当您遇到如下问题时,可以使用分片集群解决:
- 存储容量受单机限制,即磁盘资源遭遇瓶颈。
- 读写能力受单机限制,可能是 CPU、内存或者网卡等资源遭遇瓶颈,导致读写能力无法扩展。
许多人对复制和分片之间的区别感到困惑。记住,复制在多台服务器上创建了数据的精确副本,因此每台服务器都是其他服务器的镜像。相反,每个分片包含了不同的数据子集。
1. 介绍
分片的目标之一是使由两个、3 个、10 个甚至数百个分片组成的集群对应用程序来说就像是一台单机服务器。为了对应用程序隐藏这些细节,需要在分片前面运行一个或多个称为 mongos 的路由进程。mongos 维护着一个“目录”,指明了哪个分片包含哪些数据。
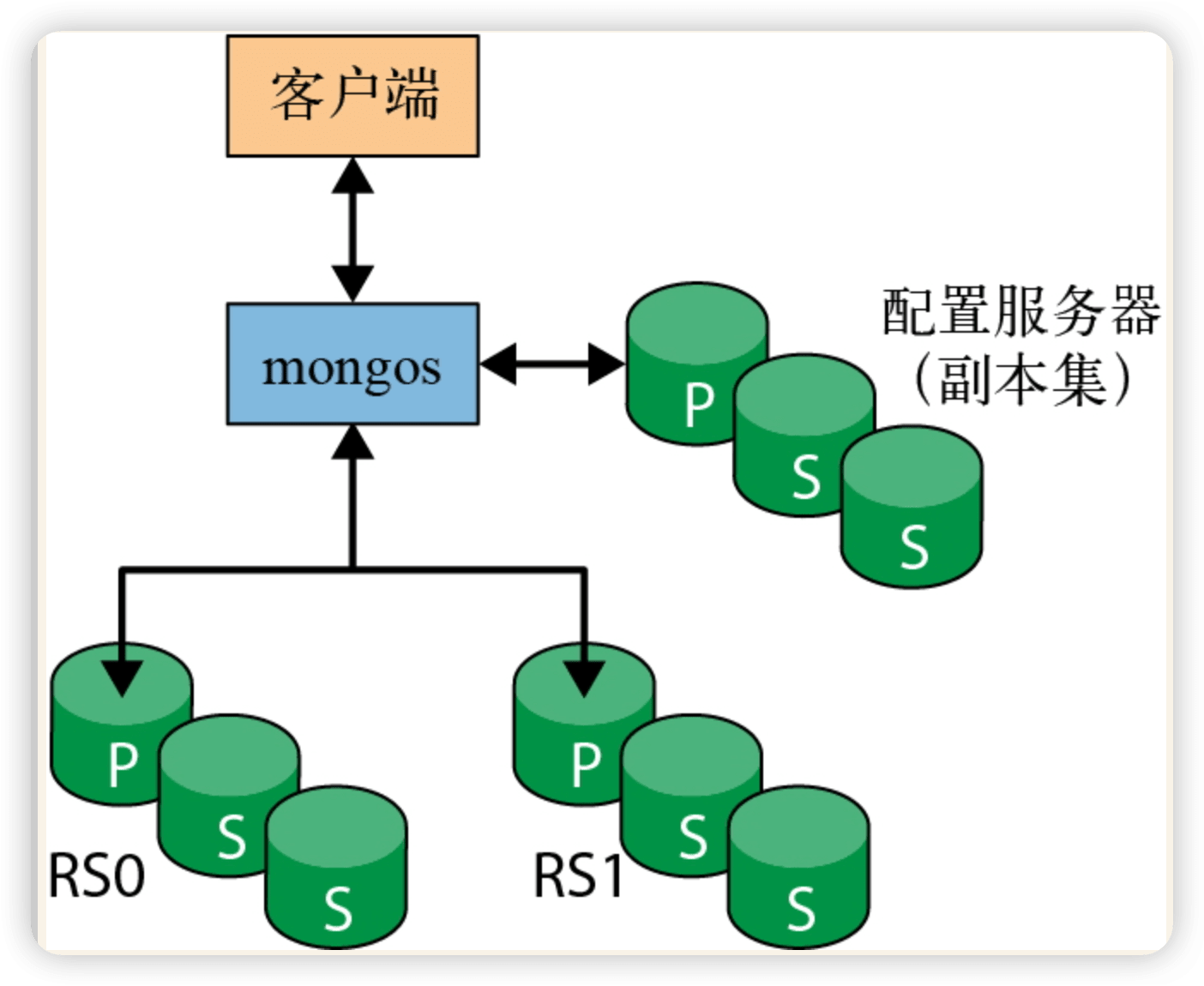
1.1 配置服务器
配置服务器是集群的大脑,保存着关于每个服务器包含哪些数据的所有元数据,因此,必须首先创建配置服务器。由于配置服务器所保存的数据非常重要,因此必须确保它在运行时启用了日志功能,并确保它的数据存储在非临时性的驱动器上。
在生产环境中,配置服务器副本集应该至少包含 3 个成员。每个配置服务器应该位于单独的物理机器上,这些机器最好是跨地理位置分布的。
配置服务器必须在任何一个 mongos 进程之前启动,因为 mongos 需要从这些进程中提取配置信息。首先,在 3 台不同的机器上运行以下命令来启动配置服务器:
1 | mongod --configsvr --replSet configRS --bind_ip localhost,198.51.100.51 mongod |
在 3 个配置服务器都运行后,启动一个 mongos 进程以供应用程序进行连接。mongos 进程需要知道配置服务器的地址,因此必须使用 –configdb 选项启动 mongos:
1 | mongos --configdb \ |
1.4 分块
当写操作发生时,一个块中的文档数量和大小可能会改变。插入操作可以使块包含更多的文档,删除操作则会使其包含更少的文档。如果这是给儿童和青少年制作的一款游戏,那么 3 岁到 17 岁的数据块可能会越来越大。一旦一个块增长到一定的大小,MongoDB 就会自动将它分成两个更小的块。
块与块之间的范围不能重叠,比如不能有 3 到 15 和 12 到 17 这样的块。如果可以重叠,那么当试图查找在重叠中的年龄时(如 14),MongoDB 就必须检查两个区块。只在一个地方查找会更高效,特别是当块已经分散在整个集群中时。
一个文档总是属于且仅属于一个块。这条规则意味着,不能使用数组字段作为片键,因为 MongoDB 会为数组创建多个索引项。如果一个文档的 “age” 字段为 [5, 26, 83],那么这个文档最多会出现在 3 个块中。
一个常见的误解是,同一个块的数据应保存在磁盘的同一片区域中。这是不正确的:块对 mongod 如何存储集合中的数据没有影响。
1.5 均衡器
均衡器负责数据的迁移。它会定期检查分片之间是否存在不均衡,如果存在,就会对块进行迁移。在 MongoDB 3.4 以上的版本中,均衡器位于配置服务器副本集的主节点成员上,而在 MongoDB 3.4 及之前的版本中,每个 mongos 会偶尔扮演“均衡器”的角色。
2. 分片操作
要对一个特定的集合进行分片,首先需要在集合的数据库上启用分片。如下所示,运行 enableSharding 命令:
1 | sh.enableSharding("accounts") |
在对集合进行分片时,需要选择一个片键(shard key)。片键是 MongoDB 用来拆分数据的一个或几个字段。如果选择在”username” 字段上分片,MongoDB 就会根据用户名的范围对数据进行拆分:”a1-steak-sauce” 到 “defcon”、”defcon1” 到”howie1998”,等等。
可以将选择一个片键看作为集合中的数据选择一个排列顺序。这与索引的概念类似,也十分合理:随着集合的增大,片键会成为集合中最重要的索引。只有创建了索引的字段才能够作为片键。
2.1 设置分片
因此,在启用分片之前,必须在想要分片的键上创建一个索引:
1 | db.users.createIndex({"username" : 1}) |
现在可以通过 “username” 来对集合进行分片了:
1 | sh.shardCollection("accounts.users", {"username" : 1}) |

2.2 查询操作
通常来说,如果在查询中没有使用片键,mongos 就不得不将查询发送到每个分片上。
包含片键并可以发送到单个分片或分片子集的查询称为定向查询(targeted query)。必须发送到所有分片的查询称为分散–收集查询(scatter-gather query),也称为广播查询:mongos 会将查询分散到所有分片,然后再从各个分片收集结果。
2.3 实战
1 | # 创建索引 |
3. 片键
在对集合进行分片时,需要选择一两个字段来对数据进行拆分。这个键(或这些键)称为片键。一旦对一个集合进行了分片,就不能更改片键了,因此正确选择片键是十分重要的。
3.1 片键策略
MongoDB 分片集群支持的分片策略
范围分片,支持基于 Shard Key 的范围查询。
哈希分片,能够将写入均衡分布到各个 shard。
要创建哈希片键,首先需要创建哈希索引:
1
2
3> db.users.createIndex({"username" : "hashed"})
> sh.shardCollection("app.users", {"username" : "hashed"})使用哈希片键有一些限制。首先,不能使用 unique 选项。其次,与其他片键一样,不能使用数组字段。最后注意,浮点型的值在哈希之前会被取整,因此 1 和 1.999 999 会被哈希为相同的值。
Tag aware sharding,您可以自定义一些 chunk 的分布规则。
范围分片和哈希分片无法解决的问题
Shard Key 的取值范围太小,例如将数据中心作为 Shard Key,由于数据中心通常不多,则分片效果不好。
Shard Key 中某个值的文档特别多,会导致单个 chunk 特别大(即 jumbo chunk),会影响 chunk 迁移及负载均衡。
根据非 Shard Key 进行查询、更新操作都会变成 scatter-gather 查询,影响效率。
好的 Shard Key 拥有的特性
key 分布足够离散(sufficient cardinality)
写请求均匀分布(evenly distributed write)
尽量避免 scatter-gather 查询(targeted read)
3.2 片键原则
- 部分静态表不需要分片
- 集合不为空,则需要先设置该片键的索引,再设置片键
- 集合为空,则可直接设置片键
- hashed 情况不支持复合片键
3.3 分片规范
如果使用
_id字段作为片键,禁止使用范围分片。
id 默认是一个递增的序列,随着数据量的增加会一直增大。如果_id作为片键并使用范围分片,集群随着数据的插入不断的进行 balance。分片表原则上必须携带片键进行查询
分片表不带片键进行查询,需要扫描所有分片后在 mongos 聚合结果,比较消耗性能,不推荐使用。分片集群禁止直连 mongod 节点写数据
分片集群应该通过 mongos 写数据,直接通过 mongod 写入的数据无路由信息,会导致访问不到。
3.4 示例
某物联网应用使用 MongoDB 分片集群存储海量设备的工作日志。如果设备数量在百万级别,设备每 10 秒向 MongoDB 汇报一次日志数据,日志包含设备 ID(deviceId)和时间戳(timestamp)信息。应用最常见的查询请求是查询某个设备某个时间内的日志信息。
查询请求:查询某个设备某个时间内的日志信息。
- (推荐)方案一:组合设备 ID 和时间戳作为 Shard Key,进行范围分片。
- 写入能均分到多个 shard。
- 同一个设备 ID 的数据能根据时间戳进一步分散到多个 chunk。
- 根据设备 ID 查询时间范围的数据,能直接利用(deviceId,时间戳)复合索引来完成。
- 方案二: 时间戳作为 Shard Key,进行范围分片。
- 新的写入为连续的时间戳,都会请求到同一个分片,写分布不均。
- 根据设备 ID 的查询会分散到所有 shard 上查询,效率低。
- 方案三: 时间戳作为 Shard Key,进行哈希分片。
- 写入能均分到多个 shard 上。
- 根据设备 ID 的查询会分散到所有 shard 上查询,效率低。
- 方案四:设备 ID 作为 Shard Key,进行哈希分片。(如果设备 ID 没有明显的规则,可以进行范围分片)
- 写入能均分到多个 shard 上。
- 同一个设备 ID 对应的数据无法进一步细分,只能分散到同一个 chunk,会造成 jumbo chunk,根据设备 ID 的查询只请求到单个 shard,请求路由到单个 shard 后,根据时间戳的范围查询需要全表扫描并排序。

