服务熔断机制和golang的实现
微服务集群中,每个应用基本都会依赖一定数量的外部服务。如果依赖服务过载,服务不可用的情况,在高并发场景下如果此时调用方不做任何处理,继续持续请求故障服务的话很容易引起整个微服务集群雪崩。
所以应该采用熔断的策略,不再调用下游服务。
首先先区分下熔断、限流、降级区别
限流
是针对服务请求数量的一种自我保护机制,当请求数量超出服务负载时,自动丢弃新的请求,是系统高可用架构的第一步。
熔断
是调用方自我保护的机制(客观上也能保护被调用方),熔断对象是外部服务。
降级
是被调用方(服务提供者)的防止因自身资源不足导致过载的自我保护机制,降级对象是自身。
| 触发条件 | 面向目标 | |
|---|---|---|
| 限流 | 上游服务请求多 | 上游 |
| 熔断 | 下游服务不可用 | 下游 |
| 降级 | 服务自身负载高 | 自身 |
1. 熔断
1.1 熔断机制
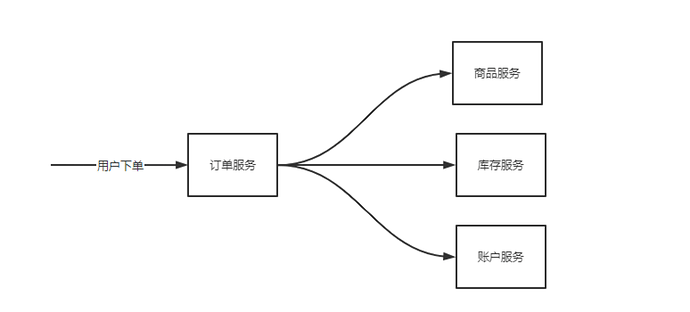
假如此时 账户服务 过载,订单服务持续请求账户服务只能被动的等待账户服务报错或者请求超时,进而导致订单请求被大量堆积,这些无效请求依然会占用系统资源:cpu,内存,数据连接…导致订单服务整体不可用。即使账户服务恢复了订单服务也无法自我恢复。
这时如果有一个主动保护机制应对这种场景的话,订单服务至少可以保证自身的运行状态,等待账户服务恢复时订单服务也同步自我恢复,这种自我保护机制在服务治理中叫熔断机制。
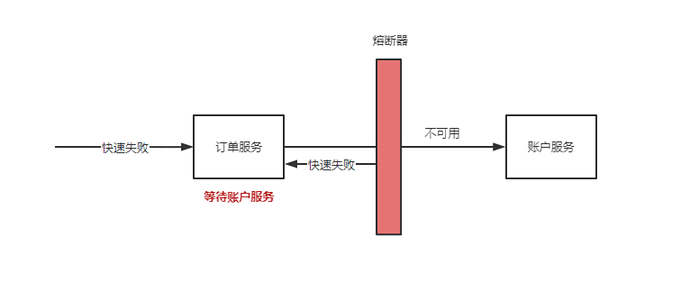
1.2 熔断原理 (netflix hystrix)
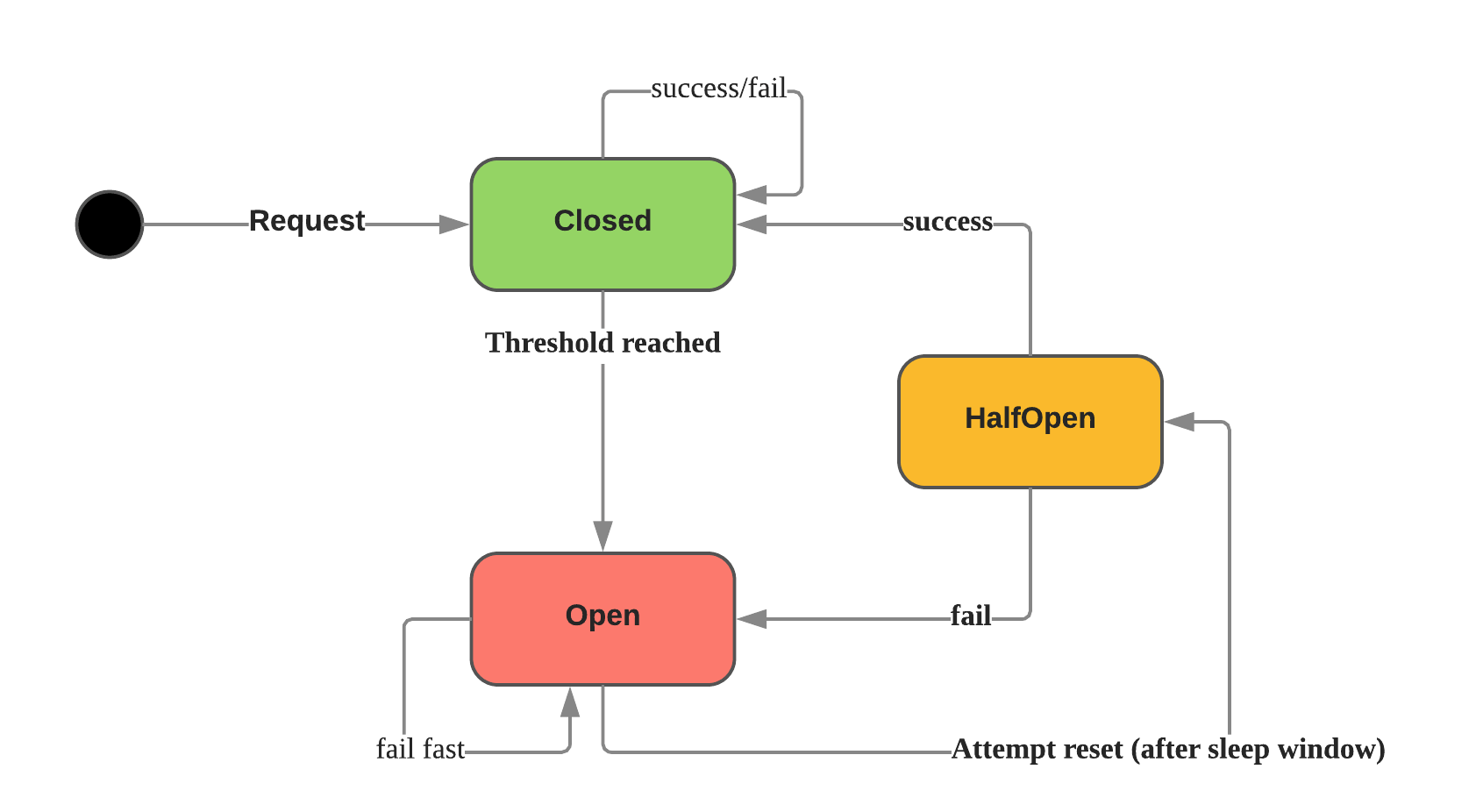
熔断器一般具有三个状态:
关闭:默认状态,请求能被到达目标服务,同时统计在窗口时间成功和失败次数,如果达到错误率阈值将会进入断开状态。
断开: 此状态下将会直接返回错误,如果有 fallback 配置则直接调用 fallback 方法。
半断开:进行断开状态会维护一个超时时间,到达超时时间开始进入 半断开 状态。
尝试允许一部分请求正常通过并统计成功数量,如果请求正常则认为此时目标服务已恢复进入关闭 状态,否则进入断开状态。
半断开 状态存在的目的在于实现了自我修复,同时防止正在恢复的服务再次被大量打垮。
1.3 自适应熔断(google sre)
项目中我们要使用好熔断器通常需要准备以下参数:
- 错误比例阈值:达到该阈值进入 断开 状态。
- 断开状态超时时间:超时后进入 半断开 状态。
- 半断开状态允许请求数量。
- 窗口时间大小。
google sre 20提供了一种自适应熔断算法来计算丢弃请求的概率:

其中每个变量的含义是:
- requests:发起请求的总数
- accepts:后端接受的请求数
- K:一般建议该值在1.1~2之间。数字越小触发熔断的概率越高,反之则越低。如果K=2,意味着我们认为每接受 10 个请求,后端正常情况下最多只会拒绝 5 个请求,如果发现拒绝了6个,就触发熔断。
算法解释:
- 正常情况下 requests=accepts,所以概率是 0。
- 随着正常请求数量减少,当达到 requests == K* accepts 继续请求时,概率 P 会逐渐比 0 大开始按照概率逐渐丢弃一些请求,如果故障严重则丢包会越来越多,假如窗口时间内 accepts==0 则完全熔断。
- 当应用逐渐恢复正常时,accepts、requests 同时都在增加,但是 K*accepts 会比 requests 增加的更快,所以概率很快就会归 0,关闭熔断。
2. golang实现
参考实现:
- https://github.com/afex/hystrix-go/ (网飞)
- https://github.com/zeromicro/go-zero/tree/master/core/breaker
- https://github.com/go-kratos/aegis/tree/main/circuitbreaker
- https://github.com/sony/gobreaker
- https://github.com/eapache/go-resiliency/tree/main/breaker
2.1 hystrix-go
1 | package main |

hystrix-go已经可以比较好的满足我们的需求,但是存在一个问题就是一旦触发了熔断,在一段时间之类就会被一刀切的拦截请求,所以来看看 google sre 的一个实现。
2.2 go zero
1 | package main |
以上的输出内容不是固定的,每次运行的结果都不同(为什么不同后面会提到原因)。其中“func circuit breaker is open”表示 Do()函数中的 func() error 直接被熔断器拦截了,没有实际执行。
2.3 gin 熔断
注意熔断是上层控制的事情,gin一般是下游web服务。gin一般不会把熔断当成自己的中间件。