zsh主题powerlevel9k升级到powerlevel10k
为什么升级?
Powerlevel9k项目不再维护,Powerlevel10k更快更强大(10-100倍的性能提升)。
Powerlevel10k并且完美兼容Powerlevel9k, 以前的配置参数可以不用任何修改.
为什么升级?
Powerlevel9k项目不再维护,Powerlevel10k更快更强大(10-100倍的性能提升)。
Powerlevel10k并且完美兼容Powerlevel9k, 以前的配置参数可以不用任何修改.
hazel 是一款可以自动监控并整理文件夹的工具,其官网的介绍就是简单的一句话:Automated Organization for Your Mac。
它的使用有点类似于网络服务 IFTTT,你可以设定一个 if 条件,如果被监控的文件夹出现符合条件的项,那么对其执行 then 的操作(也可以通过邮箱的收件过滤规则来理解)。
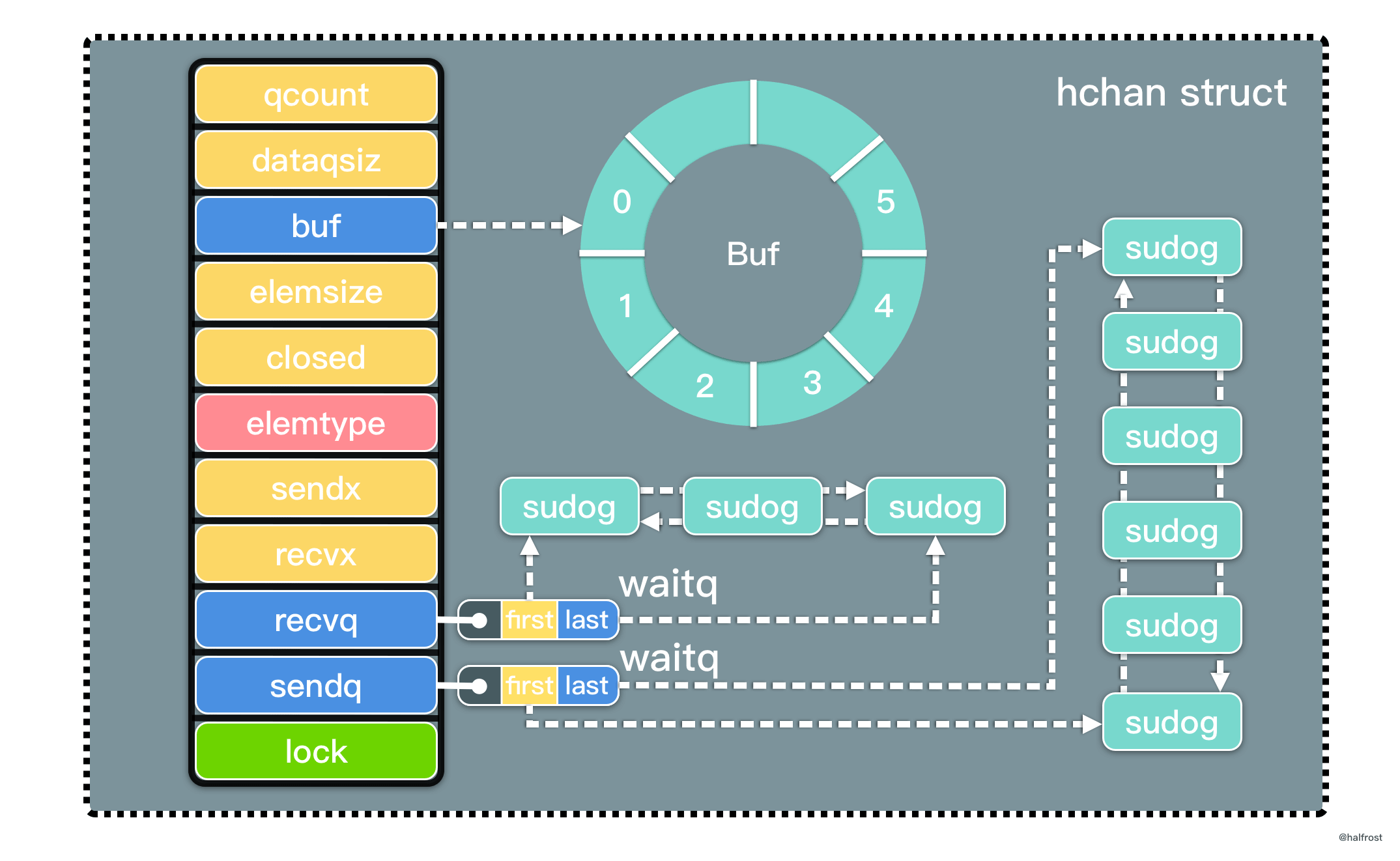
在 Go 语言中,interface 和函数一样,都是“第一公民”。interface 可以用在任何使用变量的地方。可以作为结构体内的字段,可以作为函数的形参和返回值,可以作为其他 interface 定义的内嵌字段。
interface 在大型项目中常常用来解耦。在层与层之间用 interface 进行抽象和解耦。由于 Go interface 非侵入的设计,使得抽象出来的代码特别简洁,这也符合 Go 语言设计之初的哲学。
grep是Linux中最常用的”文本处理工具”之一,grep与sed、awk合称为Linux中的三剑客。
我们可以使用grep命令在文本中查找指定的字符串,就像打开txt文件,使用 “Ctrl+F” 在文本中查找某个字符串一样,说白了,可以把grep理解成字符查找工具。