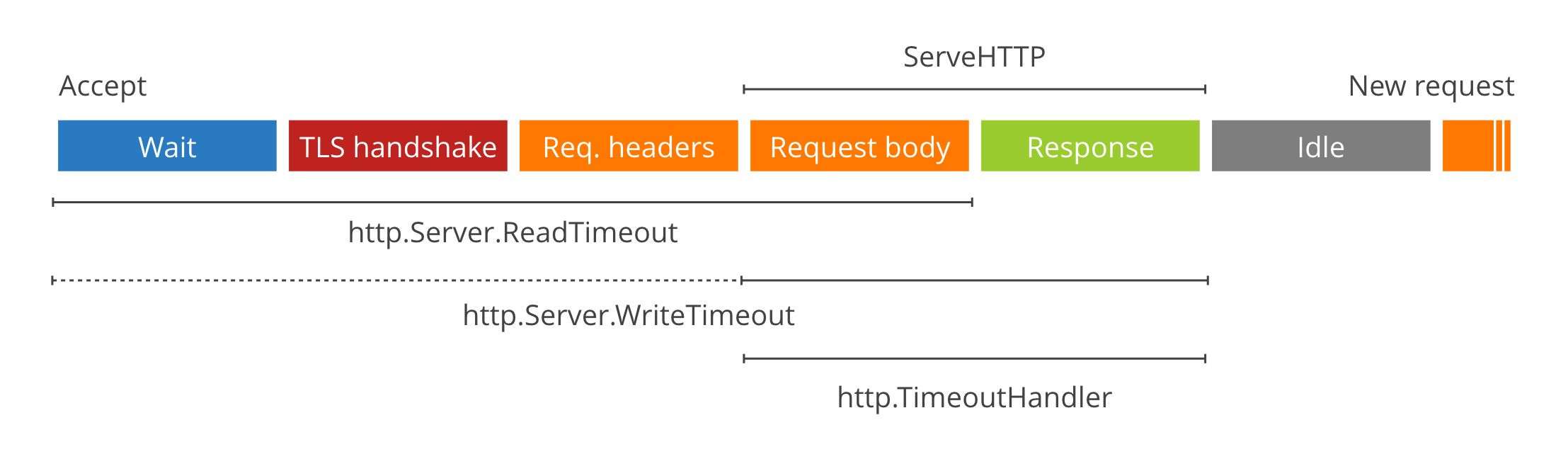
请求生命周期:Accept -> Read Headers -> Read Body -> Handle (你的业务逻辑) -> Write Response
ReadHeaderTimeout(非常重要)- 含义:从连接被 Accept 开始,到 Request Header 读取完毕的时间。
- 作用:防御 Slowloris 攻击。如果攻击者建立 TCP 连接后,很慢很慢地发送 Header,没有这个超时,服务器就会一直等。强烈建议设置。
ReadTimeout- 含义:涵盖了
ReadHeaderTimeout+ 读取 Request Body 的时间。 - 注意:如果你的 Handler 不读取 Body,或者 Body 很小,这个时间约等于读取 Header 的时间。但如果 Body 很大(如上传文件),这个时间必须设置得足够长,否则上传会中断。
- 含义:涵盖了
WriteTimeout- 含义:通常指从读取完 Request Header 结束开始,到 Response 写完为止。
- 注意:这包括了
Handle处理业务逻辑的时间。如果你的接口需要查询慢 SQL 耗时 5 秒,而 WriteTimeout 设为 3 秒,响应将无法成功写回,或者连接被提前断开。
IdleTimeout- 含义:当开启 Keep-Alive 时,一个请求结束后,等待下一个请求到来的时间。如果没设置,默认复用
ReadTimeout的值。
- 含义:当开启 Keep-Alive 时,一个请求结束后,等待下一个请求到来的时间。如果没设置,默认复用
注意点:
WriteTimeout虽然包含了 Handler 的处理时间,但它不会在 Handler 运行过久时中断 Handler 的执行(它只是在写回数据时报错)。如果你想硬性限制 Handler 的运行时间(例如:无论数据库查多久,3 秒必须返回给用户超时错误),你需要使用中间件http.TimeoutHandler。- 如果你想要 “ 真正 “ 取消任务(而不是仅仅超时输出),可以结合
context.WithTimeout使用。 r.Context()会在客户端连接断开、请求被取消或 Handler 返回后被取消。业务层、数据库访问和 RPC 调用都应该继续传递这个 ctx,而不是在请求链路里临时使用context.Background()。
1 | func main() { |
2.1 go-zero 的超时思路
go-zero 的 RestConf.Timeout 属于应用层超时,它不只是简单等同于 http.Server.ReadTimeout 或 WriteTimeout。常见做法是让传输层超时和应用层超时错开,避免最底层连接粗暴中断。
简化理解:
1 | timeout := ng.timeout |
ReadTimeout 设置为应用超时的 80%,主要是防止慢请求体长期占用连接。比如客户端声明了很大的 Content-Length,但只慢慢发送一小部分数据,服务端需要尽早释放这种连接。
WriteTimeout 设置为应用超时的 110%,是为了给响应写回留一点缓冲。如果业务逻辑几乎用满了应用层超时时间,服务端仍然需要一点额外时间把错误响应或正常响应写给客户端,否则客户端可能只收到一个被截断的响应。
这里要注意:传输层超时负责保护连接资源,应用层超时负责控制业务执行时间。真正想让数据库、RPC、下游 HTTP 请求停止工作,仍然要把 r.Context() 或派生出来的 context.WithTimeout 继续传下去。
3. 提问问题
底层原理
net.Conn 为 Deadline 提供了多个方法 Set[Read|Write]Deadline(time.Time)。Deadline 是一个绝对时间值,当到达这个时间的时候,所有的 I/O 操作都会失败,返回超时 (timeout) 错误。
Deadline 不是超时 (timeout)。一旦设置它们永久生效 (或者直到下一次调用 SetDeadline), 不管此时连接是否被使用和怎么用。所以如果想使用 SetDeadline 建立超时机制,你不得不每次在 Read/Write 操作之前调用它。
日常建议
- 永远不要在生产环境直接使用
http.Get("url")(因为它使用默认的DefaultClient,即无超时)。请务必自定义&http.Client{Timeout: ...}。 - Server 端:务必设置
ReadHeaderTimeout和ReadTimeout,这是防止资源耗尽的第一道防线。 - 上传/下载场景:对于涉及大文件传输的 Client 或 Server,不要设置过短的全局
Timeout,应该利用IdleConnTimeout并结合业务逻辑手动控制,或者对 Body 的读写操作单独进行流控。 - 业务处理超时:使用 context.WithTimeout 或 http.TimeoutHandler 来控制业务逻辑的执行时长。
最佳实践
对于 Client 端,最佳实践的目标是:快速失败(Fail Fast)。如果服务器挂了或者网络不通,不要让你的 goroutine 卡几分钟。
- 必须要设超时:用
http.Client.Timeout做兜底。 - 大文件下载特例:如果是下载文件,将
Client.Timeout设为 0,仅依赖Transport.ResponseHeaderTimeout(确保服务器开始响应了)和context(用于手动取消)。 - Context:养成习惯,所有请求都
WithContext,这样上层业务取消时,HTTP 请求也会立即中断。
Server 端的最佳实践目标是:自我保护。防止因为客户端的慢连接(如 2G 网络)或恶意攻击(Slowloris)耗尽服务器资源。
- 即使什么都不设,也要设
ReadHeaderTimeout:这是防止慢速攻击的底线。 - 区分场景:
- 通用 API 服务:设置
ReadTimeout和WriteTimeout。 - 上传/下载服务:
ReadTimeout和WriteTimeout建议设为 0 或非常大,完全依靠 TCP 层面的 KeepAlive 和业务逻辑中的流式读写超时控制。
- 通用 API 服务:设置
- 业务超时控制:推荐在 Handler 内部第一行代码就
ctx := r.Context(),并在调用数据库或 RPC 时传入这个 ctx。如果客户端断开了(触发了WriteTimeout或用户关闭了浏览器),这个 ctx 会被 cancel,你能节省后续的计算资源。
4. Resty 原始响应流处理
Resty 默认会在收到响应后解析 response body:根据 Content-Type 自动解析 JSON、XML,把结果填充到 SetResult() 或 SetError() 指定的结构中,并自动关闭响应流。
如果需要自己处理响应体,例如下载文件或处理大数据流,可以关闭自动解析:
1 | r.SetDoNotParseResponse(true) |
开启后要注意:
- Resty 不会自动消费响应体。
resp.RawBody()仍然是可读的io.ReadCloser。- 调用方必须自己读取并关闭 body。
示例:
1 | resp, err := client.R().Get(url) |
这个配置适合下载文件、流式处理、边读边写等场景;普通 JSON API 不建议开启,否则会丢掉 Resty 自动解析带来的便利。