rpc协议和功能介绍
1. RPC 介绍
RPC,全称是 Remote Procedure Call(远程过程调用)。它的核心思想非常纯粹:让你调用另一台计算机上的函数(或方法),就像调用本地函数一样简单、自然,而无需关心底层复杂的网络通信细节。
1.1 原因
微服务架构中,一个复杂的应用被拆分成了许多独立的服务(比如用户服务、订单服务、库存服务等)。这些服务部署在不同的机器上,甚至在不同的数据中心。
这时,一个核心问题出现了:这些服务之间如何高效、可靠地进行通信?
RPC 就是为了解决这个问题而生的。它的重要性在于:
- 简化开发:它将复杂的网络编程(如Socket建立、数据打包/解包、网络错误处理)封装起来,让程序员能更专注于业务逻辑本身。你写
result = userService.getUser(123)就行了,而不是去手动处理 TCP 连接和数据流。 - 提高性能:相比于通用的 HTTP/REST 风格,RPC 框架通常采用更紧凑的二进制数据格式(如 Protocol Buffers)和更高效的通信协议(如 HTTP/2),在内部服务间通信时,网络开销更小,速度更快。
- 明确契约:RPC 强制要求通信双方先定义好一个“契约”(接口定义文件),明确了可以调用哪些函数、参数和返回值是什么。这使得团队协作和系统集成变得更加清晰和不容易出错。
1.2 工作原理
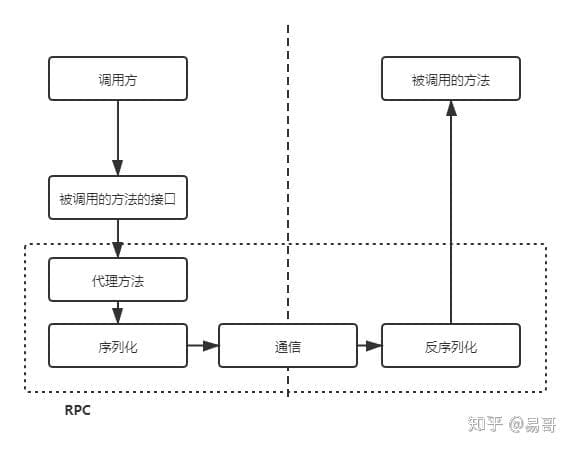
RPC 的“魔法”主要由框架的几个关键组件协同完成。我们来看看一次完整的 RPC 调用之旅:
- 客户端 (Client):业务代码的调用方。它想调用远程服务,于是执行一行看起来像本地调用的代码。
- 伪代码视角:
user_data = user_service_client.get_user_by_id(user_id: 42)
- 伪代码视角:
- 客户端存根 (Client Stub/Proxy):这是客户端的一个“本地代理”。它和要调用的远程函数有完全相同的方法签名。当你调用它时,它并不会执行业务逻辑,而是负责:
- 打包/序列化 (Marshalling/Serialization):将你调用的方法名(如
get_user_by_id)和参数(如42)打包成一个二进制或文本格式的数据包。 - 网络发送:通过底层网络库将这个数据包发送给服务端。
- 打包/序列化 (Marshalling/Serialization):将你调用的方法名(如
- 网络传输 (Network Transport):负责在客户端和服务端之间传递数据。可以是 TCP、UDP,或者在现代框架(如 gRPC)中是基于 HTTP/2。
- 服务端骨架 (Server Skeleton/Stub):服务端的“接线员”。它在服务端的端口上持续监听,等待来自客户端的请求。当请求到达时:
- 接收数据:从网络中读取数据包。
- 解包/反序列化 (Unmarshalling/Deserialization):将数据包“翻译”回方法名和参数。
- 服务端 (Server):这里是真正的业务逻辑实现。服务端骨架根据解包后的信息,调用本地的、真实的业务方法(
get_user_by_id(id: 42)),执行数据库查询等操作,然后返回结果。 - 返回过程:服务端将执行结果返回给服务端骨架 -> 骨架打包 -> 通过网络传回 -> 客户端存根接收并解包 -> 最终将结果返回给最开始的客户端调用代码。
对于你(程序员)来说,你只关心第 1 步和第 5 步的业务逻辑,中间的 2、3、4 步都由 RPC 框架透明地帮你完成了。这就是 RPC 的魅力所在。
1.3 涉及组件
一个完整的 RPC 调用,涉及的组件分为两类:
- RPC 框架核心组件:
- IDL 文件 (契约)
- 代码生成器 (Compiler)
- 客户端存根 (Stub) (负责打包、发送)
- 服务端骨架 (Skeleton) (负责接收、解包、分发)
- 序列化/反序列化器 (Serializer/Deserializer)
- 网络传输层 (Transport)
- 微服务生态/基础设施组件 (为了让 RPC 在分布式环境中稳定运行):
- 服务注册中心 (Service Registry) (电话本)
- 服务发现模块 (Service Discovery) (查电话本的动作)
- 负载均衡器 (Load Balancer) (决定打给哪个电话)
1.4 存根 (Stub)” 和 “骨架 (Skeleton)
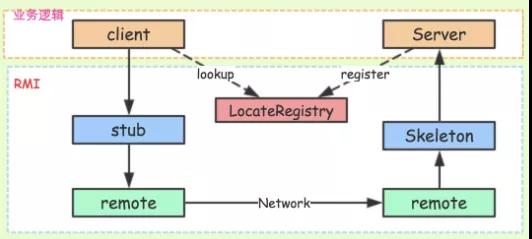
客户端存根 (Client Stub):
- 角色: 它是客户端的“代理人”。它存在于客户端,并伪装成远程服务,提供和远程服务一模一样的方法签名。
- 工作:当你的业务代码调用存根的方法时,存根会负责:
- 将调用的方法名和参数打包/序列化 (Marshalling) 成一个标准的数据包。
- 通过底层网络库,将这个数据包发送给服务端。
- 等待服务端的响应,并解包/反序列化 (Unmarshalling) 响应数据。
- 将最终结果返回给你的业务代码,完成这次“透明”的调用。
服务端骨架 (Server Skeleton):
- 角色: 它是服务端的“接线员”。它存在于服务端,负责接收请求并分发给真正的业务逻辑。
- 工作:
- 在服务端的特定端口上监听网络请求。
- 收到请求后,解包/反序列化数据包,解析出要调用的方法名和参数。
- 根据解析出的信息,调用开发者编写的、真实的业务逻辑实现。
- 拿到业务逻辑的返回结果后,再将其打包/序列化,通过网络发送回客户端。
简单来说,没有存根和骨架,RPC 就退化成了原始的、手写的 Socket 网络编程,其所有的便利性和优雅性都将不复存在。
1.5 框架
- grpc 是当之无愧的王者,性能、生态和通用性都非常出色,是新项目的默认选项。
- gRPC-Web,gRPC 的一个变种,允许 Web 浏览器(JavaScript)直接调用 gRPC 服务。需要一个代理层来转换 gRPC-Web 请求到标准的 gRPC HTTP/2 请求。
- 其他选择:Apache Thrift,Dubbo,Twirp。
2. RPC vs HTTP
2.1 与http 区别
这是架构选型时最经典的对比。它们不是“谁更好”,而是“谁更适合”。
| 特性 | RPC (以 gRPC 为例) | HTTP/REST |
|---|---|---|
| 设计哲学 | 行为/动词导向 (Action/Verb-Oriented) | 资源/名词导向 (Resource/Noun-Oriented) |
| 调用方式 | 像函数调用:updateUser(user) | 像操作资源:PUT /users/123 |
| 耦合度 | 高。客户端和服务端通过严格的契约(IDL文件)紧密耦合。 | 低。客户端和服务端通过 URL 和通用的 HTTP 方法(GET/POST)松散耦合。 |
| 数据格式 | 通常是二进制(如 Protocol Buffers),高效、紧凑,但不易读。 | 通常是文本(如 JSON),易读、易调试,但数据量稍大。 |
| 性能 | 高。二进制协议+长连接(HTTP/2 多路复用),非常适合内部服务间高频通信。 | 相对较低。文本解析+短连接(HTTP/1.1)有额外开销,但缓存友好。 |
| 调试 | 困难。二进制流量无法直接通过 curl 或浏览器查看,需要专用工具。 | 简单。可以用浏览器、curl、Postman 等任何 HTTP 工具轻松调试。 |
| 适用场景 | 内部微服务间通信、性能敏感的场景、对讲求效率的移动端App与后端通信。 | 对外开放的 API、Web 浏览器与后端通信、需要简单和普适性的场景。 |
2.2 和 http 是同一级别,还是被RPC包含
- RPC over HTTP?:一个有趣的事实是,gRPC 是构建在 HTTP/2 之上的。这让很多人惊讶,以为 RPC 和 HTTP 是完全对立的。实际上,gRPC 巧妙地利用了 HTTP/2 的多路复用、头部压缩、双向流等特性,实现了比传统 RPC 更强大的功能,同时还能复用现有的网络基础设施(如防火墙、代理)。
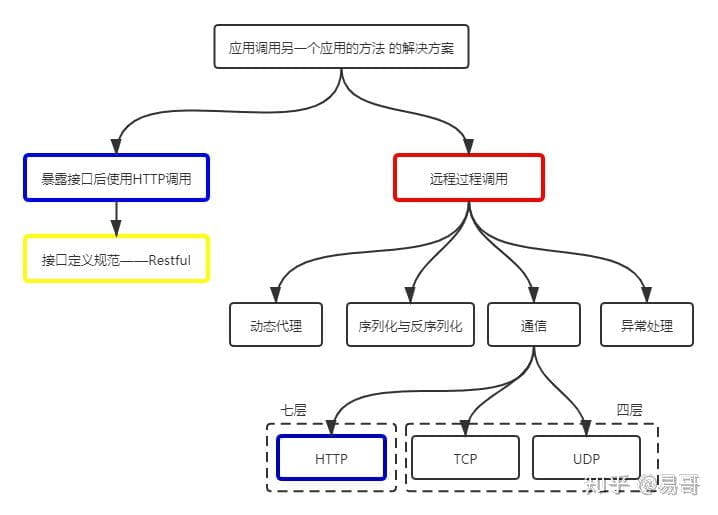
上图是一个比较完整的关系图,这时我们发现HTTP(图中蓝色框)出现了两次。其中一个是和RPC并列的,都是跨应用调用方法的解决方案;另一个则是被RPC包含的,是RPC通信过程的可选协议之一。
所以答案是都是对的,看指的是哪一个蓝色框。
3. 经验技巧
3.1 注意事项
契约先行 (Contract First):总是先定义好接口文件(如 gRPC 的
.proto文件)。这个文件是客户端和服务端唯一的真相来源。不要先写代码再反向生成契约。幂等性 (Idempotency):一个操作如果执行一次和执行 N 次的结果是相同的,它就是幂等的(如
GET /user/123)。要特别注意非幂等操作(如“扣减库存”)的重试问题,可能会导致重复执行。超时与重试 (Timeouts & Retries):远程调用可能因为网络问题变慢或失败。必须设置合理的超时时间,不能无限等待。对于幂等的操作,可以配置失败重试机制。
错误处理:要清晰地区分业务错误(如“用户不存在”)和网络错误(如“连接超时”)。RPC 框架通常会提供机制来处理这两种情况。
版本管理:当服务需要升级、修改接口时,要考虑向后兼容性,确保旧版本的客户端还能正常工作。
3.2 常见陷阱
本地调用”的错觉:这是最大的陷阱!虽然 RPC 代码看起来像本地调用,但它背后隐藏着网络。你必须时刻提醒自己:
忽略了延迟 (Latency): 本地函数调用耗时在纳秒或微秒级别,而一次网络来回(RPC 调用)至少是毫秒级别,慢了成千上千倍。如果在一个循环里频繁进行 RPC调用,会造成巨大的性能瓶颈。
忽略了失败的可能性 (Failure): 本地调用几乎总能成功,但网络是不可靠的。网络会中断、服务器会超时或崩溃。如果不为 RPC 调用设计超时、重试和错误处理逻辑,系统就会非常不稳定。
它涉及数据传输:传递一个大对象作为参数,在本地是引用传递,成本极低;在 RPC 中则意味着完整的数据序列化和网络传输,成本高昂。这会导致所谓的“Chatty API”(过于频繁的、小数据的调用),严重影响性能。
忽略接口演进:在
.proto文件里随便改个字段名或类型,然后只部署了服务端,结果所有老版本的客户端都崩溃了。必须学习并遵循接口的向后兼容和向前兼容规则。不合适的选型:为一个需要频繁迭代、提供给第三方开发者使用的公用 API 选择了 gRPC,导致对方接入成本很高,调试困难。这种场景,HTTP/REST 可能才是更合适的选择。
3.3 交付语义 (Delivery Semantics)
在分布式系统中,一次调用有三种语义:At-most-once (最多一次,可能丢失)、At-least-once (最少一次,可能重复)、Exactly-once (恰好一次)。
大多数 RPC 框架默认提供 “At-least-once”,需要应用层面自己保证幂等性才能实现事实上的 “Exactly-once”。
4. 提问问题
4.1 grpc 可以替代 socket 吗
不,gRPC 流式通信不能完全取代 Socket,它们是不同抽象层次的工具,解决不同粒度的问题。
把它们的关系想象成汽车和引擎:
- Socket 就像是汽车的引擎。它强大、基础、提供原始动力。你可以用引擎来造汽车、发电机、甚至飞行器。它给你最大的灵活性和控制力,但你也必须自己动手造变速箱、方向盘、车身和刹车。
- gRPC Streaming 就像是一辆高性能的成品跑车 (比如保时捷 911)。它内置了强大的引擎 (Socket/TCP/HTTP/2),并且为你配备了先进的变速箱、空气动力学车身、舒适的座椅和顶级的安全系统。你开箱即用,能以极高的效率和舒适度从 A 点到 B 点,但你无法轻易地把它改装成一艘船。
例如你需要开发一个邮件客户端 (SMTP)、一个 FTP 客户端,或者与某个只支持自定义私有二进制协议的旧硬件通信。这些协议不运行在 HTTP 之上,你必须使用 Sockets 来实现它们的底层通信逻辑。
4.2 grpc 四种通信模式怎么选择
gRPC 提供的四种通信模式(一元、服务端流、客户端流、双向流),这在处理大数据流、实时通信等场景下非常强大。
一元 RPC (Unary RPC): 问一个问题,得到一个答案。
服务端流 (Server Streaming):订阅一份杂志。 “我订阅了你们的新闻,有新的就发给我。” -> “这是今天的新闻… 这是明天的新闻…”
客户端流 (Client Streaming):上传相册到云盘。 “我要上传照片了,这是第一张… 第二张… 第N张… 传完了!” -> “好的,全部收到,已为你生成相册。”
双向流 (Bidirectional Streaming): 在线客服实时聊天。
4.3 断线重连是谁做?
你需要自己处理“业务层面”的重连和状态恢复。gRPC 本身不保证在流中断后,能像什么都没发生一样自动恢复你的业务会话。
- gRPC 能做什么:底层的“连接”管理
- gRPC 客户端在设计上是有韧性的 (resilient)。它管理着底层的 HTTP/2 连接。
- 如果网络发生了一个短暂的、无感知的“抖动”(比如一个路由器重启),TCP 连接可能会断开。gRPC 客户端通常会自动尝试重新建立这个 TCP 连接,这个过程对上层应用是透明的。
- 这就像你的手机信号断了一瞬间又立刻恢复了。
- 你需要做什么:上层的“流”或“RPC 调用”管理
- 当底层的连接真正断开足够长的时间,导致你的 RPC 调用超时,或者服务器/网络明确地中断了会话,那么你正在进行的那个流(Stream)会立即失败。
- 客户端的代码会收到一个错误,通常是
StatusCode.UNAVAILABLE或类似的错误码。 - 这时,gRPC 的使命就完成了。它已经忠实地告诉你:“伙计,这通电话断了!”
- gRPC 不会知道:
- 你刚才聊到哪了?(业务状态)
- 断开前,对方说的最后一句话你听到了吗?(消息确认)
- 要不要重拨?(重连策略)
- 重拨后,要不要把刚才的话重复一遍?(状态恢复)