时序数据库简介
1. 时间序列数据库 Time Series Database (TSDB)
随着分布式系统监控、物联网的发展,TSDB开始受到更多的关注。
时间序列数据跟关系型数据库有太多不同,但是很多公司并不想放弃关系型数据库。 于是就产生了一些特殊的用法,比如用 MySQL 的 VividCortex, 用 Postgres 的 Timescale。 很多人觉得特殊的问题需要特殊的解决方法,于是很多时间序列数据库从头写起,不依赖任何现有的数据库, 比如 Graphite,InfluxDB。
1.1 时序概念
时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
1.2 数据写入特点
写入平稳、持续、高并发高吞吐
时序数据的写入是比较平稳的,这点与应用数据不同,应用数据通常与应用的访问量成正比,而应用的访问量通常存在波峰波谷。时序数据的产生通常是以一个固定的时间频率产生,不会受其他因素的制约,其数据生成的速度是相对比较平稳的。
写多读少
时序数据上95%-99%的操作都是写操作,是典型的写多读少的数据。这与其数据特性相关,例如监控数据,你的监控项可能很多,但是你真正去读的可能比较少,通常只会关心几个特定的关键指标或者在特定的场景下才会去读数据。
实时写入最近生成的数据,无更新
时序数据的写入是实时的,且每次写入都是最近生成的数据,这与其数据生成的特点相关,因为其数据生成是随着时间推进的,而新生成的数据会实时的进行写入。数据写入无更新,在时间这个维度上,随着时间的推进,每次数据都是新数据,不会存在旧数据的更新,不过不排除人为的对数据做订正。
1.3 数据查询和分析特点
- 按时间范围读取:通常来说,你不会去关心某个特定点的数据,而是一段时间的数据。
- 最近的数据被读取的概率高
- 历史数据粗粒度查询的概率搞
- 多种精度查询
- 多维度分析
1.4 数据存储的特点
- 数据量大:拿监控数据来举例,如果我们采集的监控数据的时间间隔是1s,那一个监控项每天会产生86400个数据点,若有10000个监控项,则一天就会产生864000000个数据点。在物联网场景下,这个数字会更大。整个数据的规模,是TB甚至是PB级的。
- 冷热分明:时序数据有非常典型的冷热特征,越是历史的数据,被查询和分析的概率越低。
- 具有时效性:时序数据具有时效性,数据通常会有一个保存周期,超过这个保存周期的数据可以认为是失效的,可以被回收。一方面是因为越是历史的数据,可利用的价值越低;另一方面是为了节省存储成本,低价值的数据可以被清理。
- 多精度数据存储:在查询的特点里提到时序数据出于存储成本和查询效率的考虑,会需要一个多精度的查询,同样也需要一个多精度数据的存储。
2. 数据
2.1 数据模型
时间序列数据可以分成两部分
序列 :就是标识符(维度),主要的目的是方便进行搜索和筛选
数据点:时间戳和数值构成的数组
行存:一个数组包含多个点,如 [{t: 2017-09-03-21:24:44, v: 0.1002}, {t: 2017-09-03-21:24:45, v: 0.1012}]
列存:两个数组,一个存时间戳,一个存数值,如[ 2017-09-03-21:24:44, 2017-09-03-21:24:45], [0.1002, 0.1012]
一般情况下:列存能有更好的压缩率和查询性能
2.2 基本概念
- metric: 度量,相当于关系型数据库中的table。
- data point: 数据点,相当于关系型数据库中的row。
- timestamp:时间戳,代表数据点产生的时间。
- field: 度量下的不同字段。比如位置这个度量具有经度和纬度两个field。一般情况下存放的是会随着时间戳的变化而变化的数据。
- tag: 标签,或者附加信息。一般存放的是并不随着时间戳变化的属性信息。timestamp加上所有的tags可以认为是table的primary key。
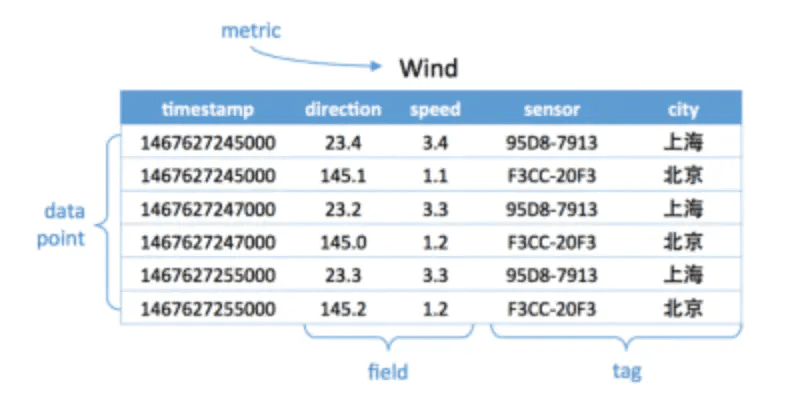
如下图,度量为Wind,每一个数据点都具有一个timestamp,两个field:direction和speed,两个tag:sensor、city。它的第一行和第三行,存放的都是sensor号码为95D8-7913的设备,属性城市是上海。随着时间的变化,风向和风速都发生了改变,风向从23.4变成23.2;而风速从3.4变成了3.3。
3. 开源时间序列数据库
3.1 时间线
- 1999/07/16 RRDTool First release
- 2009/12/30 Graphite 0.9.5
- 2011/12/23 OpenTSDB 1.0.0
- 2013/05/24 KairosDB 1.0.0-beta
- 2013/10/24 InfluxDB 0.0.1
- 2014/08/25 Heroic 0.3.0
- 2017/03/27 TimescaleDB 0.0.1-beta
RRDTool 是最早的时间序列数据库,它自带画图功能,现在大部分时间序列数据库都使用Grafana来画图。
Graphite 是用 Python 写的 RRD 数据库,它的存储引擎 Whisper 也是 Python 写的, 它画图和聚合能力都强了很多,但是很难水平扩展。
OpenTSDB 使用 HBase 解决了水平扩展的问题
KairosDB 最初是基于OpenTSDB修改的,但是作者认为兼容HBase导致他们不能使用很多 Cassandra 独有的特性, 于是就抛弃了HBase仅支持Cassandra。
新发布的 OpenTSDB 中也加入了对 Cassandra 的支持。 故事还没完,Spotify 的人本来想使用 KairosDB,但是觉得项目发展方向不对以及性能太差,就自己撸了一个 Heroic。
InfluxDB 早期是完全开源的,后来为了维持公司运营,闭源了集群版本。 在 Percona Live 上他们做了一个开源数据库商业模型正面临危机的演讲,里面调侃红帽的段子很不错。 并且今年的 Percona Live 还有专门的时间序列数据库单元。
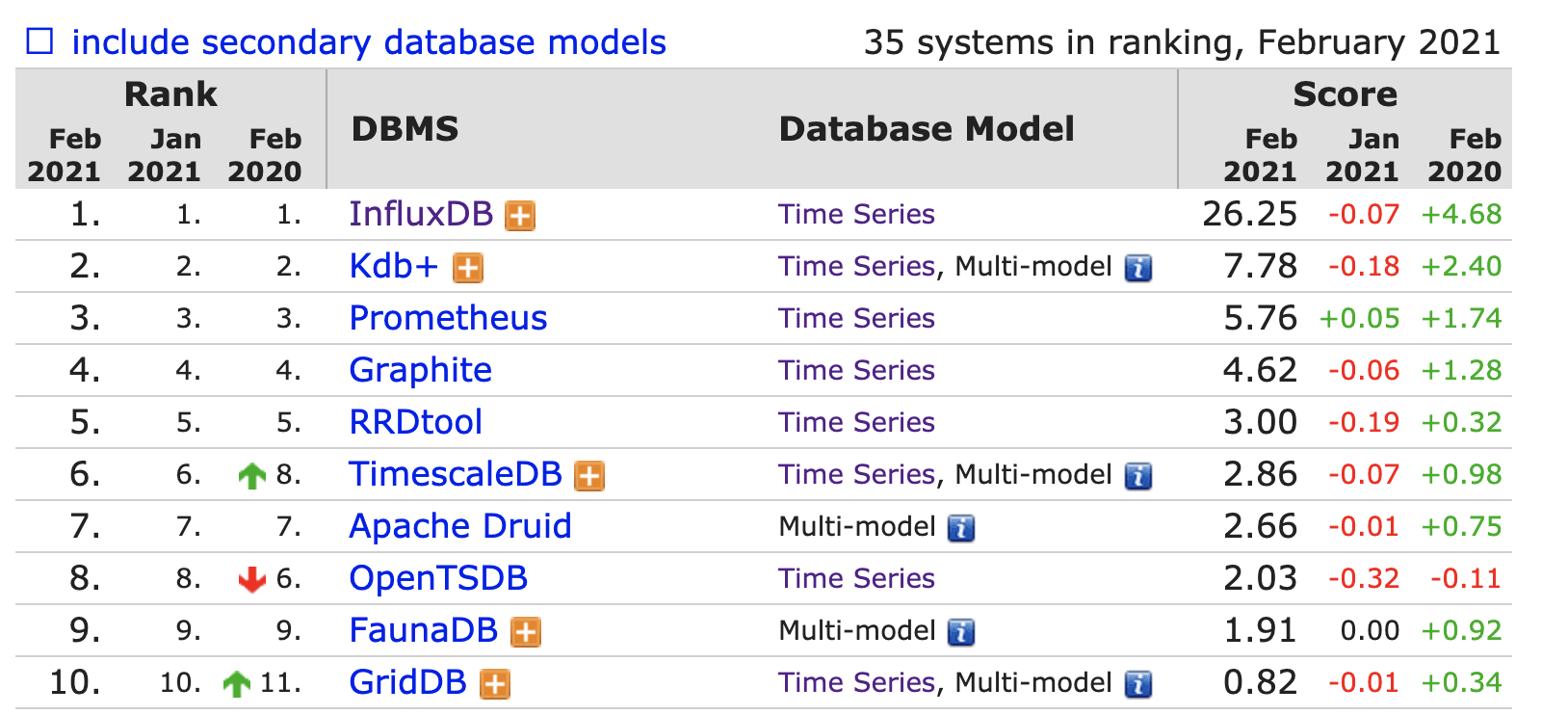
3.2 目前排名
https://db-engines.com/en/ranking/time+series+dbms
4. InfluxDB
InfluxDB 就是一款非常优秀的时序数据库,高居 DB-Engines TSDB rank 榜首。InfluxDB 分为免费的社区开源版本,以及需要收费的闭源商业版本,目前只有商业版本支持集群。
InfluxDB 的底层数据结构从 LSM 树到 B+ 树折腾了一通,最后自创了一个 TSM 树( Time-Structured Merge Tree ),这也是它性能高且资源占用少的重要原因。
Time Structured Merge Tree (TSM) 和 Log Structured Merge Tree (LSM) 的名字都有点误导性,关键并不是树,也不是日志或者时间,而是 Merge。
- 写入的时候,数据先写入到内存里,之后批量写入到硬盘。
- 读的时候,同时读内存和硬盘然后合并结果。
- 删除的时候,写入一个删除标记,被标记的数据在读取时不会被返回。
- 后台会把小的块合并成大的块,此时被标记删除的数据才真正被删除
- 相对于普通数据,有规律的时间序列数据在合并的过程中可以极大的提高压缩比。