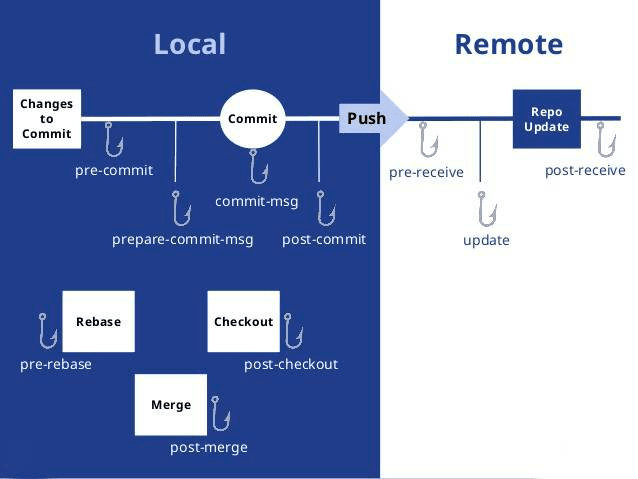
1. 文件夹,标签,双向链接
1.1 文件夹

文件夹其实就是「树」。从定义上就可以看出树的性质:每一个节点只会存在于唯一一个地方。
我的知识管理工作流整体来说非常简单,只有三步:
• I-Inbox:输入,即知识、信息的获取;
• P-Process:加工,即对知识、信息进行要点提取、整合、理解、内化、总结等处理;
• O-Output:输出,即写作、分享并获取反馈。
输入(readwise & raindrop)–> Obsidian同步整合信息 –> 输出(typora + blog)
1 | # 查看健康 |
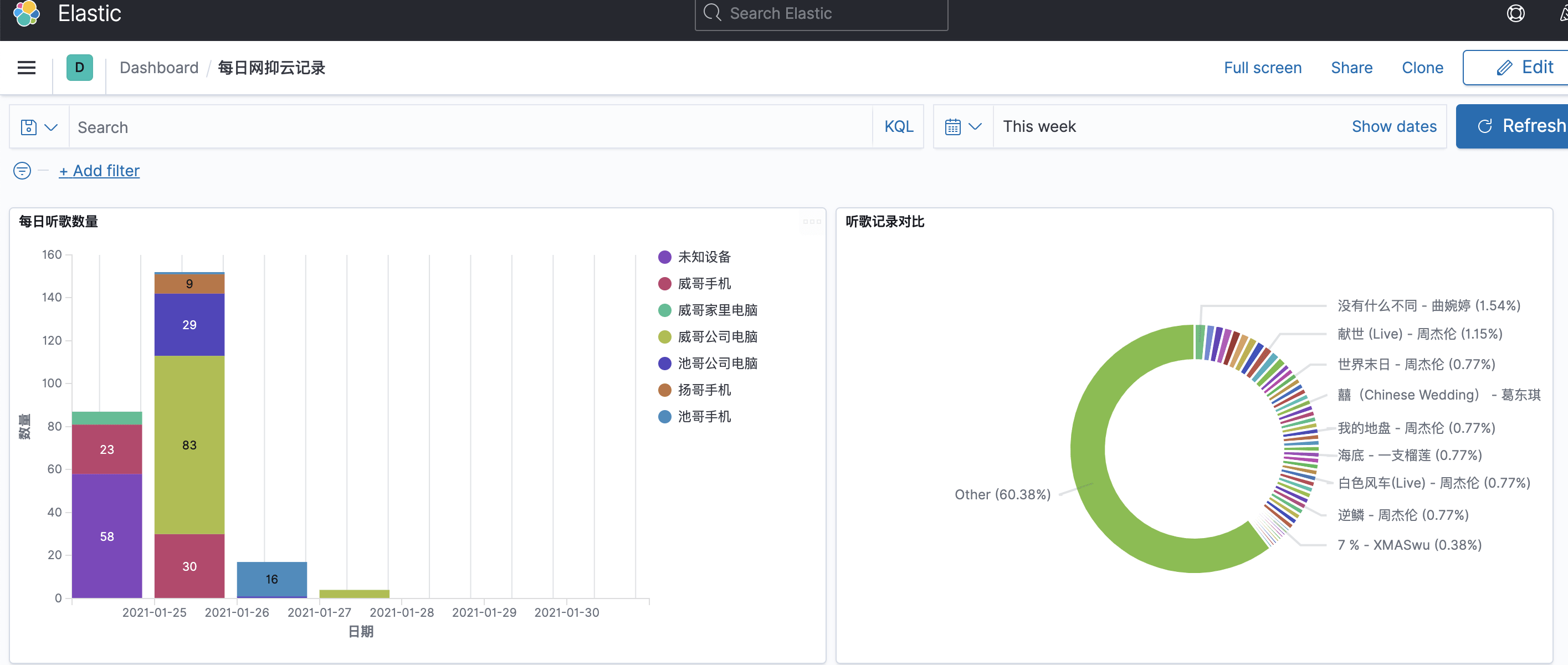
打工人每日网抑云, 所以就用 es简单做个网易云听歌记录. 先上效果图.
当您遇到如下问题时,可以使用分片集群解决:
许多人对复制和分片之间的区别感到困惑。记住,复制在多台服务器上创建了数据的精确副本,因此每台服务器都是其他服务器的镜像。相反,每个分片包含了不同的数据子集。
fzf是一个通用的命令行模糊查找器, 通过输入模糊的关键词就可以定位文件或文件夹。结合其他工具(比如rg)可以完成非常多的工作,在工作中可以大幅提高你的工作效率。
fzf可以用于文件、命令历史记录、进程、主机名、书签、git提交等。